记录方法调用是 profiler(分析器)中最具挑战性的任务之一,因为它需要在相互冲突的约束下运行:结果应当准确、完整,并且带来的开销要足够小,确保你从测量数据中得出的结论不会出现偏差。不幸的是,没有一种测量方式能够在所有类型的应用中同时满足这些要求。因此,JProfiler 需要你根据实际情况选择合适的方式。
采样(Sampling)与插桩(Instrumentation)
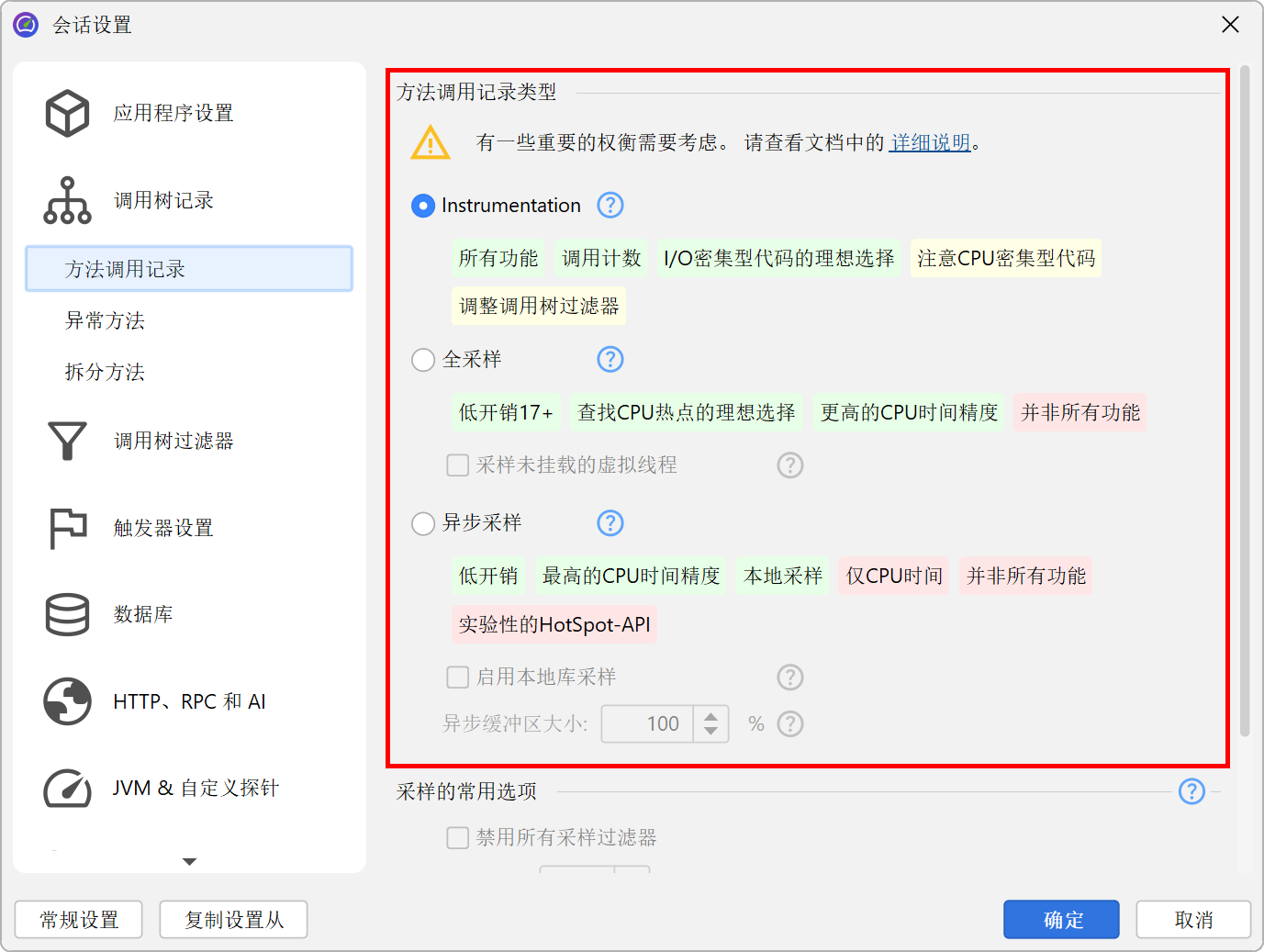
方法调用的测量可以通过两种本质上不同的技术实现,分别是“采样(sampling)”和“插桩(instrumentation)”,它们各有优缺点:采样方式会定期检查线程的当前调用栈(call stack);插桩方式则会修改选定类的字节码,以跟踪方法的进入和退出。插桩能够统计所有方法的调用次数(invocation count),并为所有方法生成调用计数。
在处理采样数据时,完整的采样周期(通常为 5 ms)会归属于被采样的调用栈。随着采样次数的增加,最终会得到统计上准确的结果。采样的优点在于开销极低,因为采样发生得很少。不需要修改字节码,并且采样周期远大于典型方法调用的持续时间。缺点是无法统计方法的调用次数(invocation count),而且仅被调用少数几次的短方法可能完全不会出现在结果中。如果你只是定位性能瓶颈(performance bottleneck),这并不重要,但如果你需要深入了解代码的运行时特性,这可能会带来不便。
另一方面,如果插桩了大量短方法,插桩方式可能会带来较大的开销。这种插桩会因为时间测量本身的开销,以及许多本可被 HotSpot 编译器内联(inline)的方法现在必须作为独立方法调用而影响性能热点(hot spot)的相对重要性。对于耗时较长的方法调用,这部分开销可以忽略不计。如果你能选出主要执行高层操作的一组类,插桩带来的开销会非常低,此时插桩方式可能优于采样。JProfiler 的开销热点(hot spot)检测也可以在多次运行后改善这一情况。此外,调用次数(invocation count)通常是非常重要的信息,可以帮助你更清晰地了解实际情况。
全量采样(Full sampling)与异步采样(Async sampling)
JProfiler 提供了两种不同的采样技术方案:“全量采样(Full sampling)”通过单独的线程定期暂停 JVM 中的所有线程,并检查它们的堆栈跟踪(stack trace)。但 JVM 只会在某些“安全点(safe point)”暂停线程,这会引入一定的偏差。如果你的代码是高度多线程且 CPU 密集型的,被分析(profiled)的热点(hot spot)分布可能会被扭曲。另一方面,如果代码还涉及大量 I/O 操作,这种偏差通常不会成为问题。
