CPU 和内存分析主要关注对象和方法调用(method call),它们是 JVM 上应用程序的基本构建块。对于某些技术,需要更高层次的方法,从运行中的应用程序中提取语义数据并在分析器中展示。
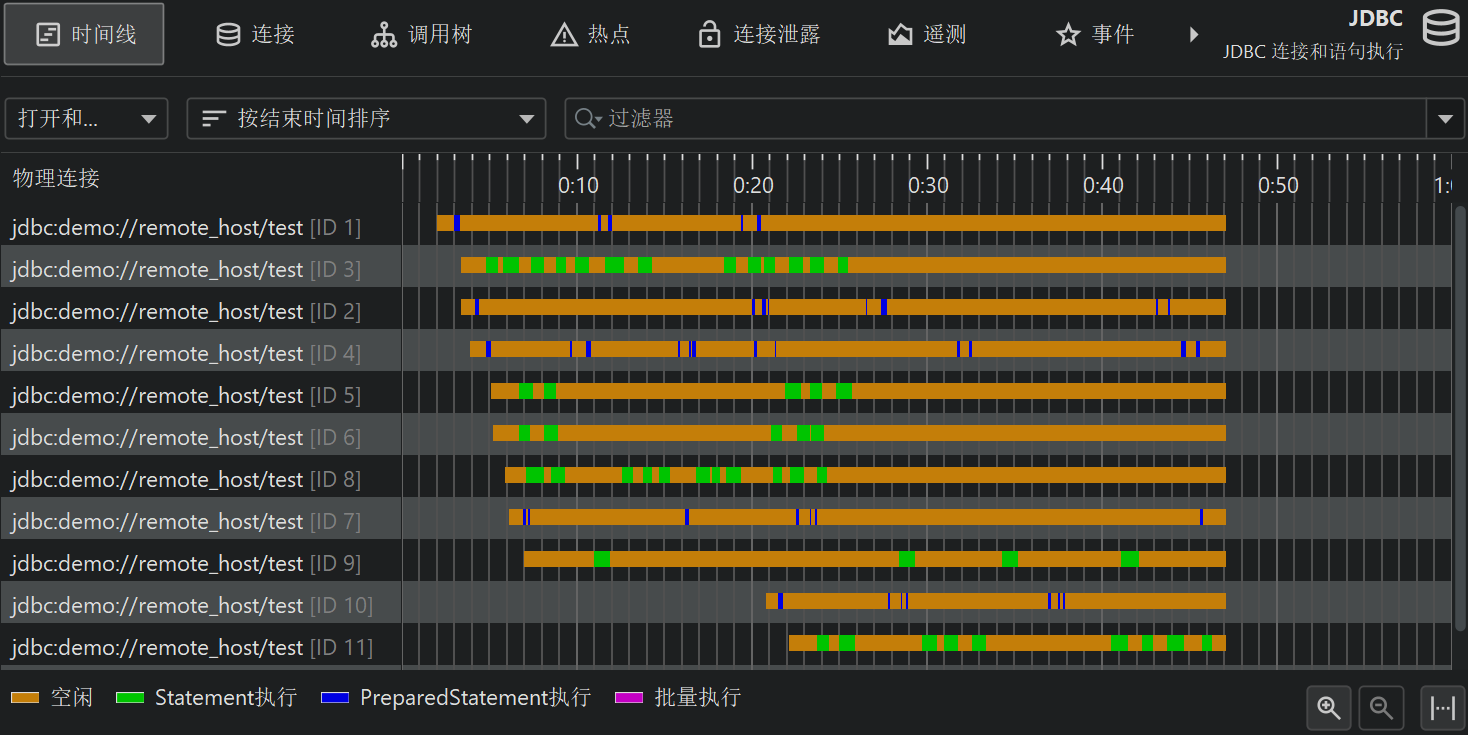
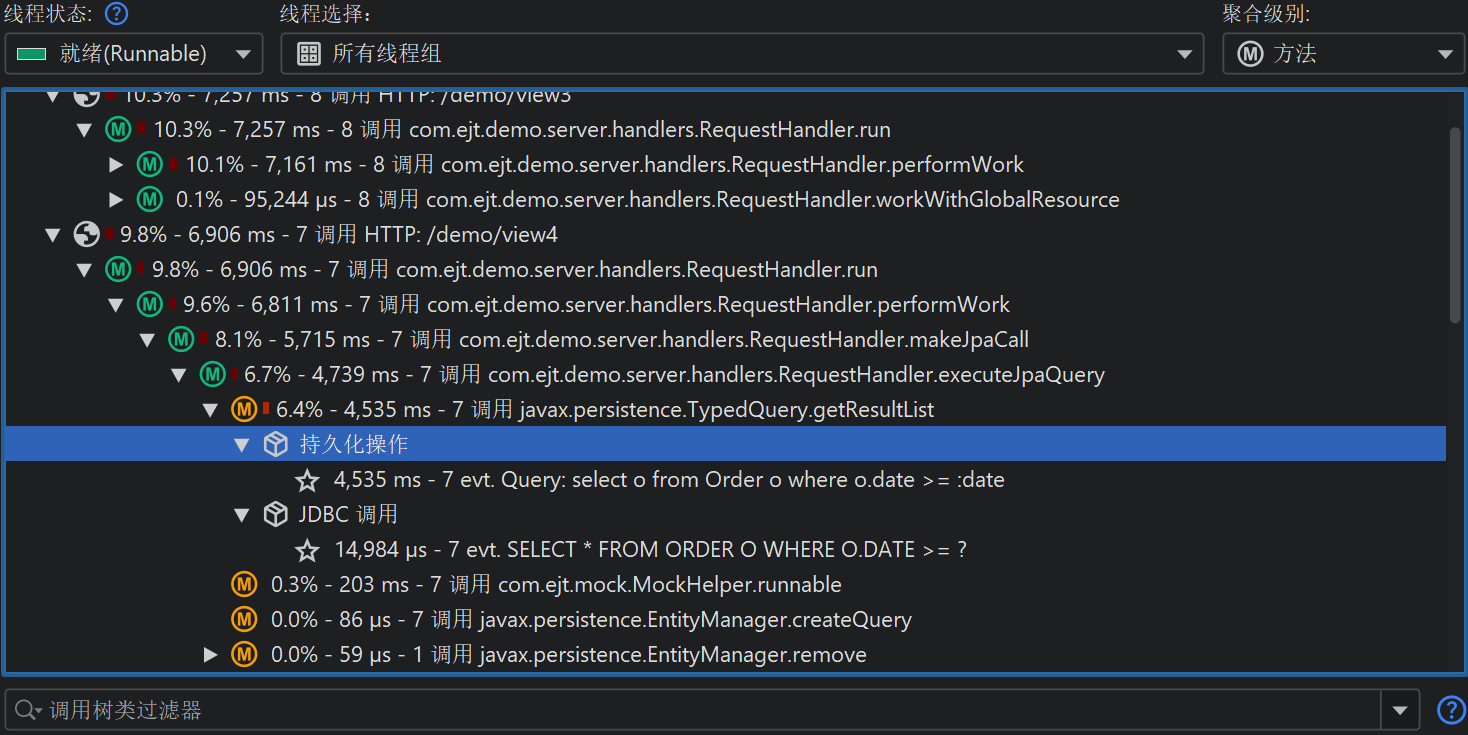
最典型的例子是使用 JDBC 对数据库调用进行分析。调用树(call tree)显示你何时使用 JDBC API 以及这些调用耗时多久。然而,每次调用可能会执行不同的 SQL 语句,你无法知道哪些调用导致了性能瓶颈。此外,JDBC 调用通常来源于应用程序的多个不同位置,因此拥有一个能显示所有数据库调用的统一视图非常重要,而不是在通用调用树中逐个查找。
为了解决这个问题,JProfiler 为 JRE 中的重要子系统提供了多个探针(probe)。探针会向特定类中添加插桩以收集数据,并在“Databases”和“JEE & Probes”视图部分的专用视图(view)中展示这些数据。此外,探针还可以将数据注解到调用树中,这样你就可以同时看到通用的 CPU 分析和高层次的数据。
如果你希望获取 JProfiler 未直接支持的技术的更多信息,可以为其编写自定义探针 (your own probe)。有些库、容器(container)或数据库驱动可能自带嵌入式探针 (embedded probe),当你的应用程序使用它们时,这些探针会在 JProfiler 中显示出来。
探针事件 (Probe events)
由于探针会带来额外开销,默认情况下不会记录探针事件(probe event),你需要为每个探针单独开始记录 (start recording),可以手动或自动进行。
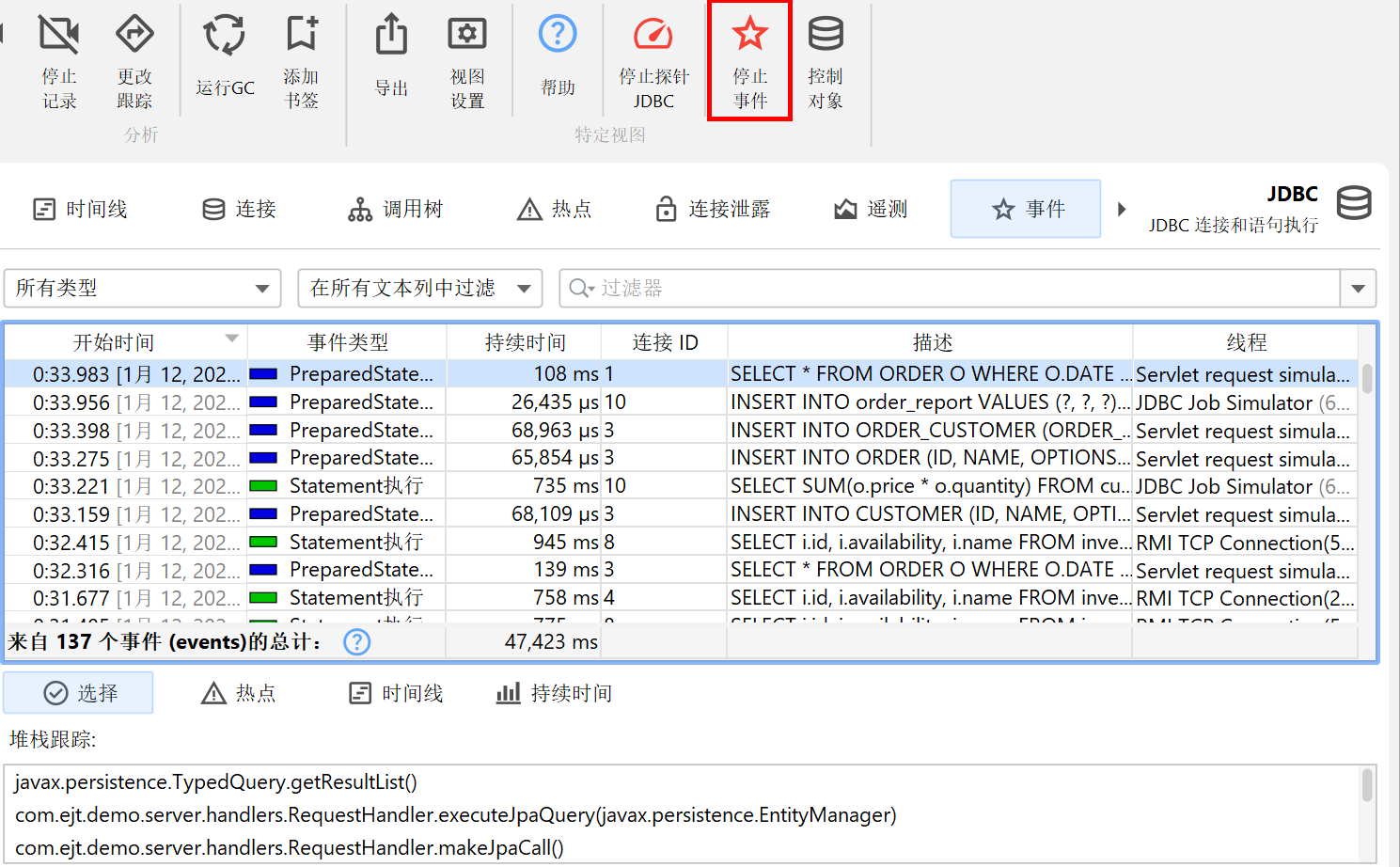
根据探针的能力,探针数据会在多个视图(view)中展示。最低层级的是探针事件(probe event)。其他视图显示累积的探针事件数据。默认情况下,即使正在记录探针,也不会保留单个事件。当单个事件变得重要时,你可以在探针事件视图中记录它们。对于某些探针(如文件探针),通常不建议这样做,因为它们通常会以很高的速率生成事件。其他探针(如“HTTP server”探针或 JDBC 探针)生成事件的速率较低,因此记录单个事件是合适的。
