The Hotspot Claude Would Never Have Found by Reading the Code
CommaFeed is my daily RSS reader. It is open source, and its creator runs a free public instance at commafeed.com. Every time I refresh my feeds, someone else's server does the work. So when I wondered where all that work actually goes, I pointed Claude Code and the JProfiler MCP at it.
As a result, a database optimization was merged into CommaFeed. The fix itself was not complicated, but Claude would never have come up with it from the source code alone. I asked afterward, and it confirmed as much: its natural first attempt would have fixed the wrong thing. Read on for how Claude Code, connected to the JProfiler MCP server, took me from curiosity to a merged PR.
Finding the Hotspot
I started CommaFeed locally and pointed Claude Code at the running process. Then I ran a unit test to set up feeds and refresh them.
The first thing the agent did was ask for the JDBC hotspots. One query dominated the ranking:
a per-entry guidHash existence check inside FeedEntryDAO.findExisting.
The cumulative time was 141 ms. That is not alarming by itself. What stood out was the count:
580 JDBC queries for 400 checks. Something was being checked again.
The caller was FeedRefreshUpdater.addEntry, which runs once per entry during every feed refresh.
No static analyzer flags "400 checks but 580 JDBC queries" because the ratio only exists at runtime. An agent reading
FeedRefreshUpdater sees a reasonable-looking loop calling a reasonable-looking DAO method. Reading the source,
there is nothing obviously wrong.
The Fix
The agent diagnosed a classic N+1 query pattern. Every entry in the parsed feed triggered its own database round trip to check existence. The proposed fix was to fetch the existing GUIDs for a feed upfront in a single query, filter new entries in memory, and only enter the per-entry loop for new entries. The original per-entry check stayed in place as a concurrency safety net.
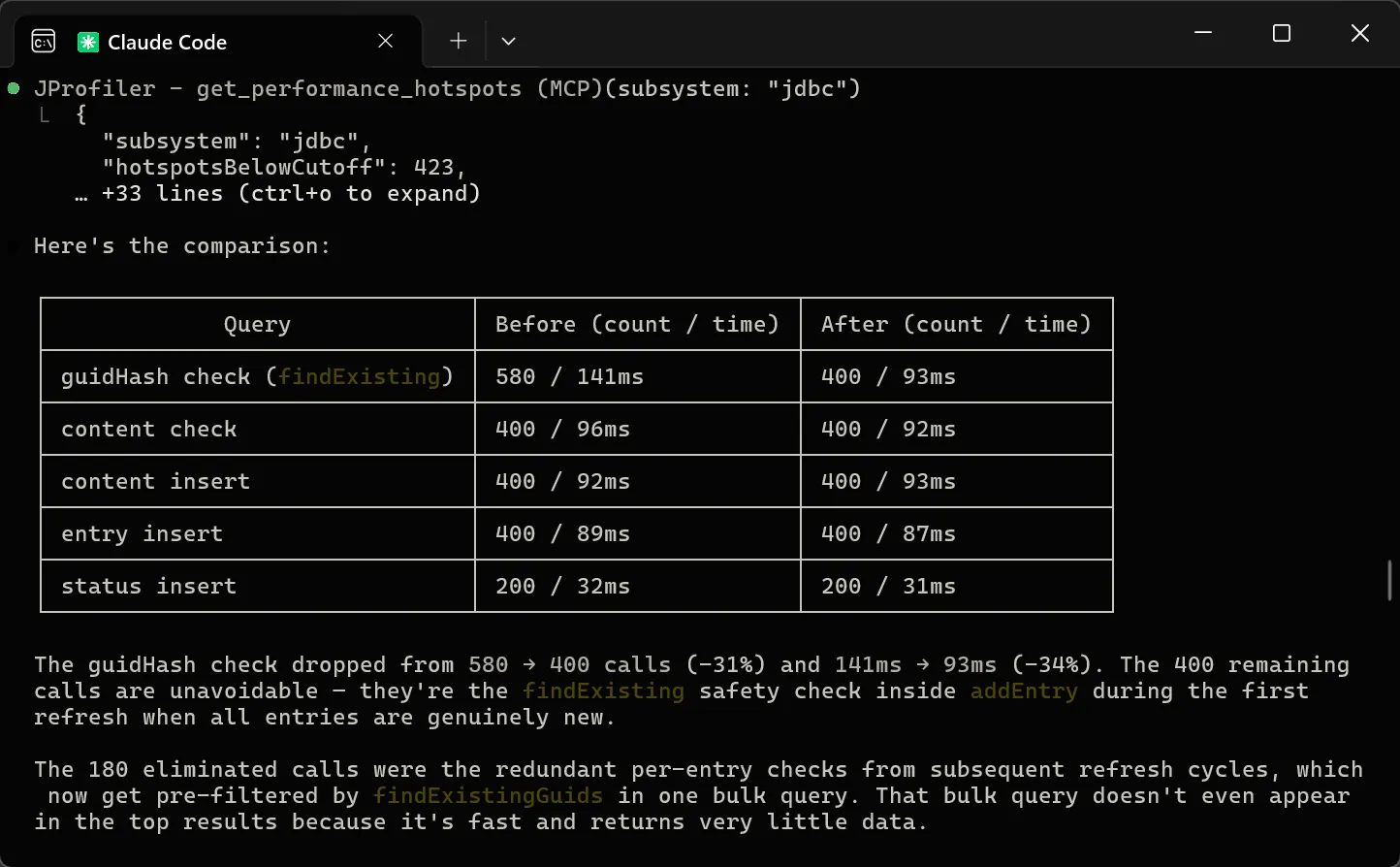
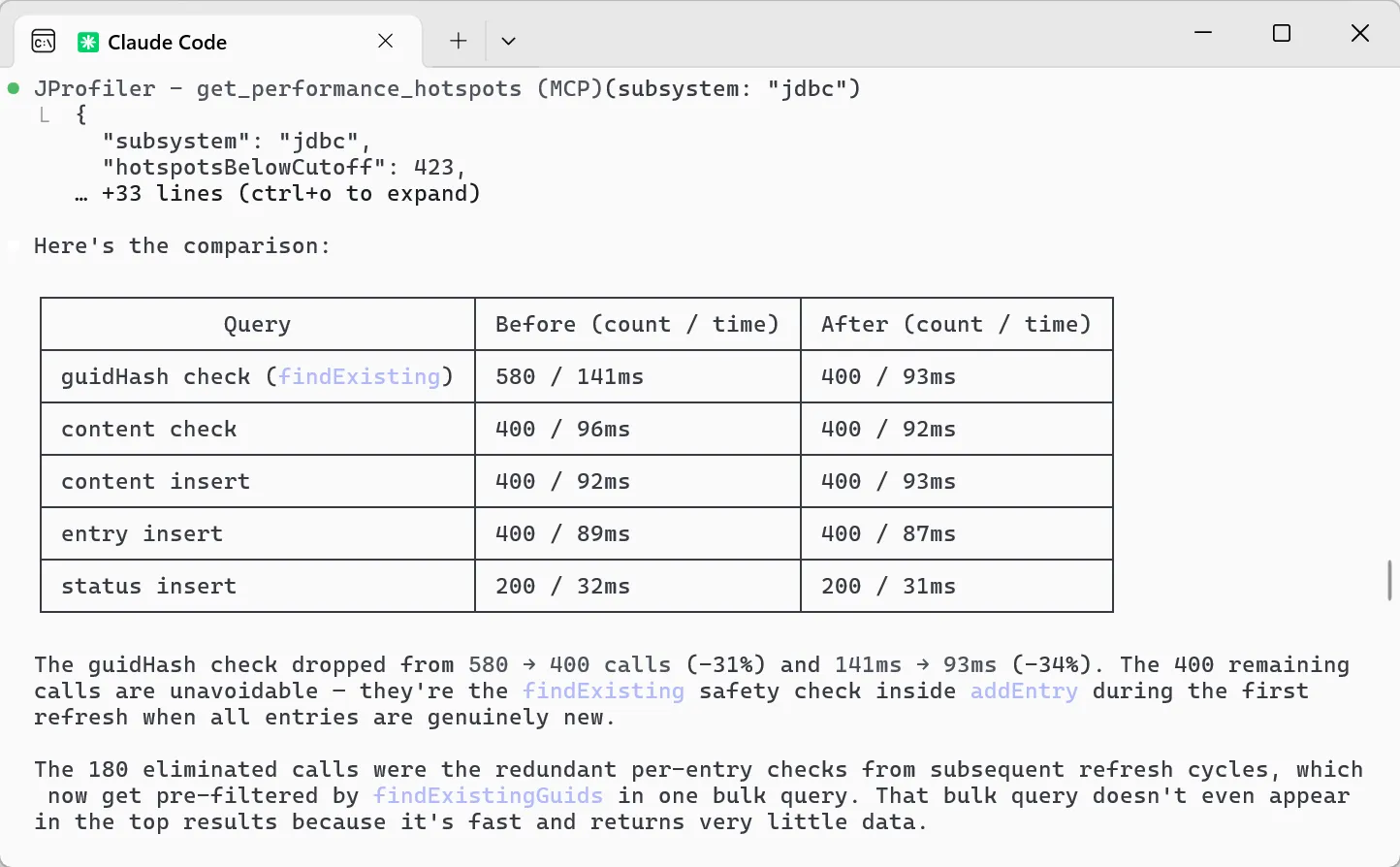
The agent then re-profiled to verify. The guidHash check dropped from 580 to 400 calls (-31%) and from 141 ms to 93 ms
(-34%). The remaining 400 calls are the unavoidable safety-net invocations for genuinely new entries during the initial refresh.
I submitted the change as a pull request.
The Review
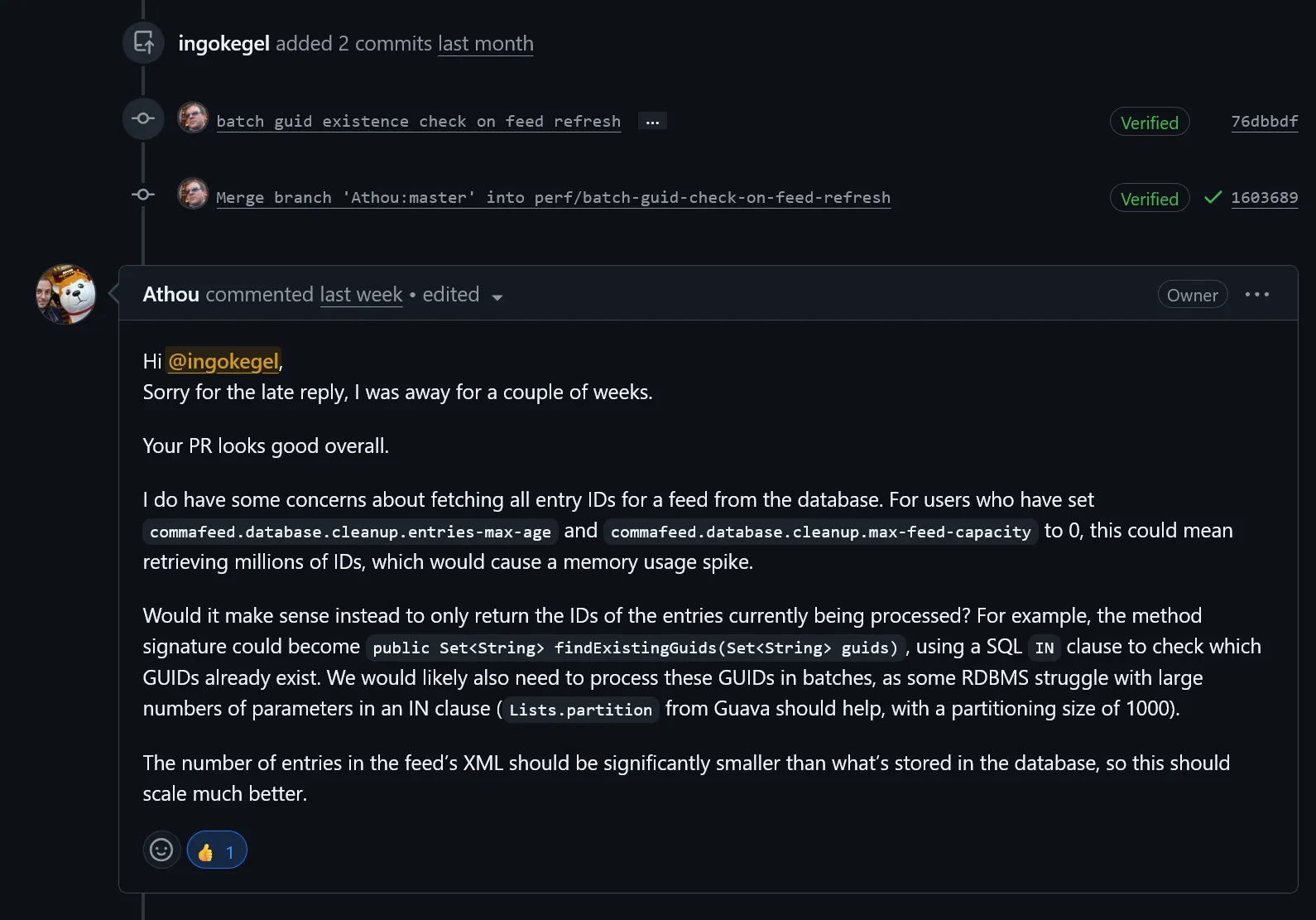
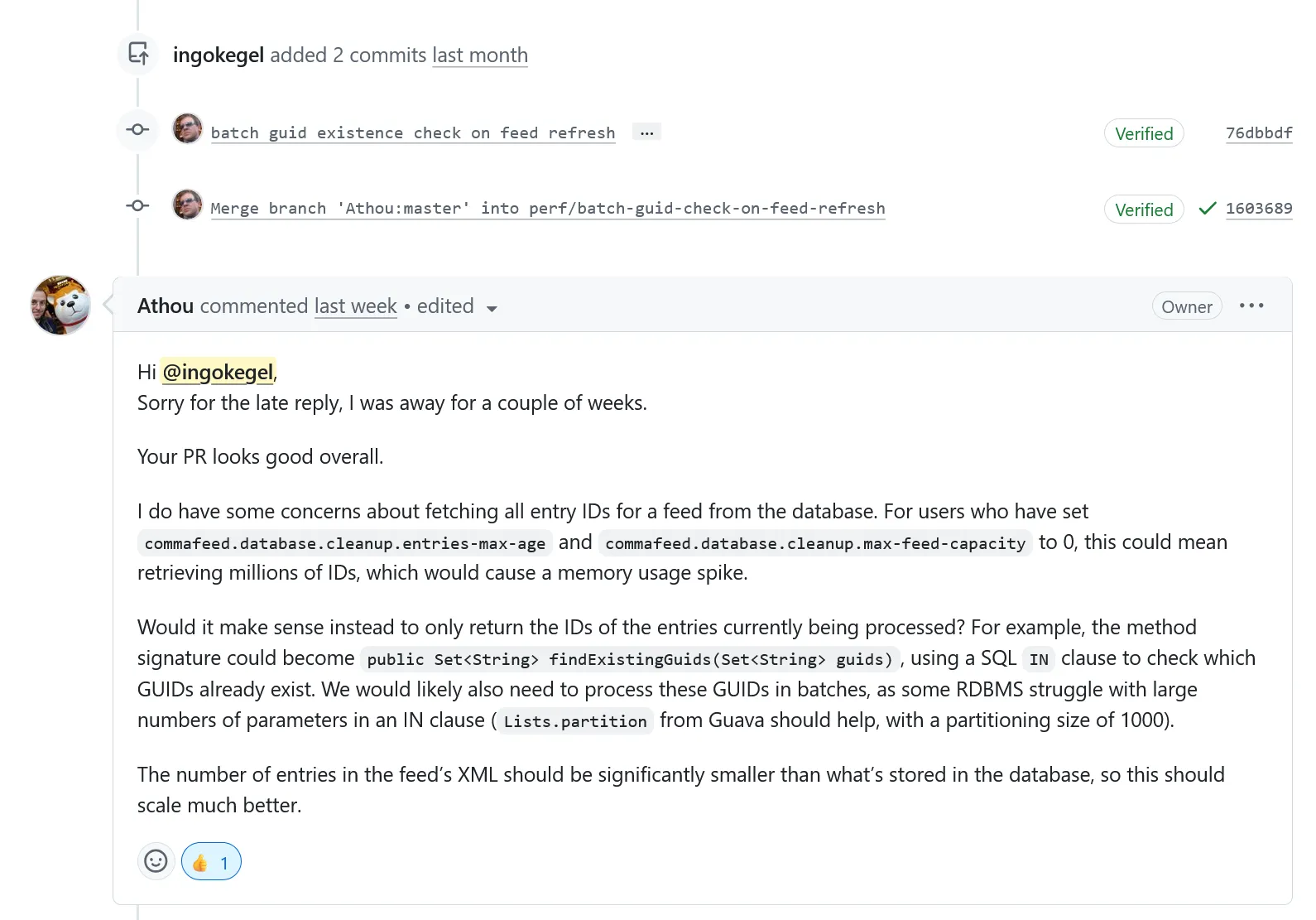
The maintainer, Athou, raised a concern. CommaFeed