为了帮助高度 CPU 密集型代码获得更准确的数据,JProfiler 还提供了异步采样(Async sampling)。异步采样会在运行中的线程上调用 profiling signal handler。profiling agent 随后会检查 native stack 并提取 Java stack frame。其主要优点是,这种采样方式不会有安全点(safe point)偏差,并且对于高度多线程、CPU 密集型应用来说开销更低。但需要注意的是,CPU 视图(view)下只能观测到“Running”线程状态,无法通过此方式测量“Waiting”、“Blocking”或“Net I/O”线程状态。探针(probe)数据始终通过字节码插桩收集,因此你仍然可以获得 JDBC 及类似数据的所有线程状态。
异步采样(Async sampling)存在调用跟踪被截断(truncated trace)的情况,只能获取调用栈(call stack)的末端。因此,对于异步采样,调用树(call tree)通常不如热点(hot spot)视图有用。异步采样仅支持 Linux 和 macOS。
从 Java 17 开始,JProfiler 可以在 HotSpot JVM 上避免使用全局安全点(global safe point)进行采样,从而实现几乎零开销的全量采样(full sampling)。与异步采样相比,虽然对单个线程仍然会有一定的安全点偏差,但已不再对 JVM 中所有线程引入全局安全点的开销。考虑到异步采样的缺点,建议在 Java 17 及以上版本中优先使用全量采样(full sampling)。
选择方法调用记录类型
选择哪种方法调用记录类型用于 profiling(分析)是一个重要决策,没有一种方式适用于所有场景,因此你需要根据实际情况做出明智的选择。当你创建新会话(session)时,会话启动对话框会询问你希望使用哪种方法调用记录类型。在之后的任何时候,你都可以在会话设置(session settings)对话框中更改方法调用记录类型。
作为简单的参考,可以通过以下问题判断你的应用是否属于两个极端中的某一类:
-
被分析(profiled)应用是否为 I/O 密集型?
许多 Web 应用大部分时间都在等待 REST 服务(service)和 JDBC 数据库调用。如果是这种情况,在你仔细选择调用树(call tree)过滤器,仅包含自己的代码的前提下,插桩(instrumentation)将是最佳选择。 -
被分析(profiled)应用是否高度多线程且 CPU 密集型?