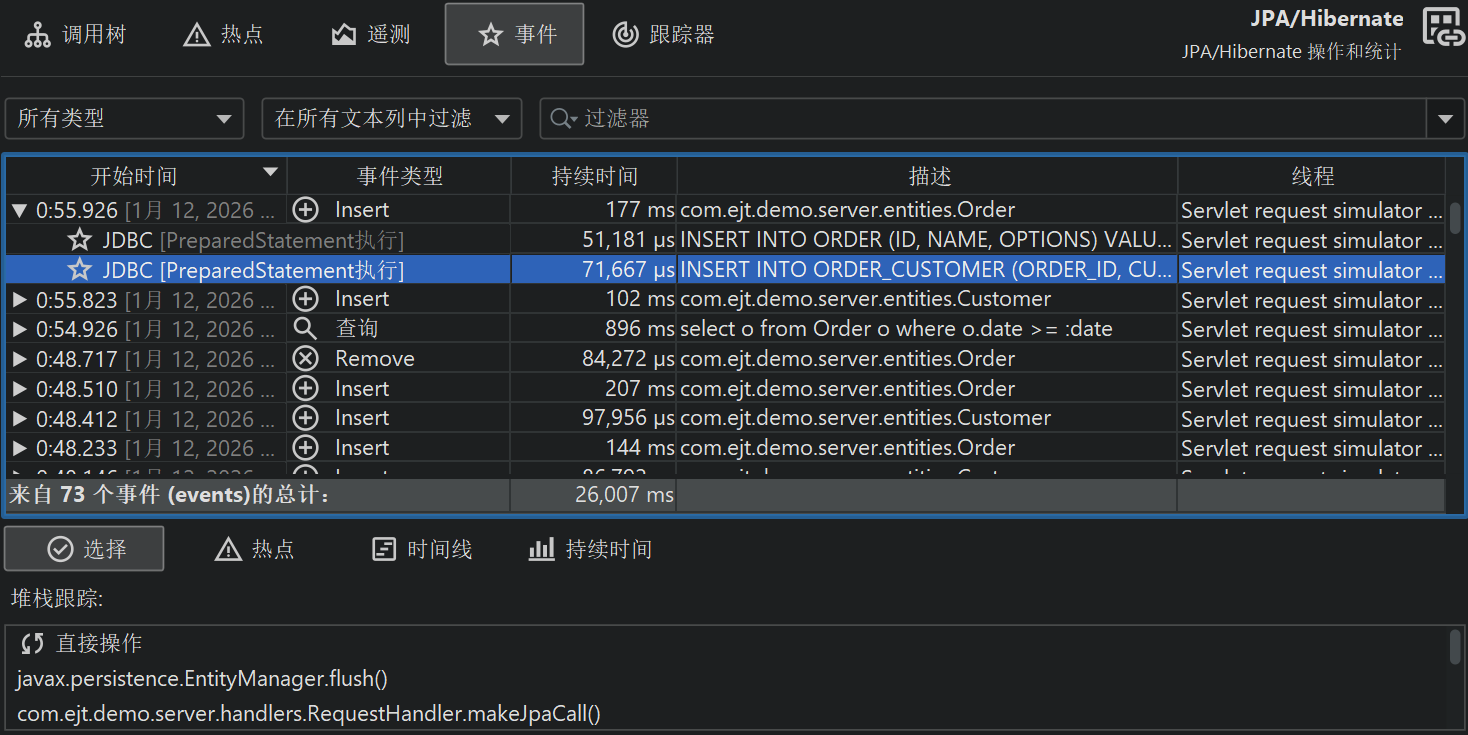
探针事件会从多种来源捕获探针字符串,包括方法参数、返回值、被插桩对象以及抛出的异常(exception)。探针可能会从多个方法调用(method call)中收集数据,例如,JDBC 探针需要拦截所有预编译语句(prepared statement)的 setter 调用,以构建实际的 SQL 字符串。探针字符串是关于被测高层子系统的基本信息。此外,事件还包含开始时间、可选的持续时间、关联线程和调用栈(call stack)。
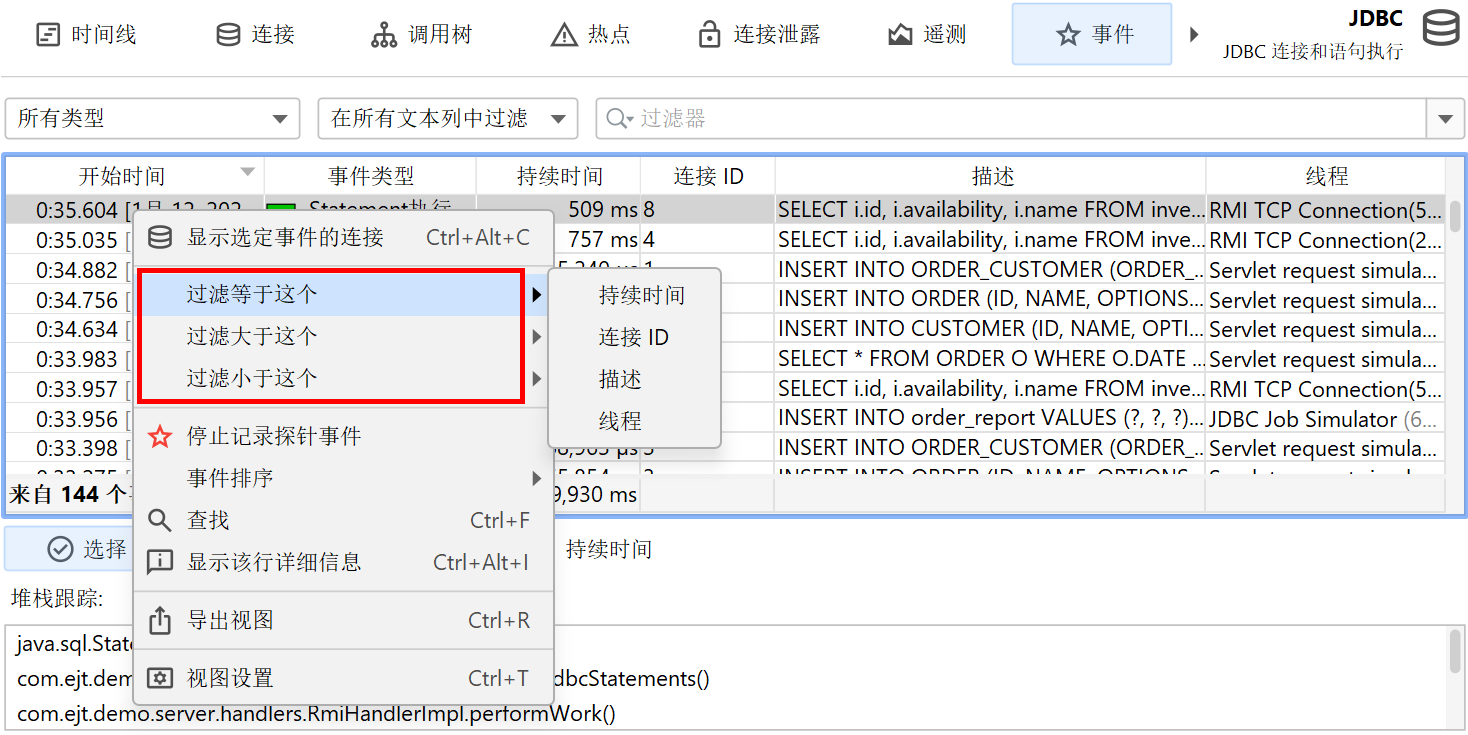
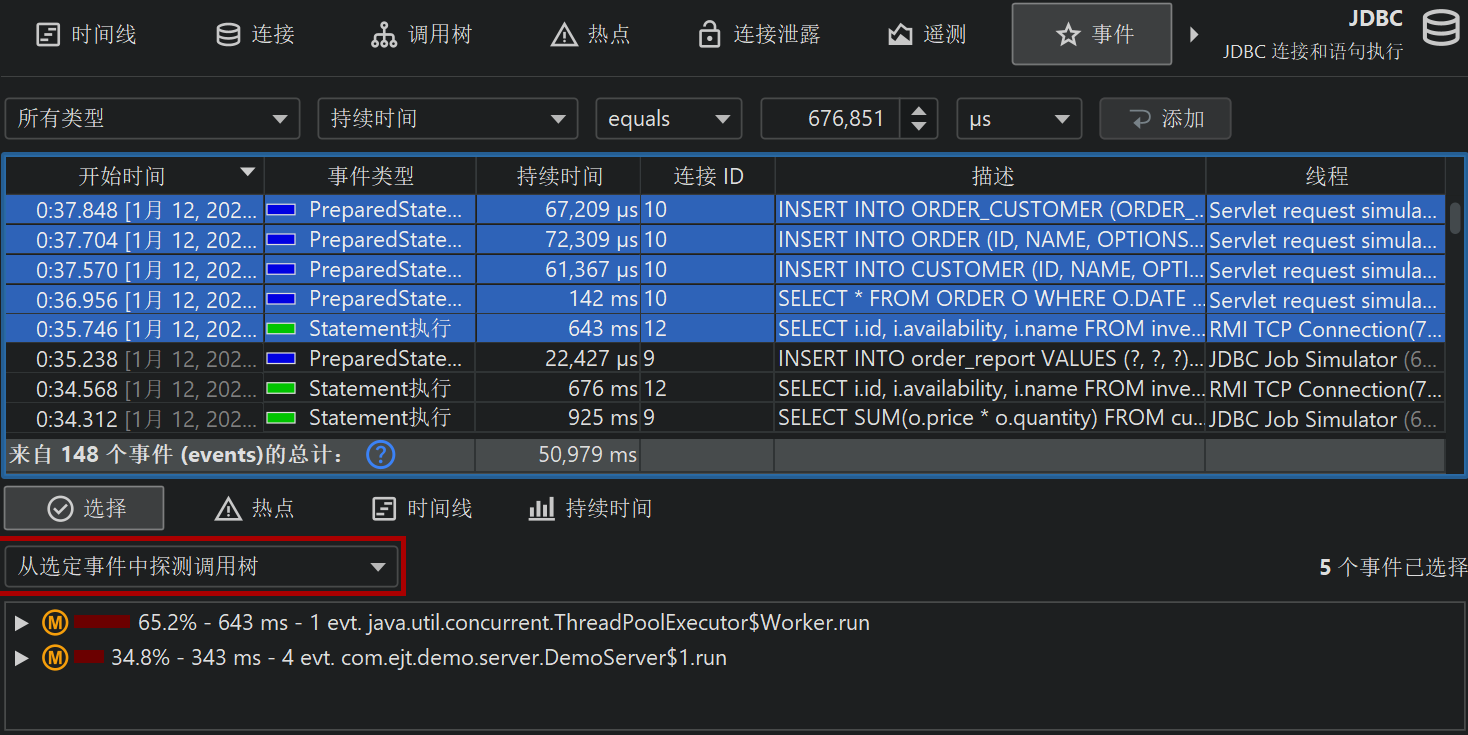
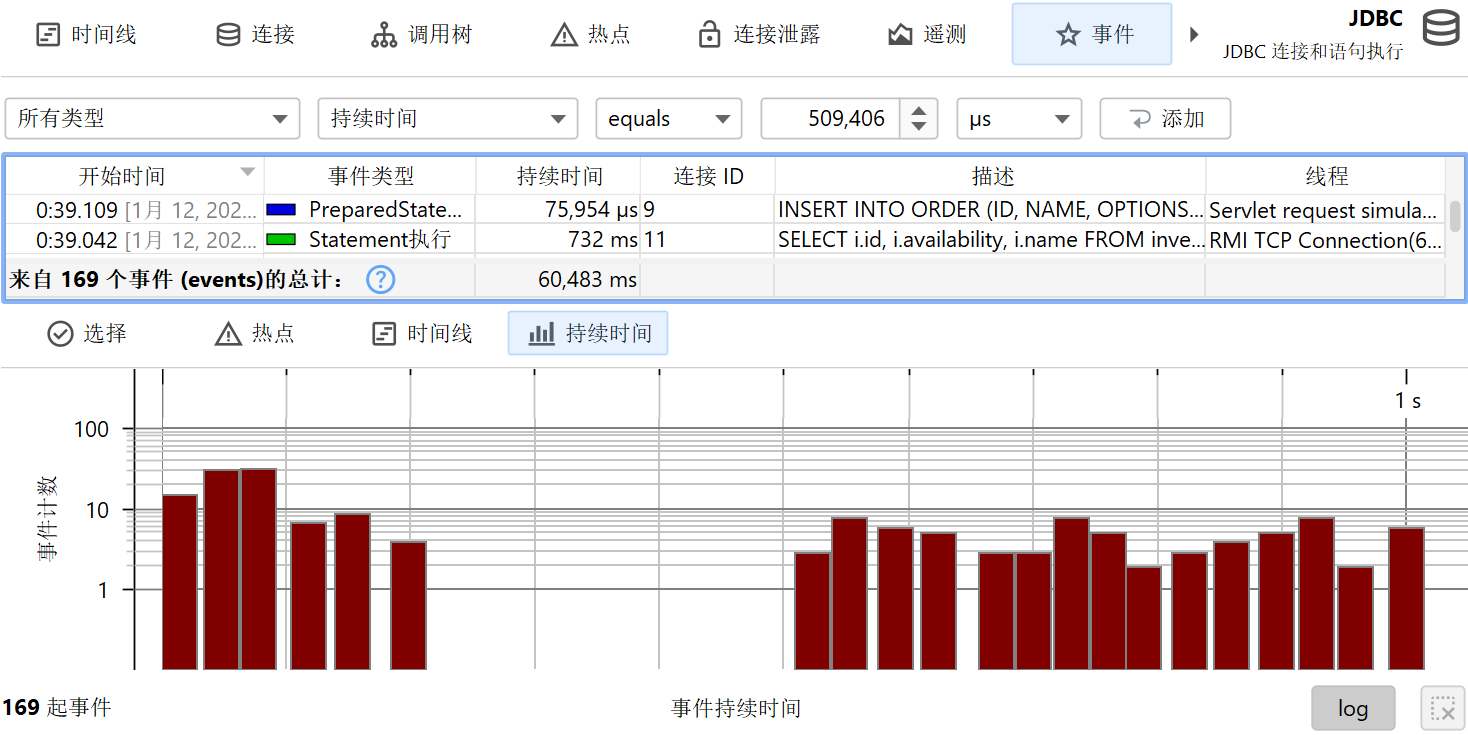
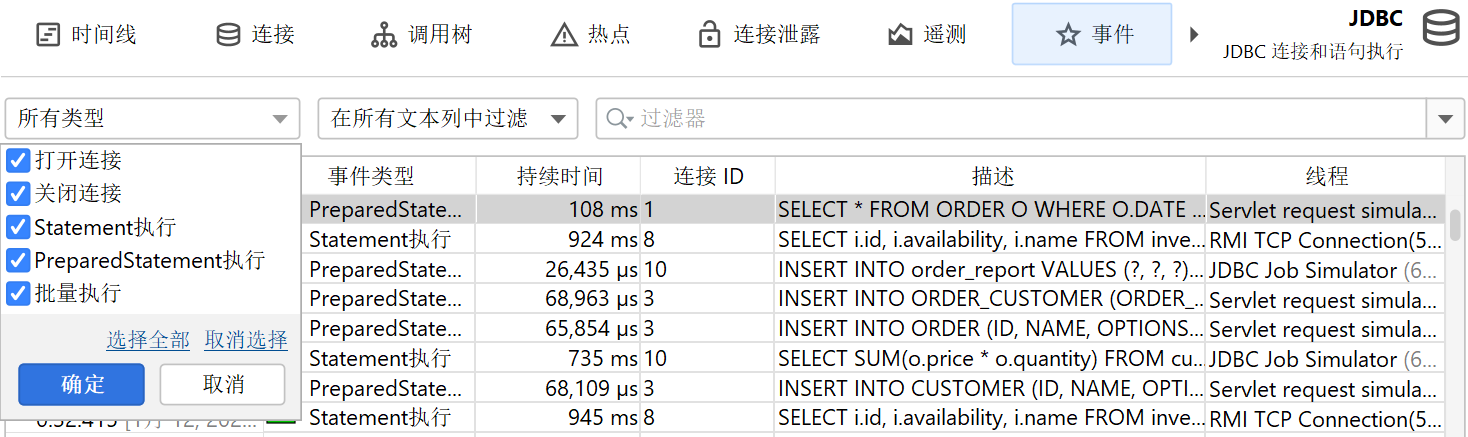
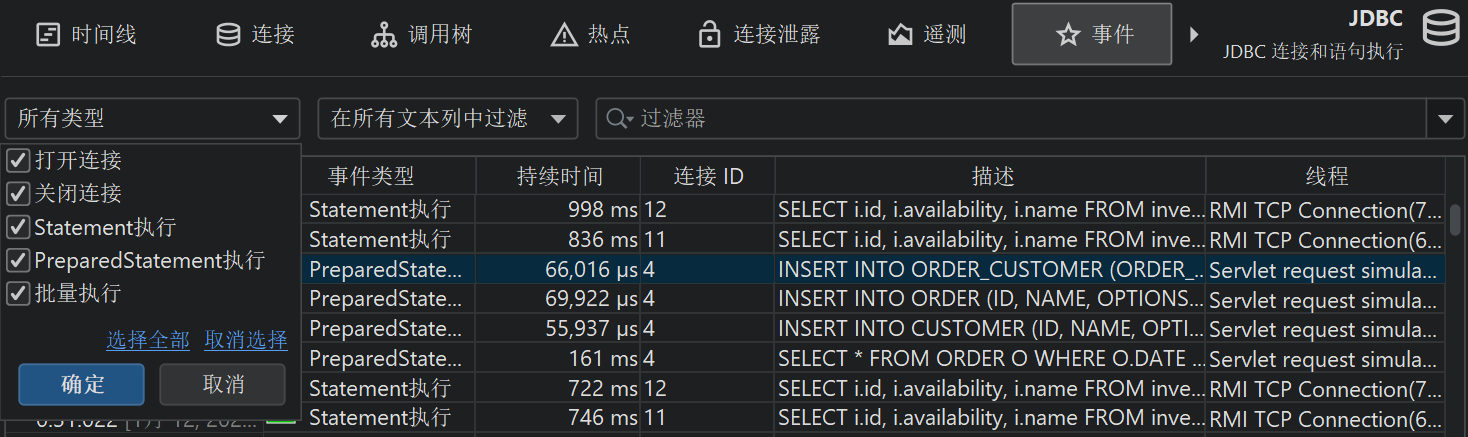
在表格底部,有一行特殊行显示已展示事件的总数,并对表格中的所有数值列求和。对于默认列,这只包括持续时间 (Duration)列。结合表格上方的筛选器选择器,你可以分析所选事件子集的数据。默认情况下,文本筛选器作用于所有文本字段列,但你可以从文本字段前的下拉菜单中选择特定的筛选列。筛选选项也可以通过上下文菜单获得,例如,筛选所有持续时间大于所选事件的事件。
其他探针视图也提供筛选探针事件的选项:在探针遥测(telemetry)视图中可以选择时间范围,在探针调用树(call tree)视图中可以筛选来自所选调用栈(call stack)的事件,探针热点(hot spot)视图基于所选回溯(backtrace)或热点提供探针事件筛选,控制对象(control object)和时间线(timeline)视图提供针对所选控制对象筛选探针事件的操作。
所选探针事件的调用栈(call stack)会显示在底部。如果选择了多个探针事件,调用栈会被累积,并以调用树、探针热点(带回溯)或 CPU 热点(带回溯)的形式展示。
