JProfilerがメソッドコールの実行時間とその呼び出しスタックを計測することを「CPUプロファイリング」と呼びます。このデータは様々な方法で表示されます。解決したい問題によって、最適な表示方法が異なります。CPUデータはデフォルトでは記録されていません。興味深いユースケースをキャプチャするには、CPU記録を有効化する必要があります。
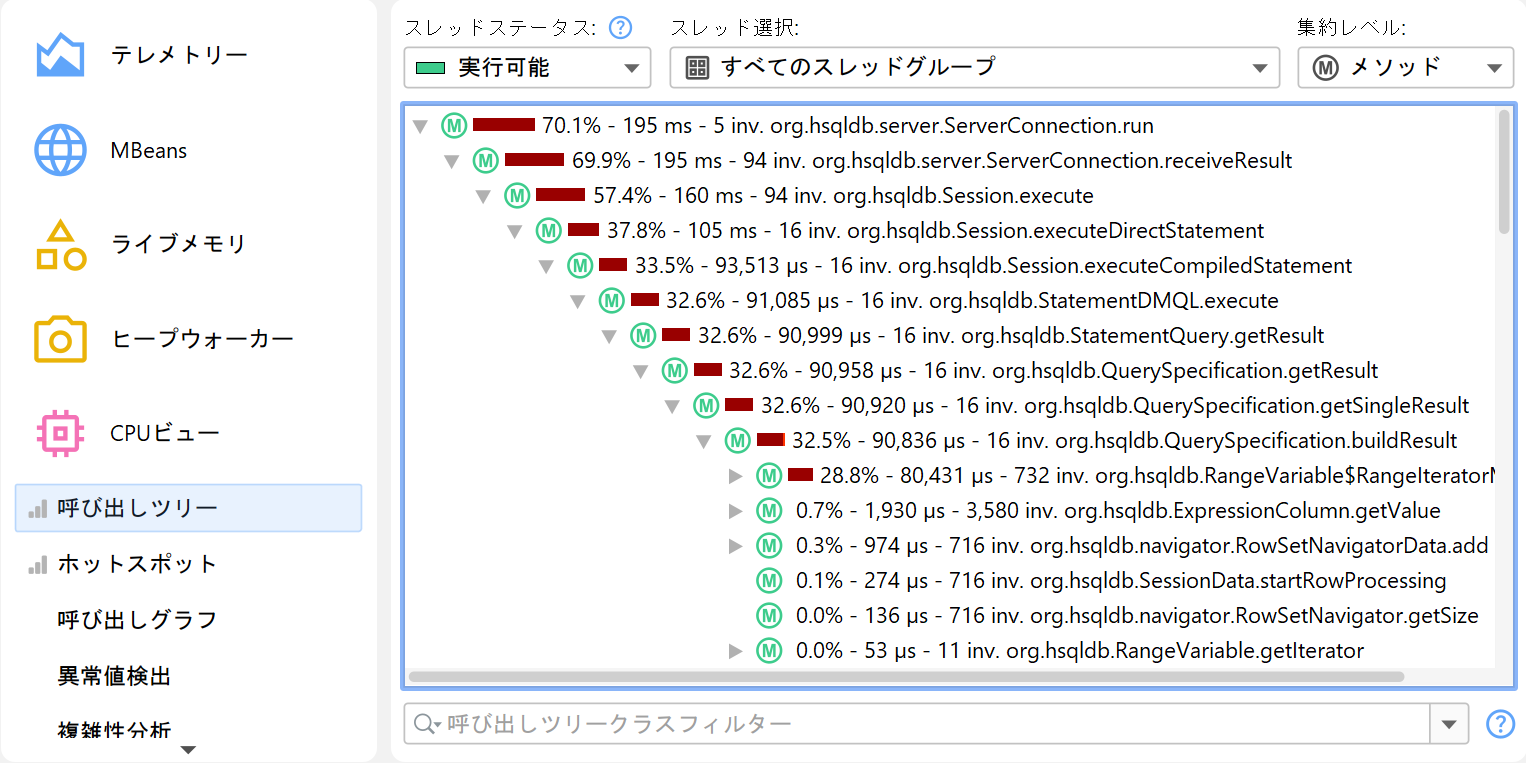
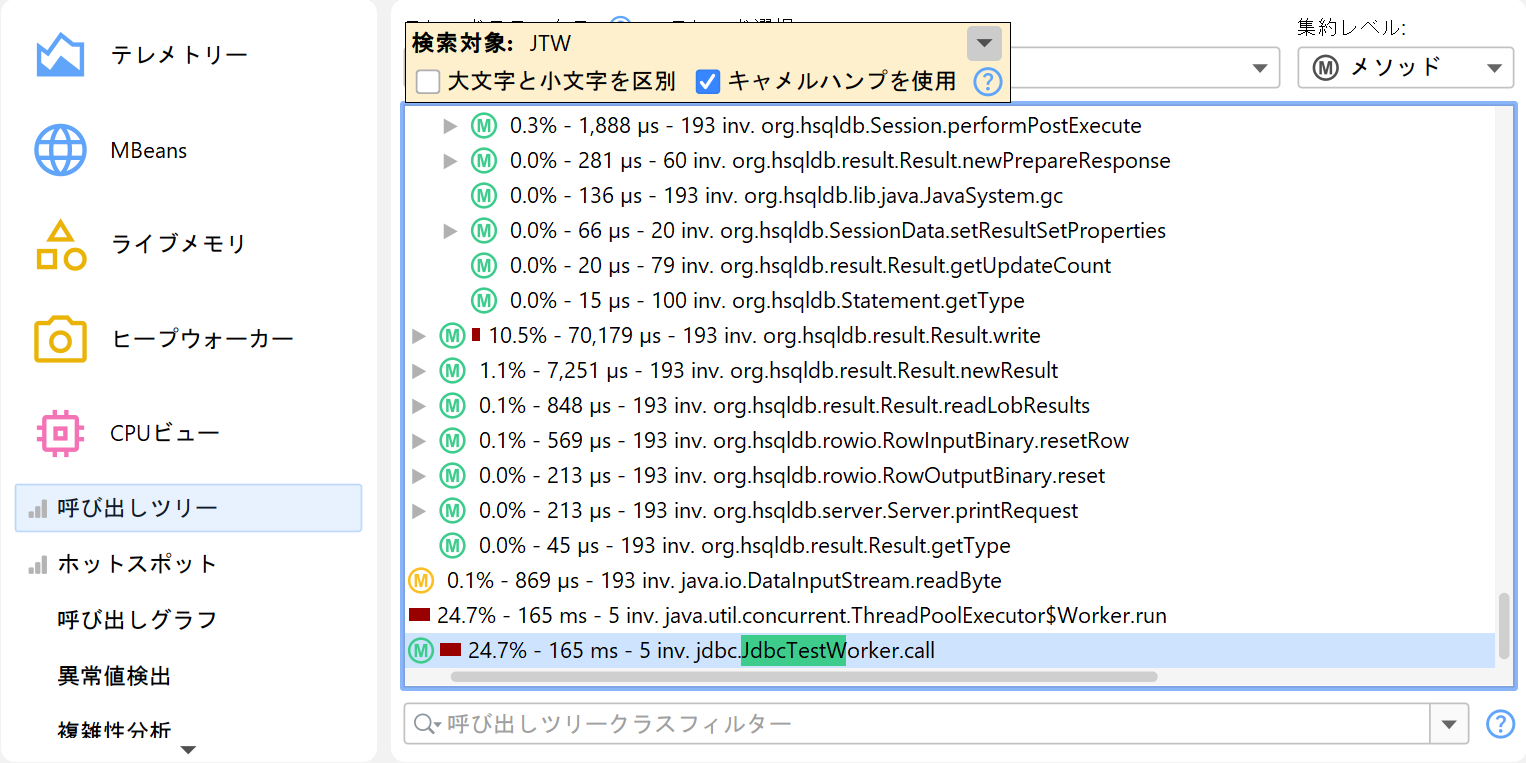
呼び出しツリー
すべてのメソッドコールとその呼び出しスタックを追跡すると、かなりのメモリを消費し、短時間でメモリが枯渇してしまいます。また、忙しいJVMでのメソッドコール数を直感的に把握するのは容易ではありません。通常、その数は非常に多いため、トレースの特定や追跡は不可能です。
もう一つの観点として、多くのパフォーマンス問題は収集したデータを集約することで初めて明確になります。この方法で、特定の期間内におけるメソッドコールの重要性を全体のアクティビティと比較して把握できます。単一のトレースだけでは、データの相対的重要性を知ることはできません。