例如,编译器、图像处理应用,或正在运行负载测试的 web server 都属于这种情况。如果你在 Linux 或 macOS 上进行 profiling,建议选择异步采样(Async sampling),以获得最准确的 CPU 时间。
其他情况下,“全量采样(Full sampling)”通常是最合适的选项,并建议作为新会话(session)的默认选择。
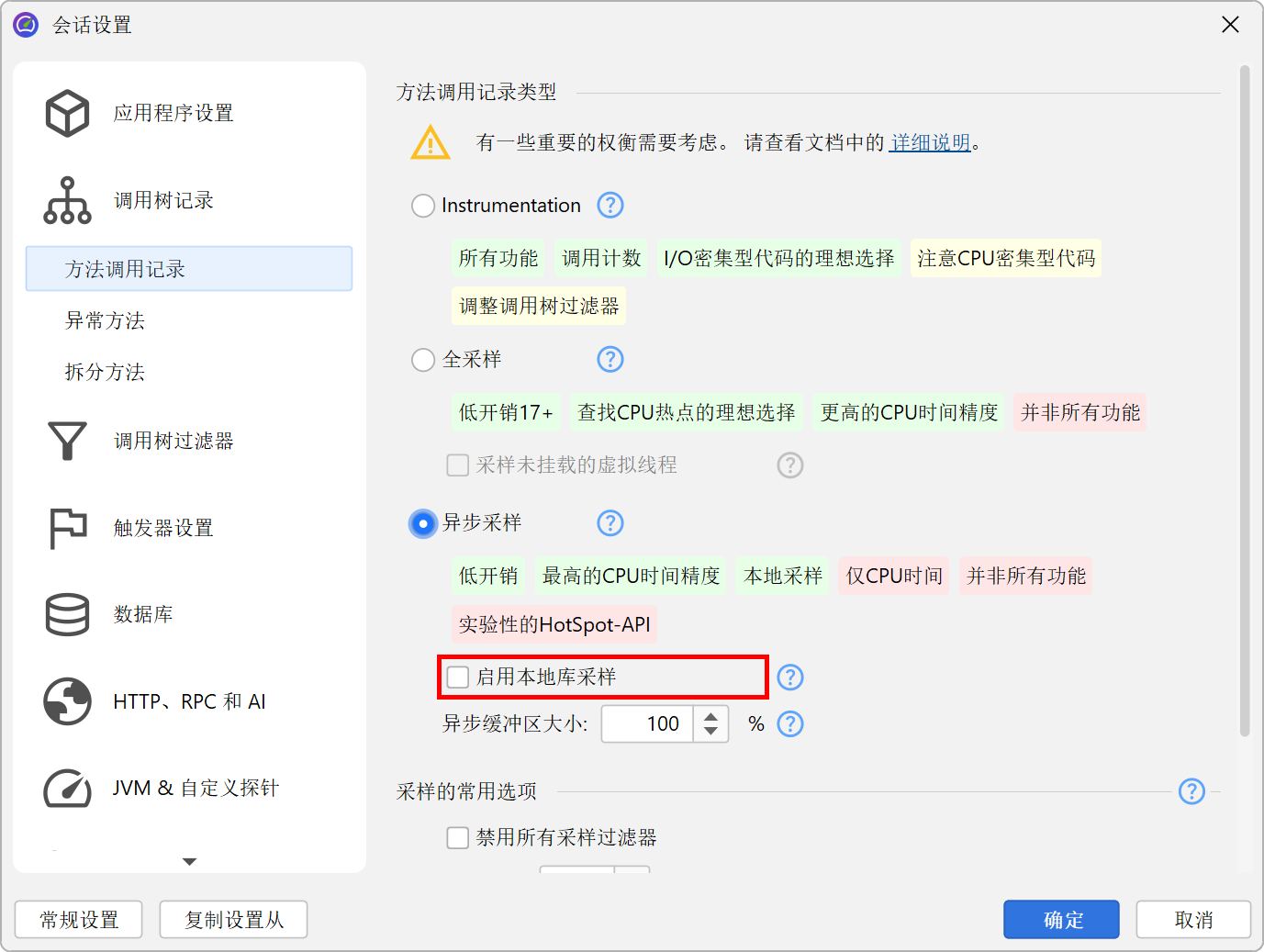
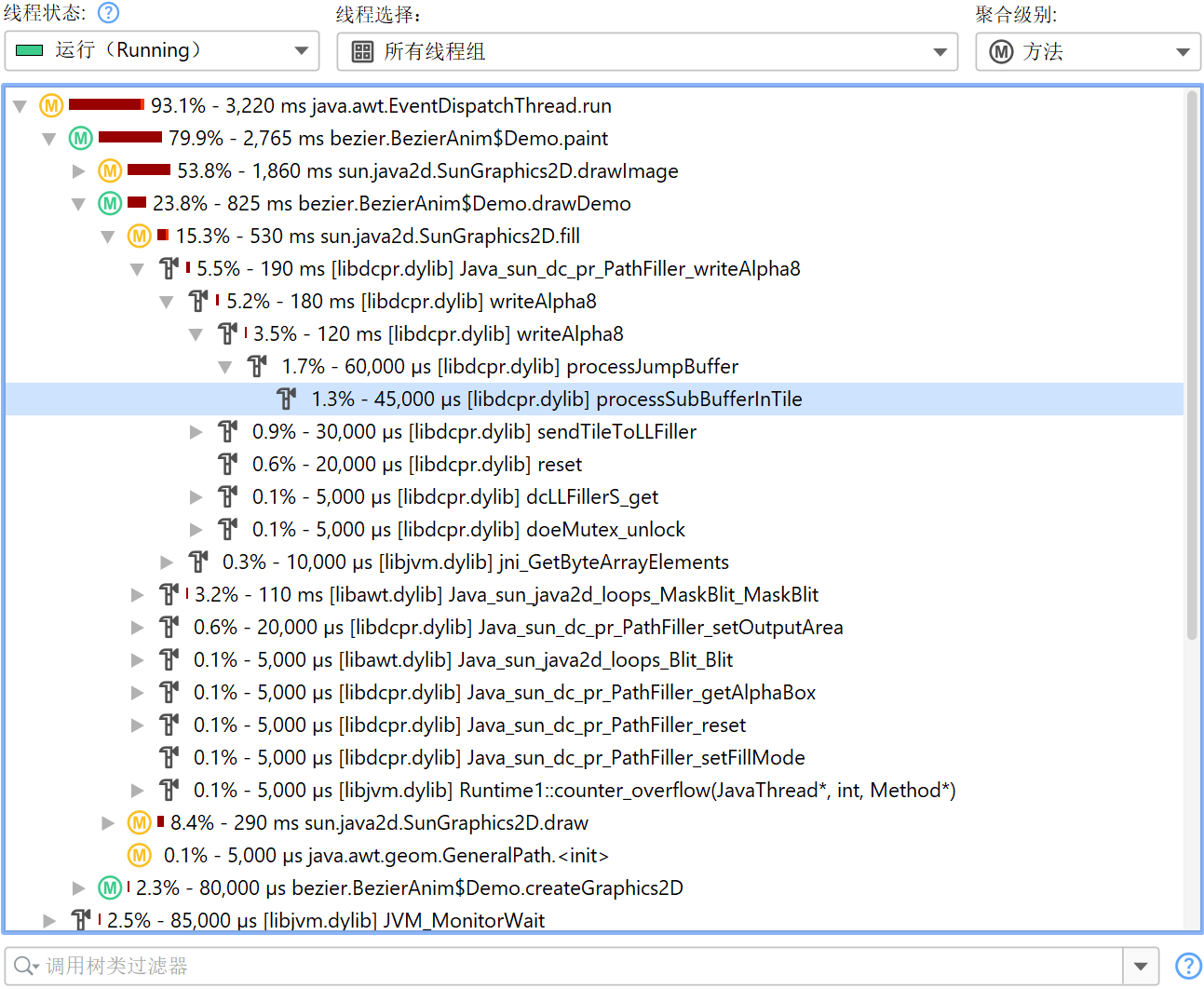