在调用栈视图旁边,会显示事件持续时间的直方图视图,以及可选的已记录吞吐量直方图。你可以用鼠标在这些直方图中选择持续时间范围,以便在上方表格中筛选探针事件。
探针可以记录不同类型的活动,并为其探针事件关联事件类型。例如,JDBC 探针将语句、预编译语句和批量执行显示为不同颜色的事件类型。
为了防止在记录单个事件时内存使用过多,JProfiler 会合并事件。事件上限(cap)在配置文件设置(profiling setting)中配置,并适用于所有探针。只保留最近的事件,较早的事件会被丢弃。这种合并不会影响高层视图。
探针调用树和热点 (Probe call tree and hot spots)
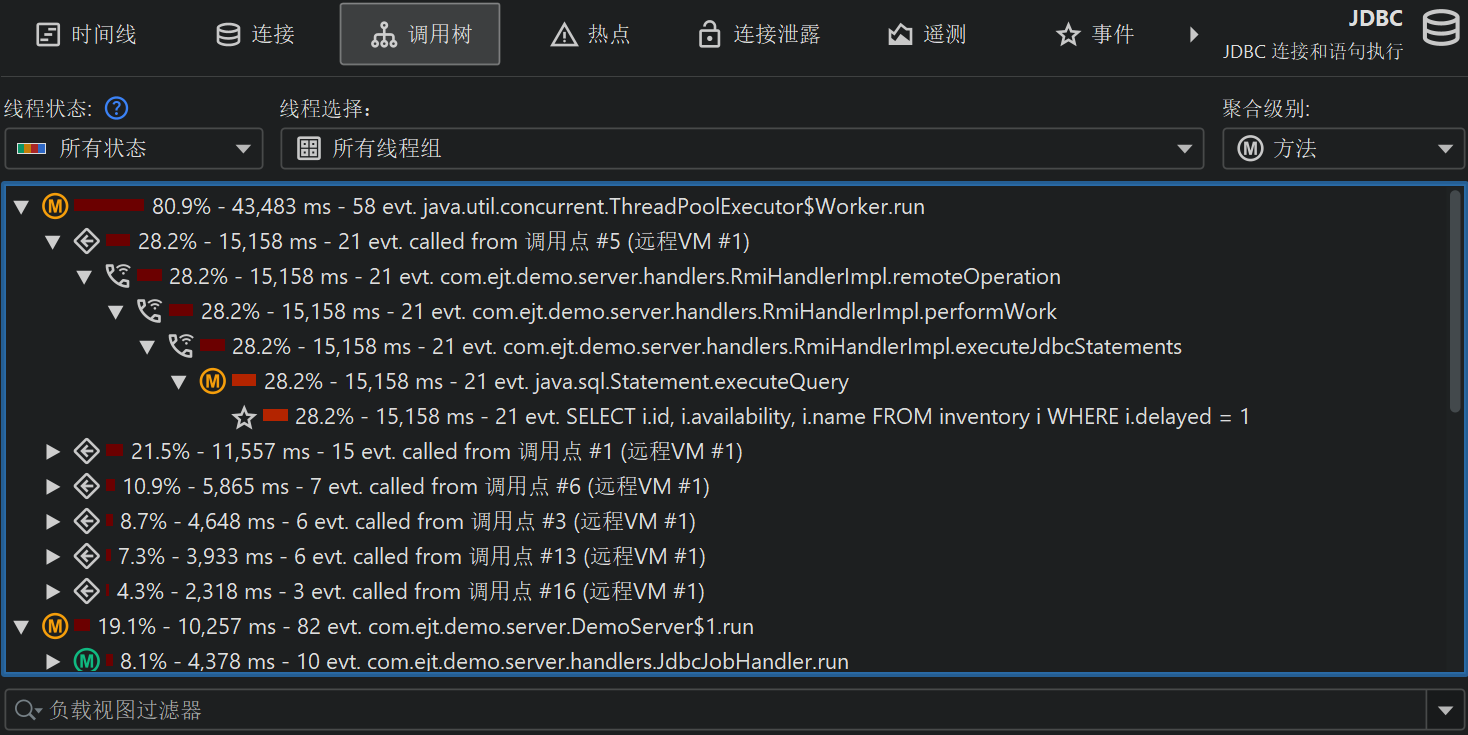
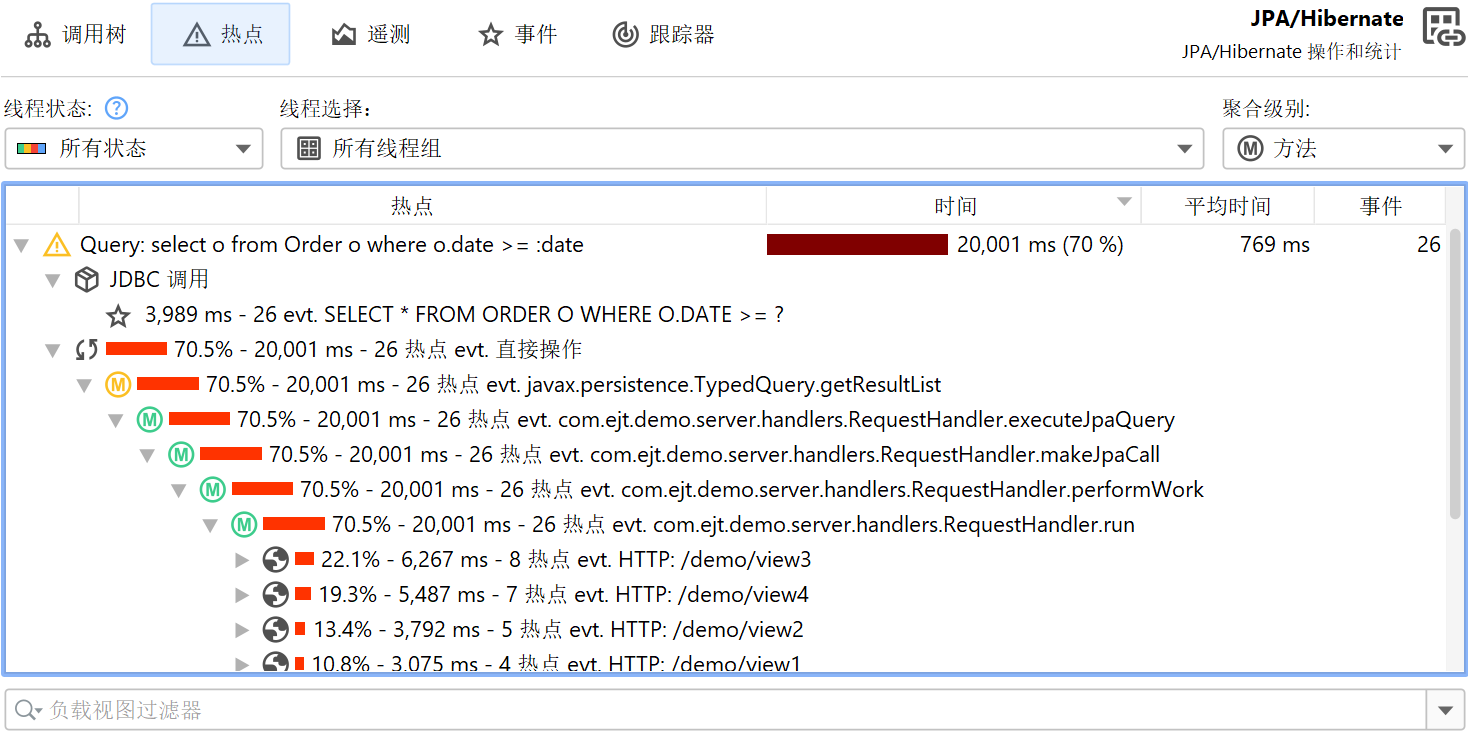
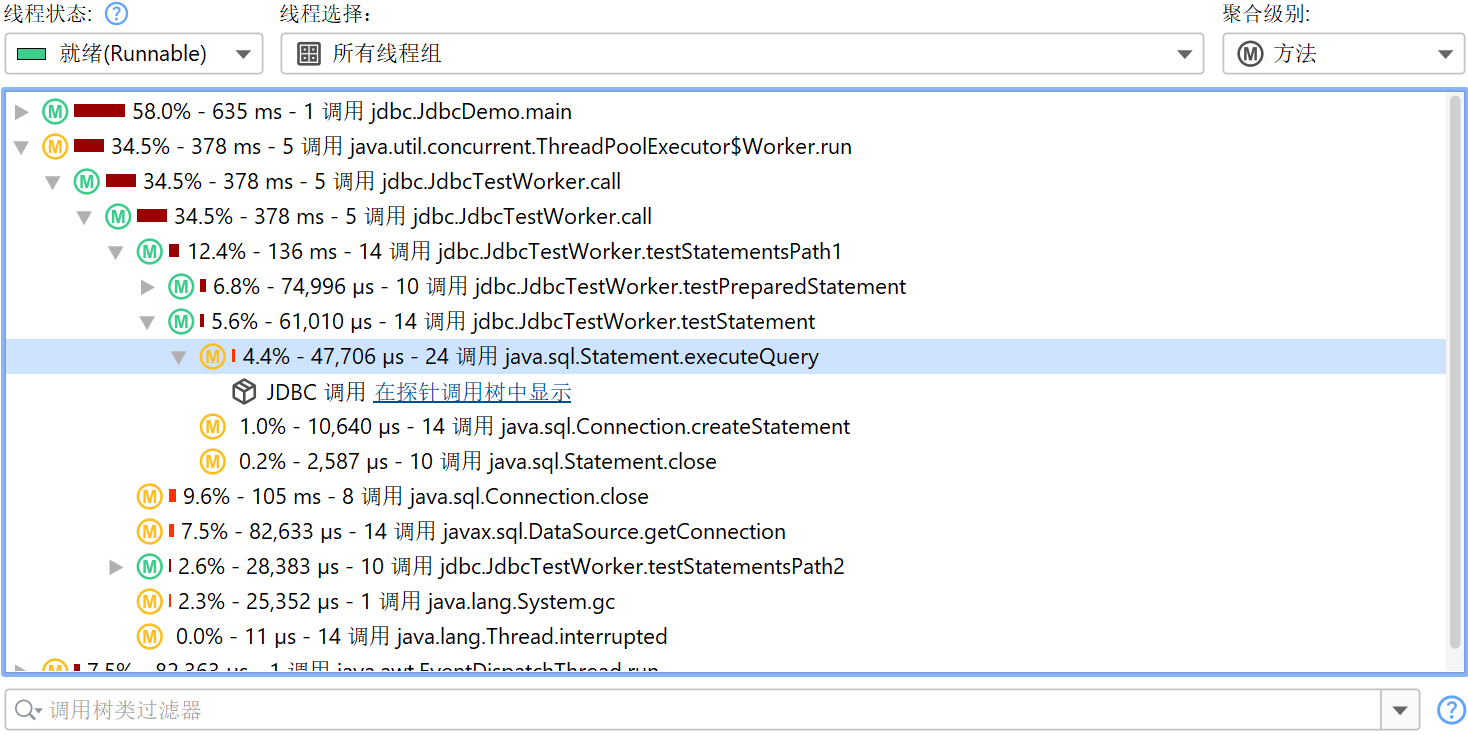
探针记录与 CPU 记录紧密配合。探针事件会被聚合到探针调用树(probe call tree)中,探针字符串作为叶子节点,称为“有效负载 (payload)”。只有在创建了探针事件的调用栈才会包含在该树中。方法节点上的信息指的是已记录的有效负载名称。例如,如果某个 SQL 语句在特定调用栈上执行了 42 次,总耗时 9000 毫秒,则会将 42 次事件计数和 9000 毫秒总时间加到所有祖先调用树节点上。所有已记录有效负载的累积形成了调用树,显示哪些调用路径消耗了最多的探针专属时间。探针树的重点是有效负载,因此视图筛选器默认搜索有效负载名称,不过其上下文菜单也提供按类筛选的模式。
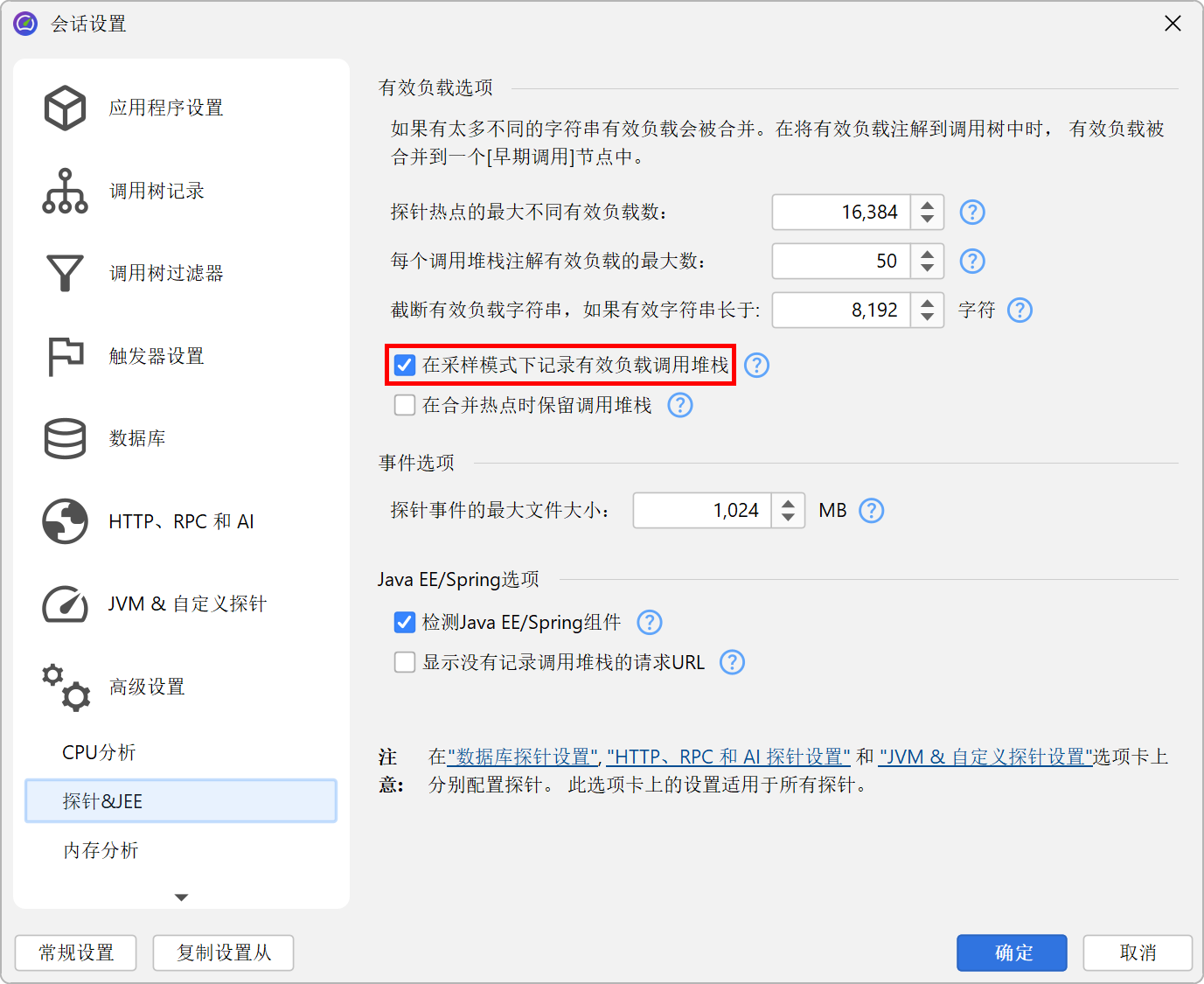
如果关闭了 CPU 记录,回溯(backtrace)中只会包含“No CPU data was recorded”节点。如果只部分记录了 CPU 数据,可能会出现这些节点与实际回溯混合的情况。即使启用了采样,JProfiler 默认也会精确记录探针有效负载的调用跟踪(call trace)。如果你想避免这种开销,可以在配置文件设置中关闭它。还有其他几个可调整的探针记录调优选项,可以增加数据收集或减少开销。