そのため、JProfilerは観測されたすべての呼び出しスタックの累積ツリーを構築し、観測されたタイミングや呼び出し回数を注釈として付与します。時系列的な側面は排除され、合計値のみが保持されます。ツリー内の各ノードは、少なくとも一度観測された呼び出しスタックを表します。ノードには子ノードがあり、その呼び出しスタックで観測されたすべてのアウトゴーイングコールを表します。
呼び出しツリーは「CPUビュー」セクションの最初のビューであり、CPUプロファイリングを始める際の良い出発点です。トップダウンビューでメソッドコールを開始点から最も細かい終点まで追うことができ、直感的に理解しやすいです。JProfilerは子ノードを合計時間でソートするため、ツリーを深さ優先で展開して、パフォーマンスに最も影響を与える部分を分析できます。
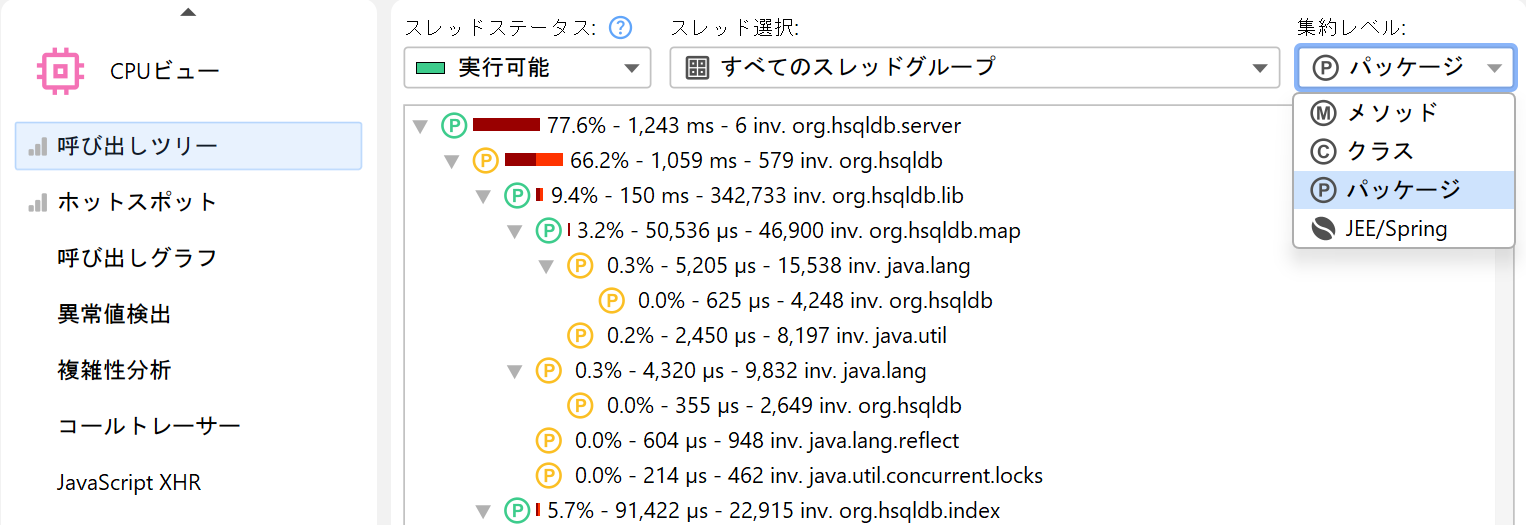
すべての計測はメソッド単位で行われますが、JProfilerではクラスやパッケージレベルで呼び出しツリーを集約することも可能です。集約レベルセレクターには「JEE/Springコンポーネント」モードも含まれています。アプリケーションがJEEやSpringを利用している場合、このモードを使うとクラスレベルでJEEやSpringのコンポーネントのみを表示できます。URLのような分割ノードはすべての集約レベルで保持されます。
呼び出しツリーフィルター