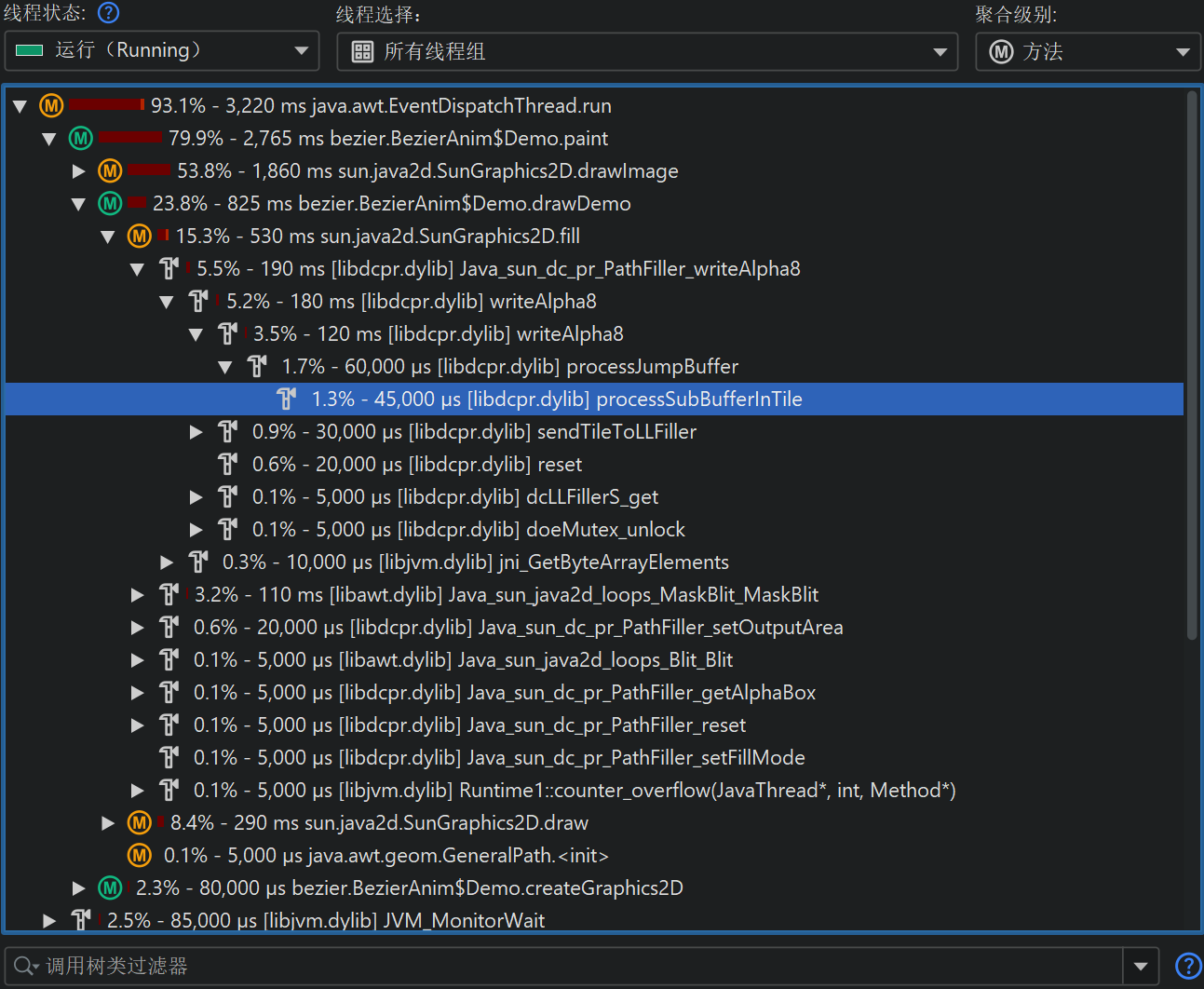
Native sampling(本地采样)
由于异步采样(Async sampling)可以访问 native stack,因此也可以执行 native sampling(本地采样)。默认情况下,本地采样未启用,因为它会在调用树(call tree)中引入大量节点,并将热点(hot spot)计算的关注点转移到 native 代码。