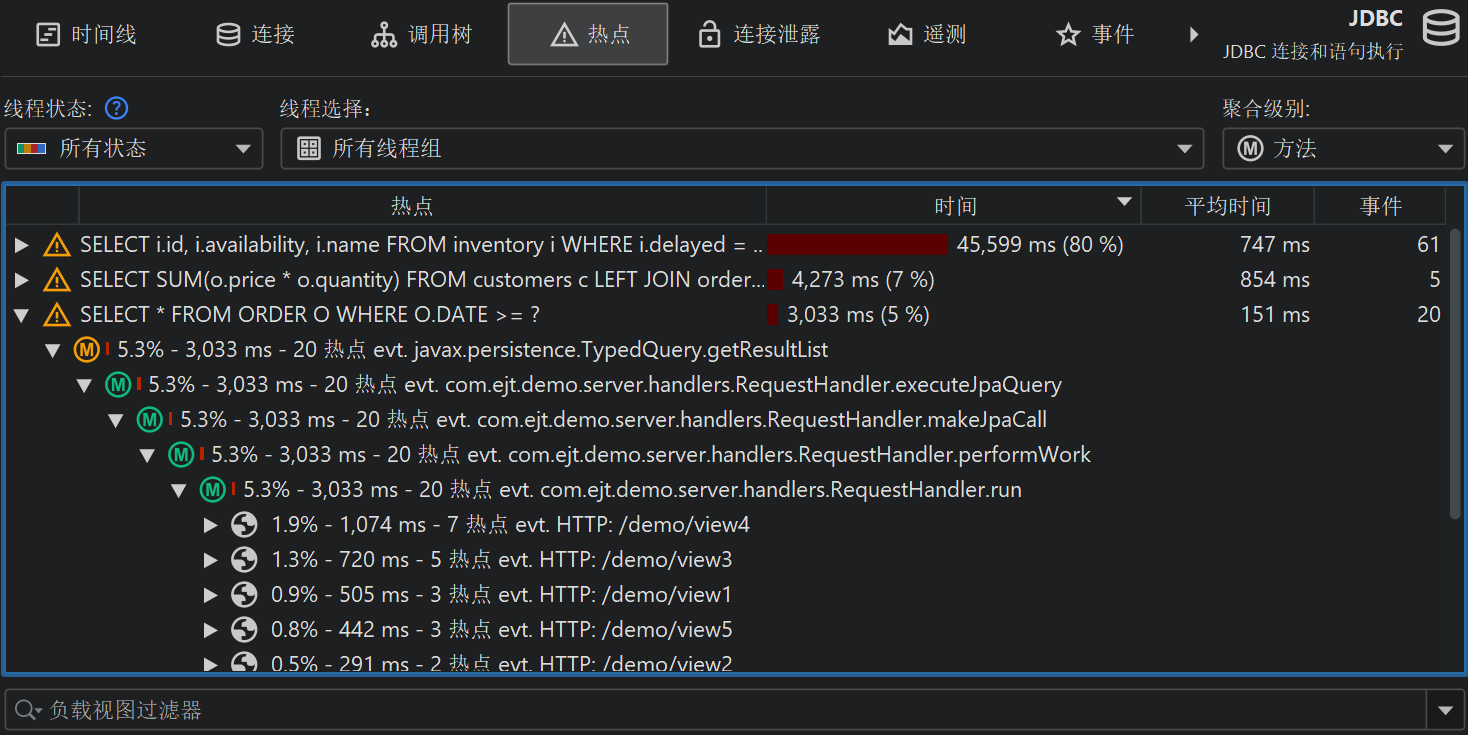
可以从探针调用树计算热点(hot spot)。热点节点现在是有效负载(payload),而不是方法调用 (method call),如CPU 视图部分 (CPU view section)中那样。这通常是探针最直接有用的视图。如果 CPU 记录处于活动状态,你可以展开顶级热点并分析方法回溯,就像在常规 CPU 热点视图中一样。回溯节点上的数字表示在从最深节点到热点下方节点的调用栈上测量到的探针事件数量及其总持续时间。
探针调用树和探针热点视图都允许你选择线程或线程组、线程状态以及方法节点的聚合级别(aggregation level),与对应的 CPU 视图类似。当你从 CPU 视图切换过来比较数据时,需要注意探针视图的默认线程状态是“All states”,而不是 CPU 视图中的“Runnable”。这是因为探针事件通常涉及外部系统,如数据库调用、socket 操作或进程执行,此时关注总耗时而不仅仅是 JVM 实际工作的时间更为重要。
控制对象 (Control objects)
许多提供外部资源访问的库会给你一个连接对象(connection object),用于与资源交互。例如,启动进程时,java.lang.Process对象允许你从输出流读取、向输入流写入。使用
JDBC 时,你需要java.sql.Connection对象来执行 SQL 查询。在 JProfiler 中,这类对象的通用术语是“控制对象 (control object)”。
将探针事件与其控制对象分组并展示其生命周期,有助于你更好地理解问题来源。此外,创建控制对象通常代价较高,因此你需要确保应用程序不会创建过多控制对象,并能正确关闭它们。为此,支持控制对象的探针会有“时间线 (Timeline)”和“控制对象 (Control objects)”视图,后者可能有更具体的名称,例如 JDBC 探针中的“Connections”。当控制对象被打开或关闭时,探针会创建特殊的探针事件,在事件视图中展示,以便你检查相关的调用栈。