すべてのクラスのメソッドが呼び出しツリーに表示されると、ツリーが深くなりすぎて管理が困難になります。アプリケーションがフレームワークから呼び出されている場合、呼び出しツリーの上部はフレームワークのクラスで構成され、自分のクラスは深く埋もれてしまいます。ライブラリへのコールも内部構造が表示され、何百ものメソッドコールレベルが現れ、把握や影響を与えることが困難です。
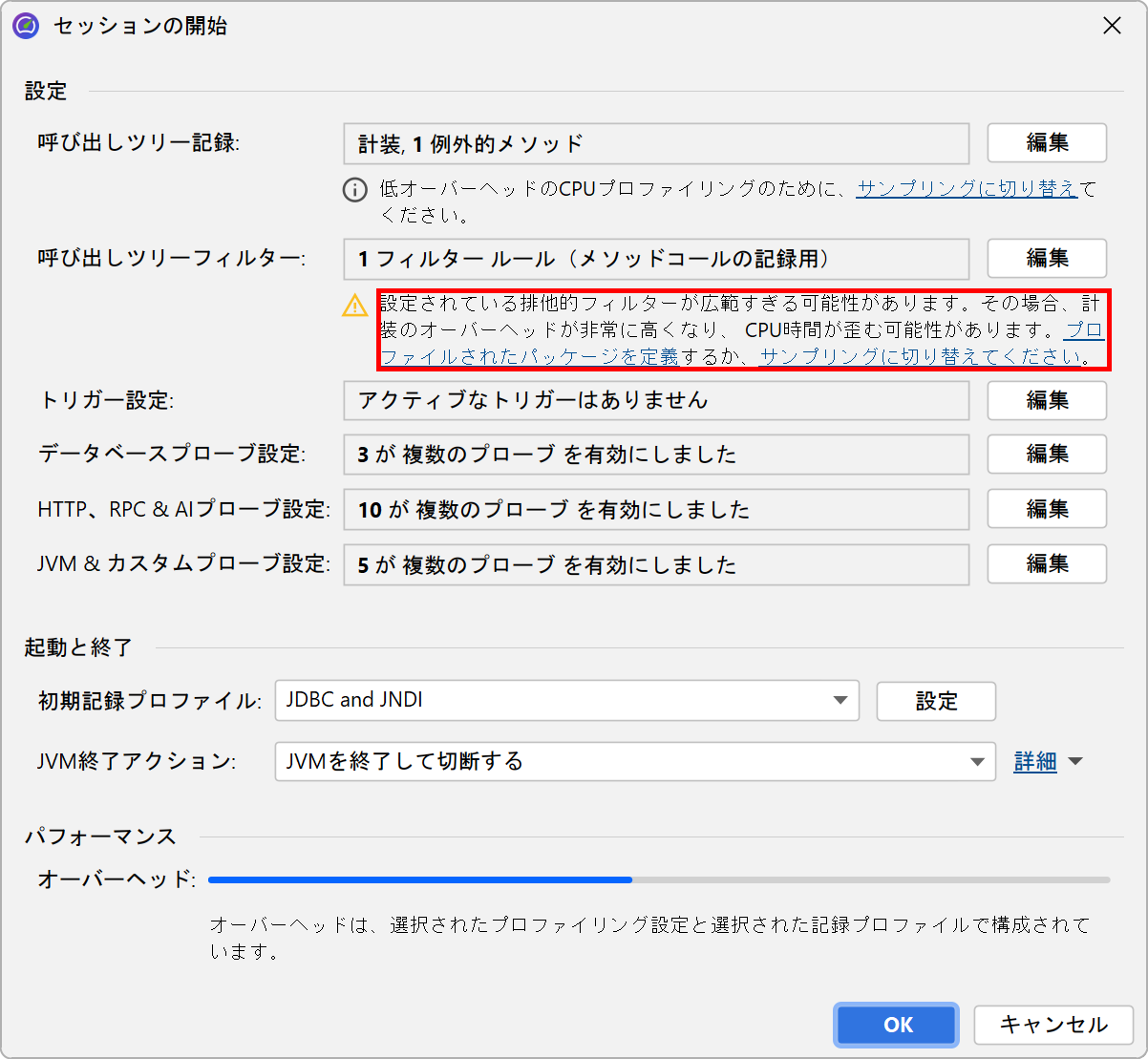
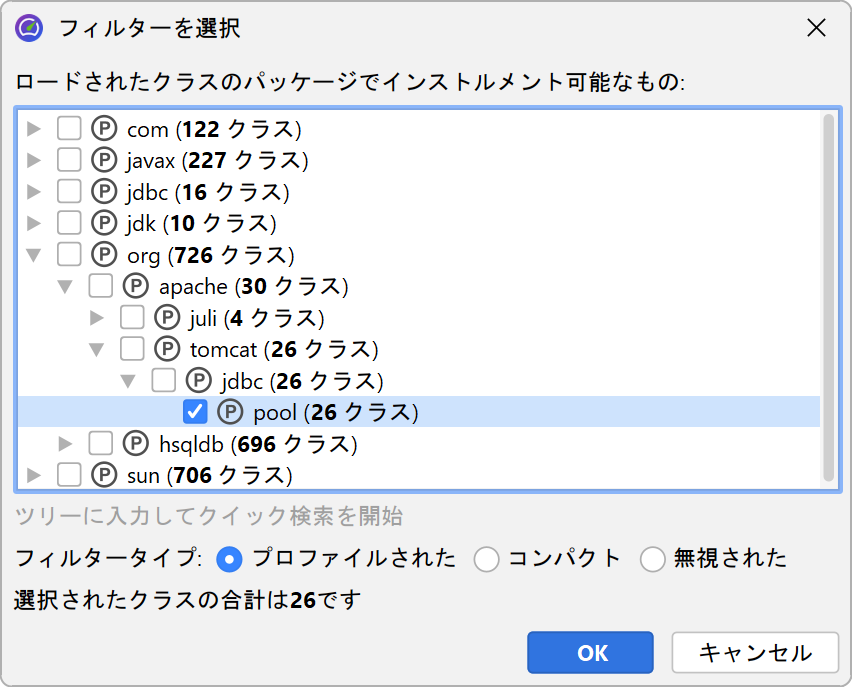
この問題の解決策は、呼び出しツリーにフィルターを適用し、特定のクラスのみを記録することです。副次的な効果として、収集するデータ量が減り、インストゥルメント化するクラスも少なくなるため、オーバーヘッドも減少します。
デフォルトでは、プロファイリングセッションにはよく使われるフレームワークやライブラリの除外パッケージリストが設定されています。
もちろんこのリストは不完全なので、自分で削除して興味のあるパッケージを定義する方がはるかに良いです。実際、インストゥルメンテーションとデフォルトフィルターの組み合わせは望ましくないため、JProfilerはセッション開始ダイアログで変更を推奨します。