如果你确实遇到 native 代码的性能问题,可以选择异步采样(Async sampling),并在会话设置(session settings)中启用本地采样(native sampling)。
JProfiler 会解析属于每个 native stack frame 的库(library)路径。在调用树(call tree)中的 native 方法节点上,JProfiler 会在开头用方括号显示 native 库的文件名。
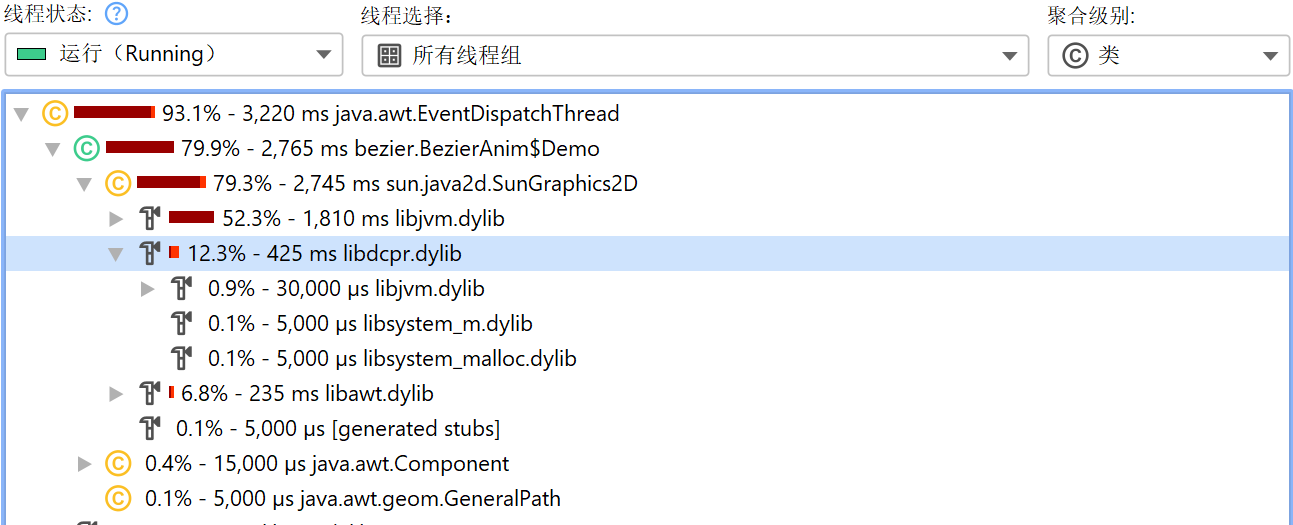