在时间线视图中,每个控制对象以条形显示,其着色表示控制对象何时处于活动状态。探针可以记录不同的事件类型,时间线会相应着色。该状态信息不是从事件列表中获取的(事件列表可能已合并或甚至不可用),而是每 100 毫秒从上一次状态采样一次。控制对象有名称,便于你识别。例如,文件探针以文件名作为控制对象名称,JDBC 探针则显示连接字符串作为控制对象名称。
控制对象视图以表格形式显示所有控制对象。默认情况下,已打开和已关闭的控制对象都会显示。你可以使用顶部的控件限制只显示已打开或已关闭的控制对象,或筛选特定列内容。除了控制对象的基本生命周期数据外,表格还显示每个控制对象的累计活动数据,例如事件计数和平均事件持续时间。
不同探针在这里显示的列也不同,例如进程探针会分别显示读取和写入事件的列。即使禁用单事件记录,这些信息也可用。与事件视图类似,底部的总计行可结合筛选功能获取部分控制对象的累计数据。
探针可以在嵌套表格中发布某些属性。这样做是为了减少主表的信息过载,并为表格列留出更多空间。如果存在嵌套表格(如文件和进程探针),每行左侧会有一个展开控件,可以在原地打开属性-值表格。
时间线、控制对象视图和事件视图通过导航操作相互关联。例如,在时间线视图中,你可以右键点击某一行并跳转到其他视图,只显示所选控制对象的数据。这是通过将控制对象 ID 筛选为所选值实现的。
遥测 (Telemetries) 和跟踪器 (tracker)
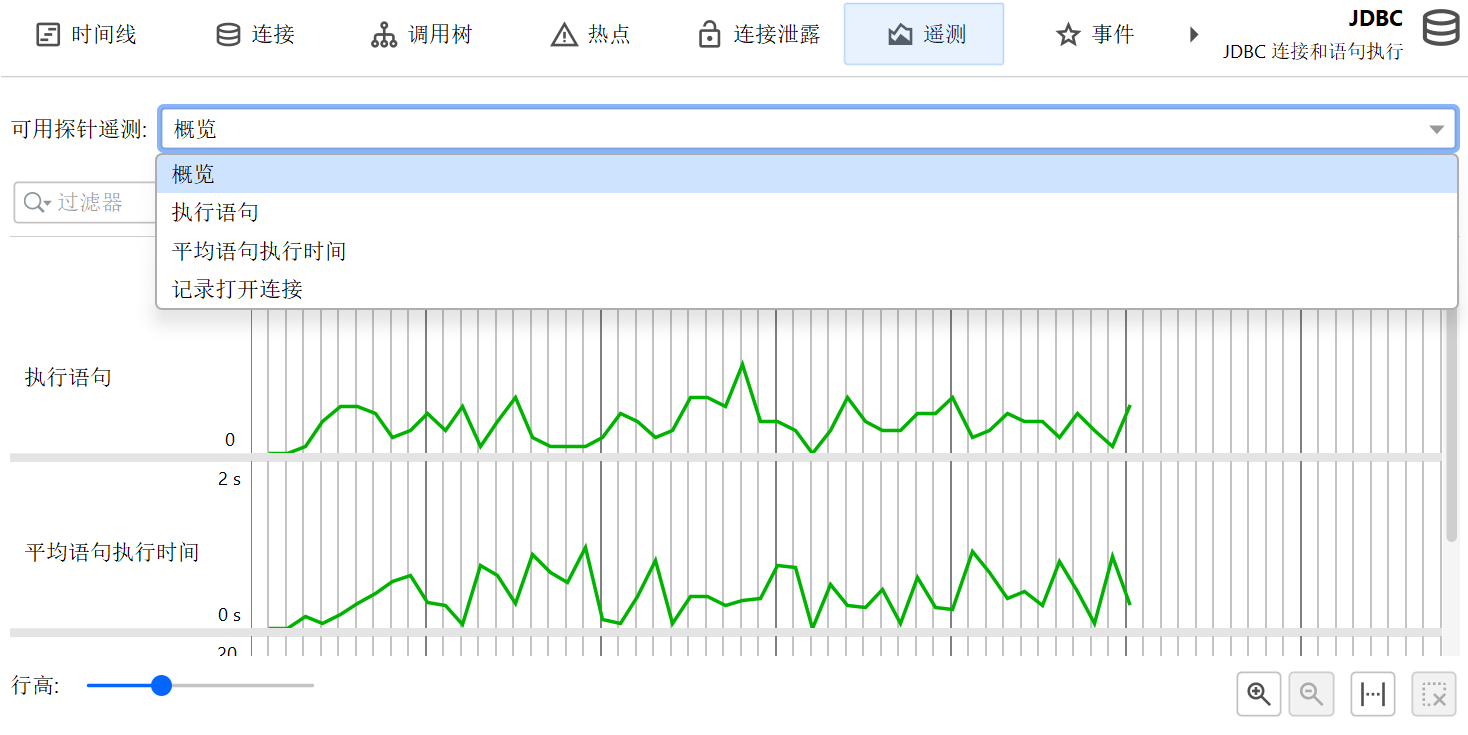
从探针收集的累计数据中,会记录多种遥测(telemetry)。对于任何探针,都会有每秒探针事件数,以及探针事件的某些平均指标,如平均持续时间或 I/O 操作的吞吐量。对于有控制对象的探针,打开的控制对象数量也是标准遥测。每个探针可以添加额外的遥测,例如 JPA 探针会分别显示查询计数和实体操作计数的遥测。
热点视图和控制对象视图显示的累计数据可以用于随时间跟踪。这些特殊遥测会通过探针跟踪器(probe tracker)记录。设置跟踪最简单的方法是在热点或控制对象视图中使用添加所选项到跟踪器 (Add Selection to Tracker)操作添加新的遥测。在这两种情况下,你都需要选择跟踪时间还是计数。跟踪控制对象时,遥测是所有不同探针事件类型的堆叠面积图。对于跟踪的热点,跟踪时间会按不同线程状态拆分。