フィルター式は完全修飾クラス名と比較されるため、com.mycorp.はcom.mycorp.myapp.Applicationのようなすべてのネストされたパッケージのクラスにマッチします。フィルターには「プロファイルされた」「コンパクト」「無視」の3種類があります。「プロファイルされた」クラスのすべてのメソッドが計測対象です。これは自分のコードに必要な設定です。
「コンパクト」フィルターに含まれるクラスでは、そのクラスへの最初の呼び出しのみが計測され、内部の呼び出しは表示されません。「コンパクト」はJREを含むライブラリに適しています。例えば、hashMap.put(a, b)を呼び出す場合、呼び出しツリーでHashMap.put()は見たいですが、それ以上の内部処理は不要です。マップ実装の開発者でない限り、内部動作はブラックボックスとして扱うべきです。
最後に、「無視」メソッドはまったくプロファイルされません。オーバーヘッドの観点からインストゥルメント化が望ましくない場合や、呼び出しツリーでGroovyの内部メソッドのようにノイズとなる場合などです。
パッケージを手動で入力するのはミスが起きやすいため、パッケージブラウザを利用できます。セッション開始前は、設定されたクラスパス上のパッケージしか表示できませんが、実行時にはロード済みのすべてのクラスが表示されます。
設定されたフィルターリストは、各クラスごとに上から下へ評価されます。各段階で、現在のフィルタータイプはマッチがあれば変更されます。リストの最初のフィルターが何かが重要です。「プロファイルされた」フィルターから始めると、クラスの初期フィルタータイプは「コンパクト」になり、明示的なマッチのみがプロファイルされます。
「コンパクト」フィルターから始めると、クラスの初期フィルタータイプは「プロファイルされた」になります。この場合、明示的に除外されたクラス以外はすべてプロファイルされます。
呼び出しツリーの時間
呼び出しツリーを正しく解釈するには、ノードに表示される数値の意味を理解することが重要です。各ノードには合計時間と自己時間の2つの時間があります。自己時間は、そのノードの合計時間からネストされたノードの合計時間を差し引いたものです。
通常、自己時間は小さいですが、コンパクトフィルターされたクラスでは例外です。多くの場合、コンパクトフィルターされたクラスはリーフノードとなり、合計時間と自己時間が等しくなります。ただし、コンパクトフィルターされたクラスがコールバックや呼び出しツリーのエントリポイント(例:現在のスレッドのrunメソッド)としてプロファイルされたクラスを呼び出す場合もあります。その場合、プロファイルされていないメソッドが消費した時間は呼び出しツリーの最初の利用可能な祖先ノードに伝播し、コンパクトフィルターされたクラスの自己時間に加算されます。