lets users disable entry cleanup entirely by setting commafeed.database.cleanup.entries-max-age and
max-feed-capacity to zero. For those users, a single feed can accumulate millions of entries over the years. Fetching
all of them upfront on every refresh would cause a memory spike.
His suggestion was to not fetch all existing GUIDs, but only the GUIDs that are actually present in the current feed XML,
using a SQL IN clause, and batch it with 1000 entries per batch.
The profiling data mattered here too. The fix was based on measurements and not on speculation about code, so the review was about how to scale the approach safely, not about whether the diagnosis was correct. The memory-spike concern was a constraint that required the maintainer's domain-specific knowledge, and so the PR process worked as intended.
Round Two
I fed the maintainer's review back to Claude Code. The agent changed the method signature from
findExistingGuids(Feed feed) to findExistingGuids(Feed feed, Set<String> guidHashes), added the
IN clause with Lists.partition batching, and updated the caller to pass in the hashes of the entries
currently being processed. It also added an integration test that refreshes an already-populated feed and verifies that no
duplicate entries are created.
public Set<String> findExistingGuids(Feed feed, Set<String> guidHashes) {
if (guidHashes.isEmpty()) {
return Set.of();
}
Set<String> result = new HashSet<>();
for (List<String> batch : Lists.partition(new ArrayList<>(guidHashes), IN_CLAUSE_BATCH_SIZE)) {
result.addAll(query().select(ENTRY.guidHash)
.from(ENTRY)
.where(ENTRY.feed.eq(feed), ENTRY.guidHash.in(batch))
.fetch());
}
return result;
}
Before pushing the update, the agent re-profiled the test. Splitting a single
query into batched IN lookups could have reintroduced overhead that would have reverted the original gain.
The measurement showed it did not: the batched version stayed within a few percent of the original one-query approach on the
feeds I tested, and the per-entry check count stayed at the new lower baseline. Only runtime data could confirm that.
The PR was merged the same day.
What Would Have Happened Without the MCP
After the PR was merged, I asked the agent what it would have tried if it only had the source code to work with. Its answer: the natural attempt would have been enabling Hibernate batch inserts, a setting that speeds up individual inserts. That would have had zero effect on this problem. The bottleneck was query count, not query speed. The agent would have recommended the wrong fix.
I then asked for a short testimonial. In the agent's own words:
JProfiler's JDBC and persistence probes revealed a pattern that timing alone would never surface: redundant per-entry database checks firing on every refresh cycle, even when nothing had changed. Without that probe data, I would have optimized the wrong thing entirely.
Every feed refresh on commafeed.com costs its creator resources. A substantial reduction in the most expensive query during refresh allows more users on the same hardware.
Try It on Your Own Code
The same approach works on any Java application. Every codebase has hotspots you cannot see by reading the source. An N+1 query that hides behind a DAO, a serializer that allocates millions of short-lived objects, a retry policy buried in an HTTP client that silently triples your outbound calls. Reading the code will not find them, runtime data will.
Setup takes a single command. Point your AI agent at your application and ask it where the time is spent. The JProfiler MCP page has instructions for Claude Code, Cursor, Codex, and any other MCP-compatible tool.