可以将探针遥测添加到“遥测 (Telemetries)”部分,以便与系统遥测或自定义遥测进行比较。此时你还可以通过遥测概览中的上下文菜单操作控制探针记录。
JDBC 和 JPA
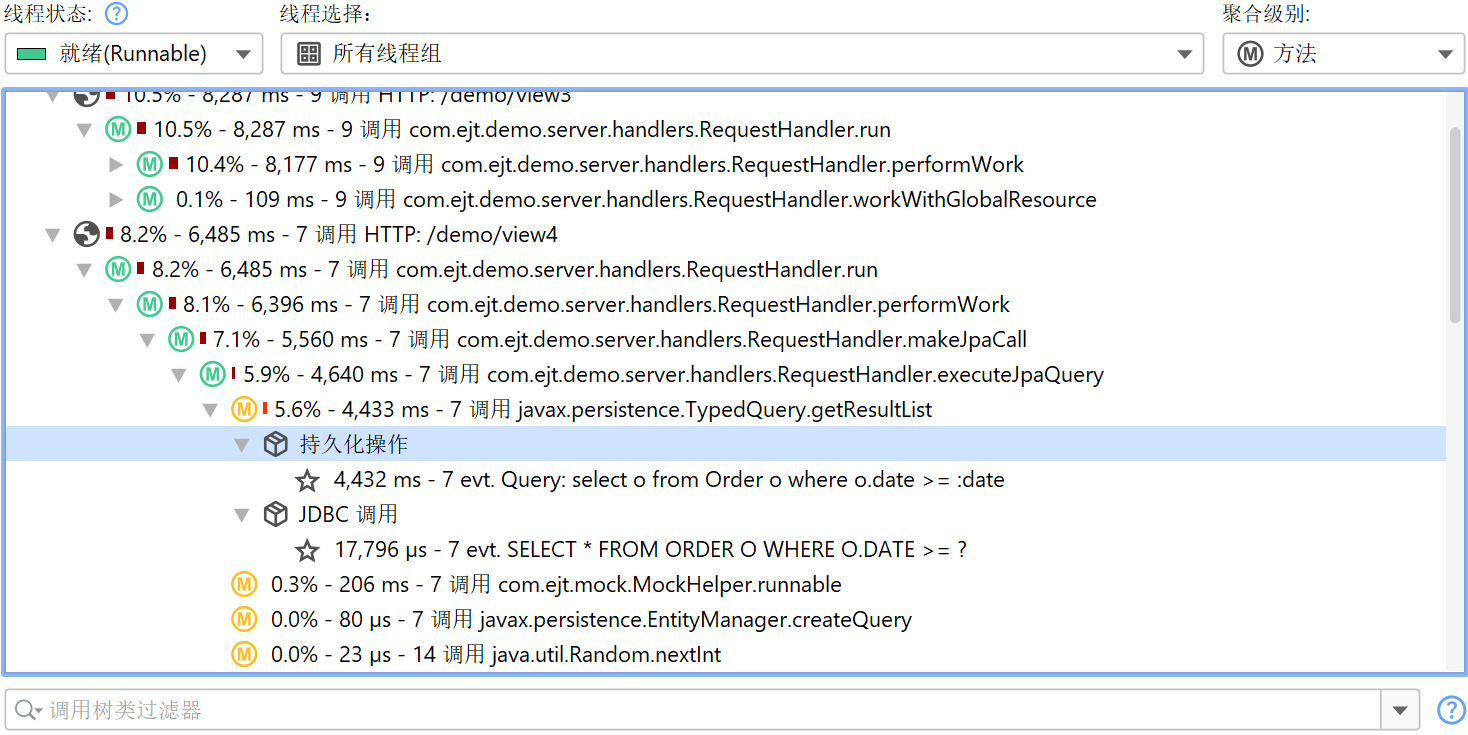
JDBC 和 JPA 探针协同工作。在 JPA 探针的事件视图中,如果同时记录了 JDBC 探针,可以展开单个事件查看相关的 JDBC 事件。
类似地,热点视图会在所有热点下添加一个特殊的“JDBC 调用 (JDBC calls)”节点,包含由 JPA 操作触发的 JDBC 调用。某些 JPA 操作是异步的,并不会立即执行,而是在会话刷新(flush)时的某个任意时间点执行。查找性能问题时,该刷新操作的调用栈并不有用,因此 JProfiler 会记住获取现有实体或持久化新实体时的调用栈,并将其关联到探针事件。在这种情况下,热点的回溯包含在标记为“延迟操作 (Deferred operations)”的节点中,否则会插入“直接操作 (Direct operations)”节点。
其他探针(如 MongoDB 探针)支持直接和异步操作。异步操作不会在当前线程上执行,而是在同一 JVM 的其他线程或其他进程中执行。对于此类探针,热点中的回溯会被归类到“直接操作 (Direct operations)”和“异步操作 (Async operation)”容器节点中。
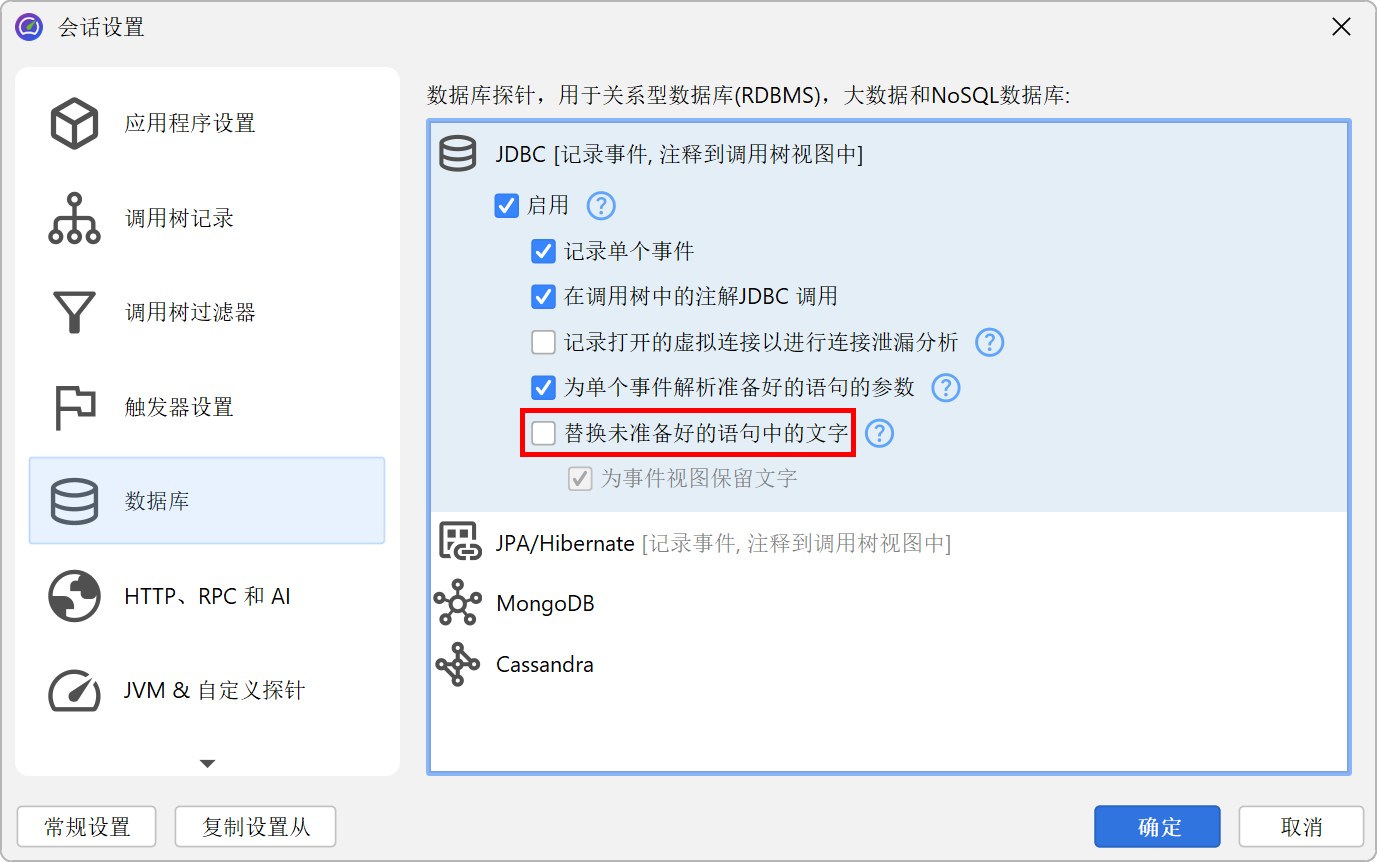
JDBC 探针中的一个特殊问题是,只有在 SQL 字符串中不包含字面量数据(如 ID)时,才能获得良好的热点。这在使用预编译语句时会自动实现,但在执行常规语句时则不会。在后者情况下,你可能会得到一个热点列表,其中大多数查询只执行一次。为了解决这个问题,JProfiler 在 JDBC 探针配置中提供了一个非默认选项,用于替换未预编译语句中的字面量。出于调试目的,你可能仍然希望在事件视图中看到字面量。禁用该选项可以减少内存开销,因为 JProfiler 不必缓存那么多不同的字符串。
另一方面,JProfiler 会收集预编译语句的参数,并在事件视图中显示完整的、不带占位符的 SQL 字符串。这在调试时很有用,但如果你不需要,可以在探针设置中关闭,以节省内存。