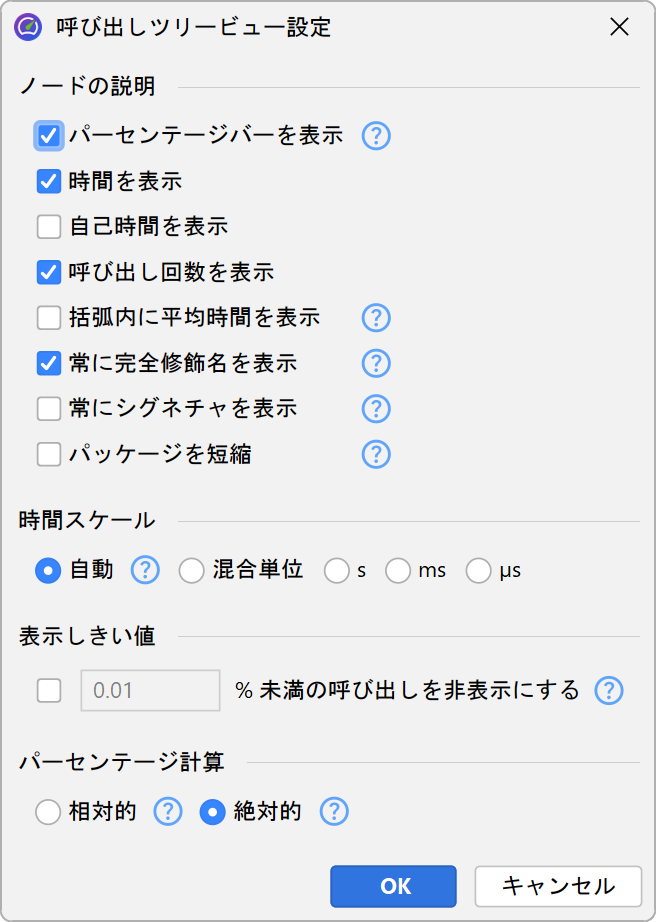
呼び出しツリーのパーセンテージバーは合計時間を示しますが、自己時間部分は異なる色で表示されます。メソッドは、同じレベルでオーバーロードされていない限り、シグネチャなしで表示されます。呼び出しツリーノードの表示は、ビュー設定ダイアログで様々にカスタマイズできます。例えば、自己時間や平均時間をテキストで表示したり、常にメソッドシグネチャを表示したり、使用する時間スケールを変更したりできます。また、パーセンテージ計算を親ノードの時間基準にすることも可能です。
スレッドステータス
呼び出しツリーの上部には、表示されるプロファイリングデータの種類や範囲を変更するためのビュー設定パラメータがあります。デフォルトでは、すべてのスレッドが累積されます。JProfilerはスレッドごとにCPUデータを保持しており、単一スレッドやスレッドグループを表示することも可能です。
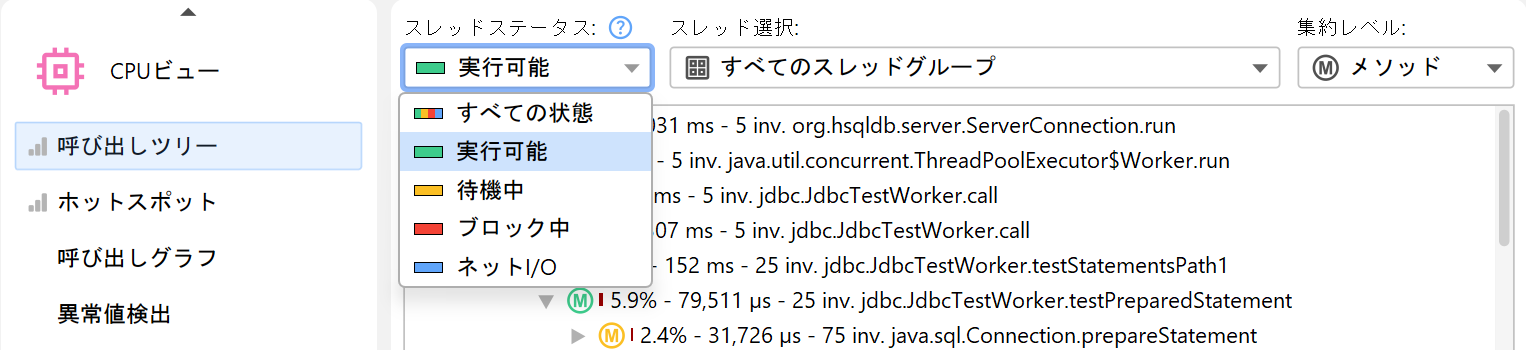
常に各スレッドには関連付けられたスレッドステータスがあります。スレッドがバイトコード命令を処理する準備ができている、または現在CPUコア上で実行中の場合、スレッドステータスは「Runnable」となります。このスレッド状態はパフォーマンスボトルネックを探す際に重要なため、デフォルトで選択されています。