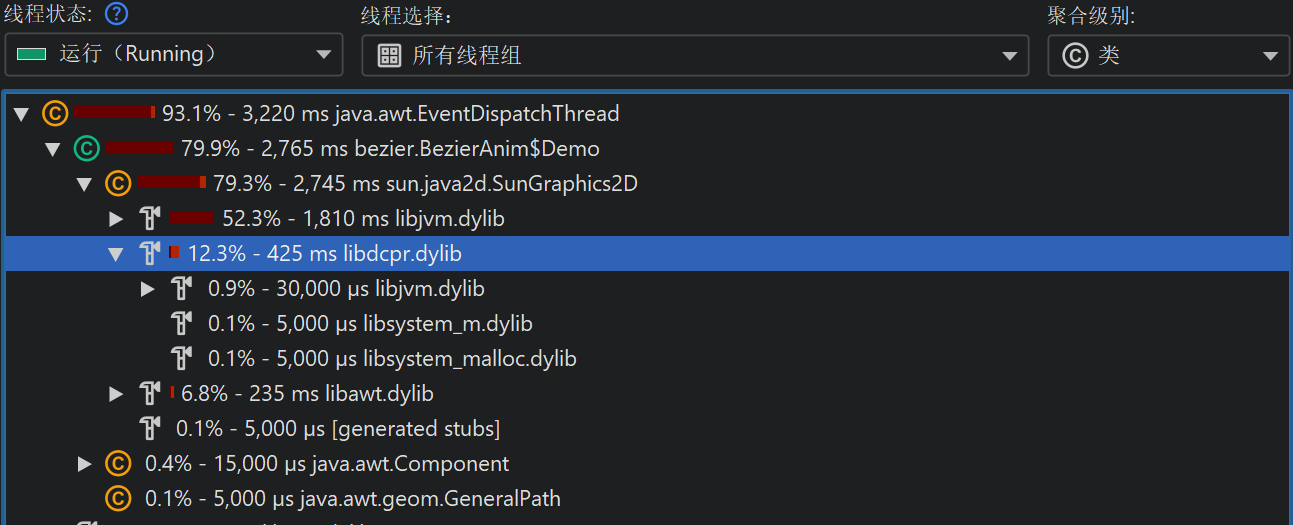
就聚合级别(aggregation level)而言,native 库的行为类似于类(class),因此在“类(classes)”聚合级别下,同一 native 库内的所有后续调用会被聚合为单个节点(node);而“包(packages)”聚合级别下,所有后续 native 方法调用都会被聚合为单个节点,无论它们属于哪个 native 库。
若要排除特定 native 库,可以 移除节点(node),并选择移除整个类(class)。