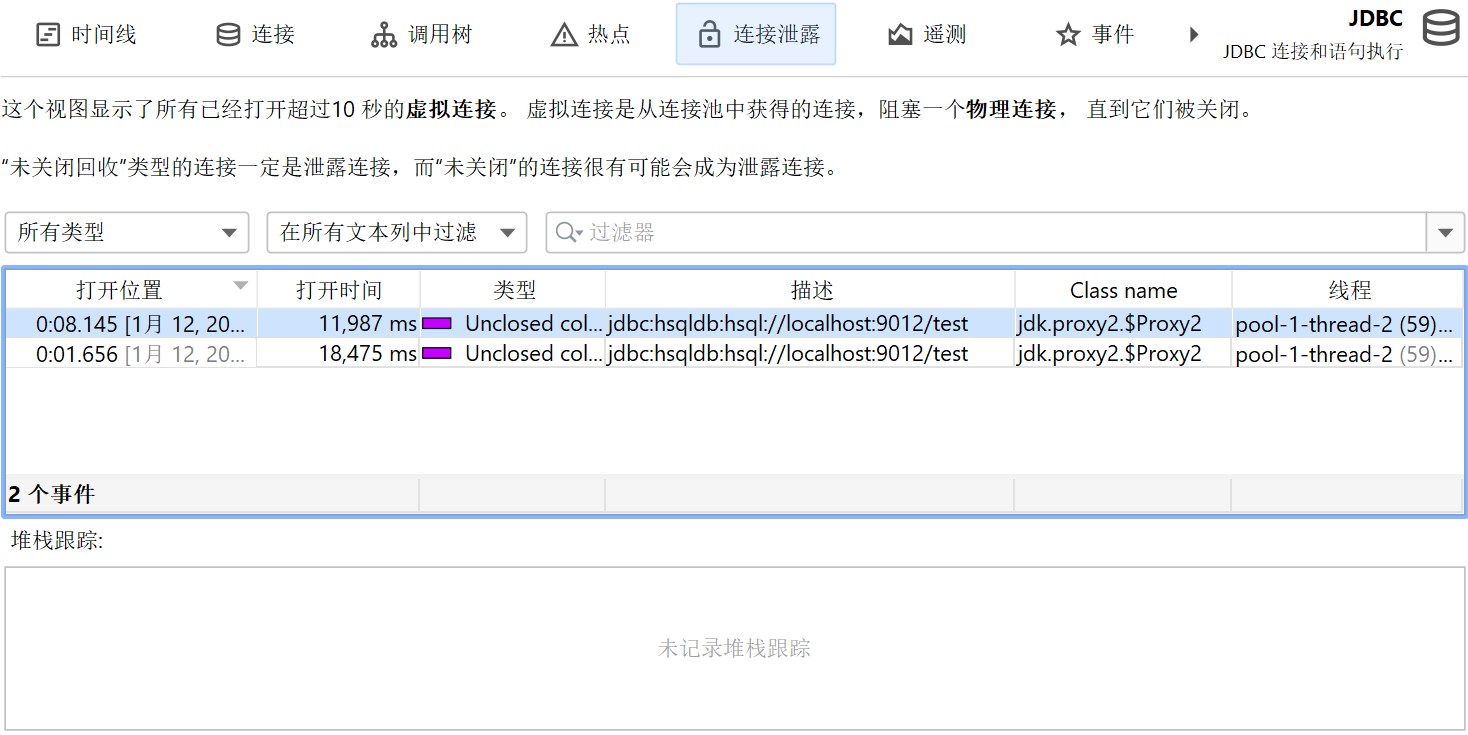
JDBC 连接泄漏 (connection leaks)
JDBC 探针有一个“连接泄漏 (Connection leaks)”视图,显示未归还到数据库池的打开虚拟数据库连接。这只影响由池化数据库源创建的虚拟连接。虚拟连接会阻塞物理连接,直到它们被关闭。
泄漏候选有两种类型:“未关闭 (unclosed)”连接和“未关闭已回收 (unclosed
collected)”连接。两者都是虚拟连接,其连接对象已由数据库池分发但仍在堆上,且未调用close()。"未关闭已回收"连接已被垃圾回收,属于确定的连接泄漏。
“未关闭”连接对象仍在堆上。打开时长 (Open Since)持续时间越长,该虚拟连接越可能是泄漏候选。当虚拟连接已打开超过 10
秒时,会被视为潜在泄漏。然而,仍然可能会调用close(),此时“连接泄漏”视图中的条目会被移除。
连接泄漏表格包含类名 (Class Name)列,显示连接类的名称。这可以告诉你是哪种池创建了连接。JProfiler 明确支持大量数据库驱动和连接池,并知道哪些类是虚拟连接、哪些是物理连接。对于未知的池或数据库驱动,JProfiler 可能会把物理连接误认为虚拟连接。由于物理连接通常存活时间较长,这种情况下会显示在“连接泄漏”视图中。此时,连接对象的类名可以帮助你识别误报。
默认情况下,启动探针记录时不会启用连接泄漏分析。连接泄漏视图中有一个单独的记录按钮,其状态对应于 JDBC 探针设置中的为连接泄漏分析记录打开的虚拟连接 (Record open virtual connections for connection leak analysis)复选框。与事件记录类似,按钮状态是持久的,因此只要你启动过一次分析,下次探针记录会话会自动启动。
调用树中的有效负载数据 (Payload data in the call tree)
查看 CPU 调用树时,了解探针记录了哪些有效负载数据很有意义。这些数据有助于你解释测得的 CPU 时间。因此,许多探针会在 CPU 调用树中添加交叉链接。例如,类加载器探针可以显示类加载被触发的位置,这在调用树中通常不可见,但可能带来意外的开销。数据库调用在调用树视图中通常是黑盒,但可以通过单击在对应探针中进一步分析。即使在调用树分析中,也可以自动在探针调用树视图上下文中重复分析,只需点击探针链接即可。