あるいは、スレッドがObject.wait()やThread.sleep()の呼び出しでmonitorを待機している場合、スレッド状態は「Waiting」となります。synchronizedコードブロックの境界でmonitorの獲得を待ってブロックされている場合は「Blocking」状態です。
最後に、JProfilerはスレッドがネットワークデータを待っている時間を追跡する合成的な「Net I/O」状態を追加しています。これはサーバーやデータベースドライバの解析に重要であり、例えば遅いSQLクエリの調査などパフォーマンス分析に役立ちます。
ウォールクロック時間に興味がある場合は、スレッドステータス「すべての状態」を選択し、かつ単一スレッドを選択する必要があります。その場合のみ、System.currentTimeMillis()で計算した時間と比較できます。
選択したメソッドを別のスレッドステータスに移動したい場合は、メソッドトリガーと「スレッドステータスの上書き」トリガーアクション、または埋め込みやインジェクトプローブAPIのThreadStatusクラスを使って実現できます。
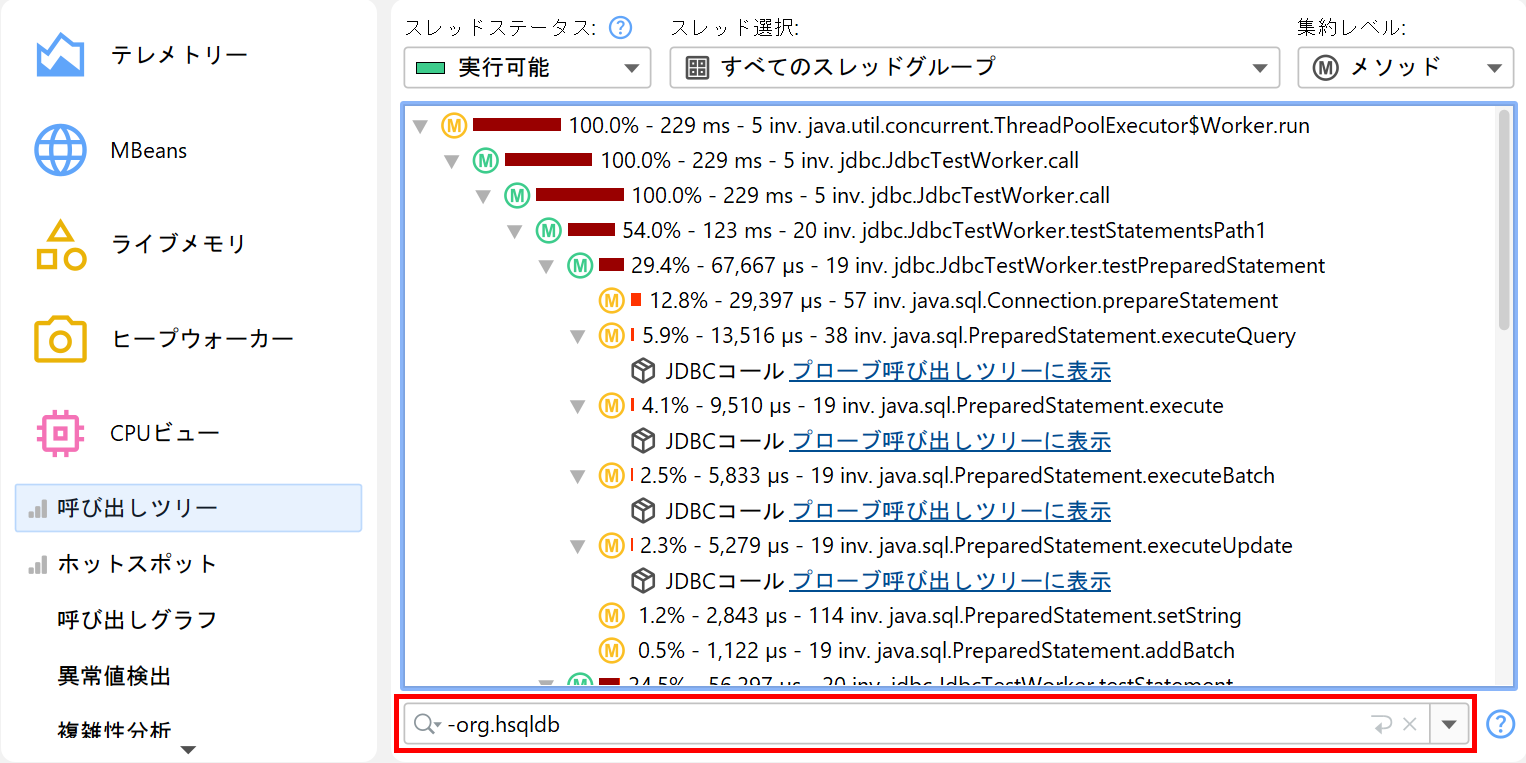
呼び出しツリー内のノード検索