另一种方式是直接在 CPU 调用树内联显示有效负载信息。所有相关探针在其配置中都有在调用树中注解 (Annotate in call tree)选项。此时,不会有指向探针调用树的链接。每个探针都有自己的有效负载容器节点。具有相同有效负载名称的事件会被聚合,并显示调用次数和总耗时。有效负载名称按每个调用栈合并,最早的条目会聚合到“[earlier calls]”节点中。每个调用栈记录的有效负载名称最大数量可在配置文件设置中配置。
调用树拆分 (Call tree splitting)
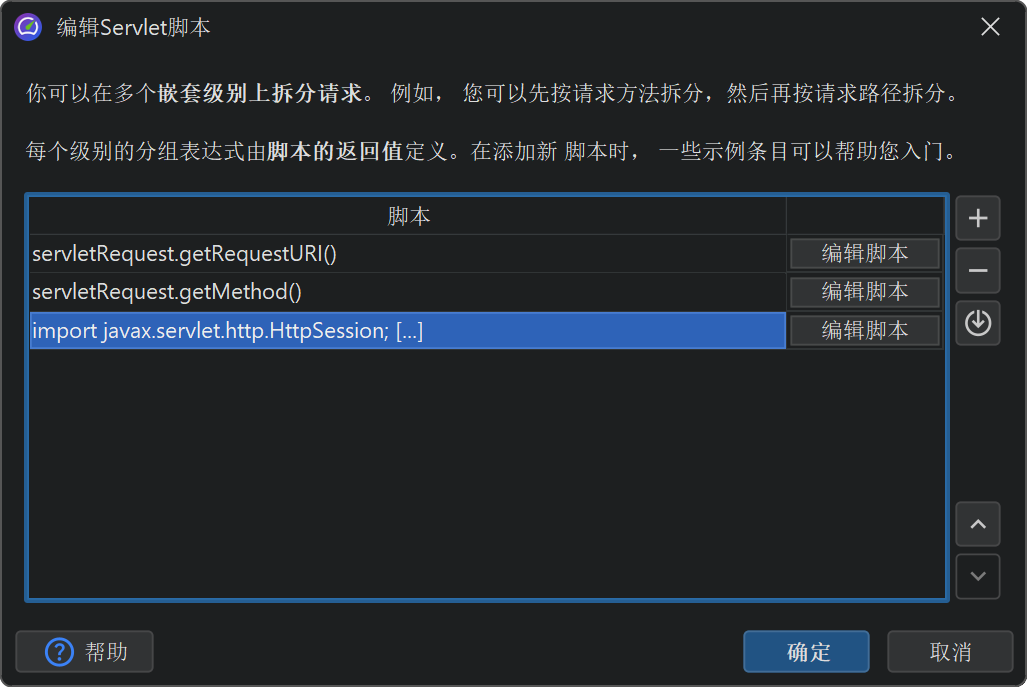
有些探针不会用其探针字符串将有效负载数据注解到调用树中,而是为每个不同的探针字符串拆分调用树(call tree splitting)。这对于服务器类探针尤其有用,你可以为每种不同类型的请求分别查看调用树。“HTTP server”探针会拦截 URL,并让你精细控制 URL 的哪些部分用于拆分调用树。默认情况下,只使用请求 URI 路径,不包含任何参数。
为了更灵活,你可以定义脚本来决定拆分字符串。在脚本中,你会获得当前javax.servlet.http.HttpServletRequest作为参数,并返回所需字符串。
更进一步,你不仅限于单层拆分,还可以定义多层嵌套拆分。例如,可以先按请求 URI 路径拆分,再按从 HTTP 会话对象中提取的用户名拆分。或者,可以先按请求方法分组,再按请求 URI 拆分。
通过使用嵌套拆分,你可以在调用树的每一层看到单独的数据。查看调用树时,某一层可能会妨碍你分析,此时你可能需要在“HTTP server”探针配置中去除该层。更方便的是,你可以在调用树中通过对应拆分节点的上下文菜单,临时合并或取消合并拆分层级,无需丢失已记录数据。
拆分调用树可能会带来较大的内存开销,因此应谨慎使用。为避免内存溢出,JProfiler 会限制最大拆分数。如果某一拆分层级达到上限,会添加一个特殊的“[capped nodes]”拆分节点,并带有重置上限计数器的超链接。如果默认上限对你来说太低,可以在配置文件设置中提高它。