呼び出しツリー内でテキストを検索する方法は2つあります。1つ目は、ビュー→検索メニューから呼び出すか、呼び出しツリーで直接入力を開始することで有効になるクイックサーチオプションです。一致する箇所がハイライトされ、PageDownを押すと検索オプションが利用できます。ArrowUpやArrowDownキーで異なる一致箇所を巡回できます。
もう一つの方法は、呼び出しツリー下部のビュー・フィルターを使ってメソッド、クラス、パッケージを検索することです。ここではカンマ区切りのフィルター式を入力できます。「-」で始まる式は無視フィルター、「!」で始まる式はコンパクトフィルター、それ以外はプロファイルされたフィルターと同じ動作です。フィルター設定と同様に、初期フィルタータイプによってクラスがデフォルトで含まれるか除外されるかが決まります。
ビュー設定テキストフィールド左のアイコンをクリックすると、ビュー・フィルターオプションが表示されます。デフォルトでは一致モードは「含む」ですが、特定のパッケージを検索する場合は「で始まる」が適していることもあります。
フレームグラフ
呼び出しツリーをフレームグラフとして表示することもできます。関連する呼び出しツリー分析を実行することで、呼び出しツリー全体または一部をフレームグラフとして表示できます。
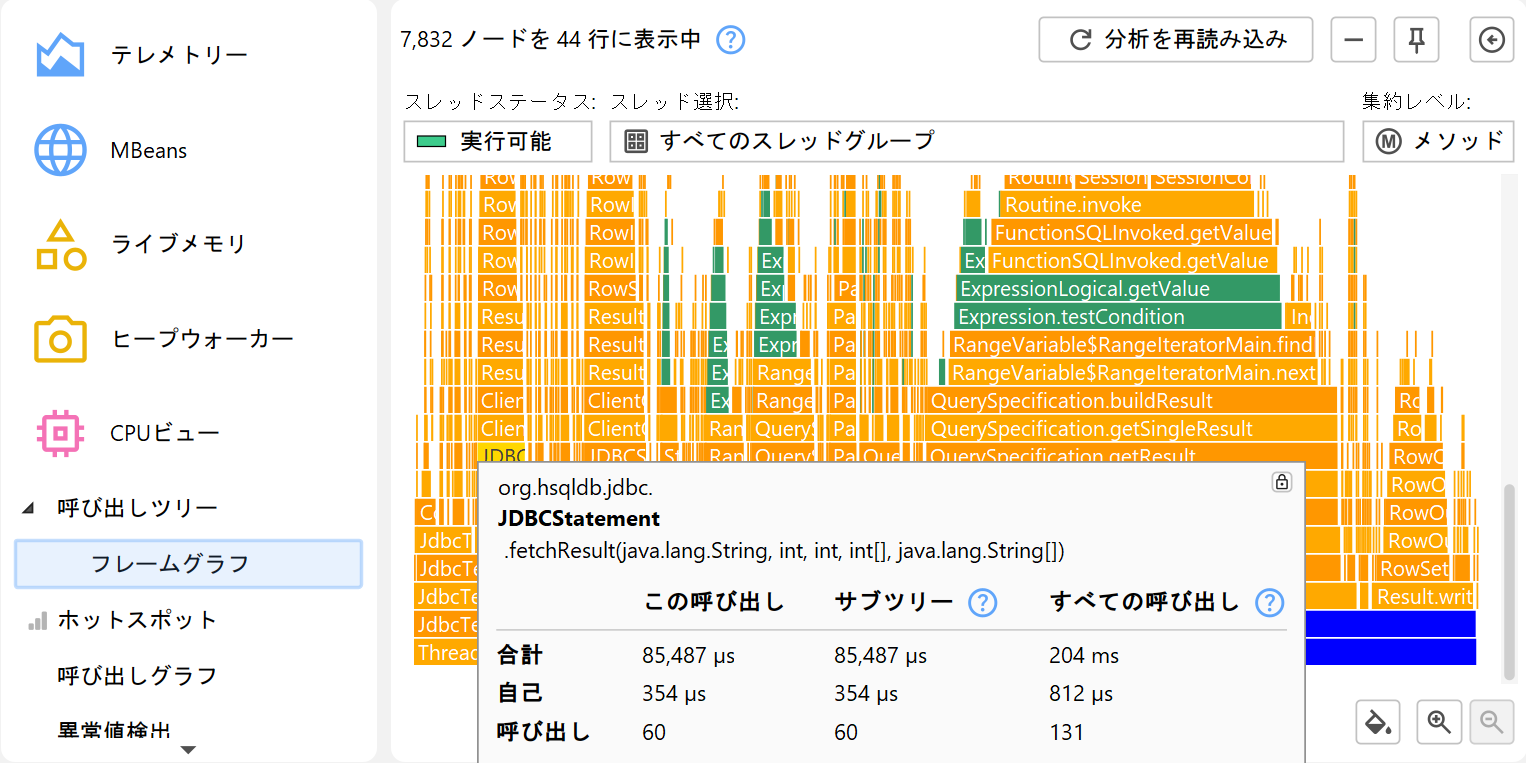
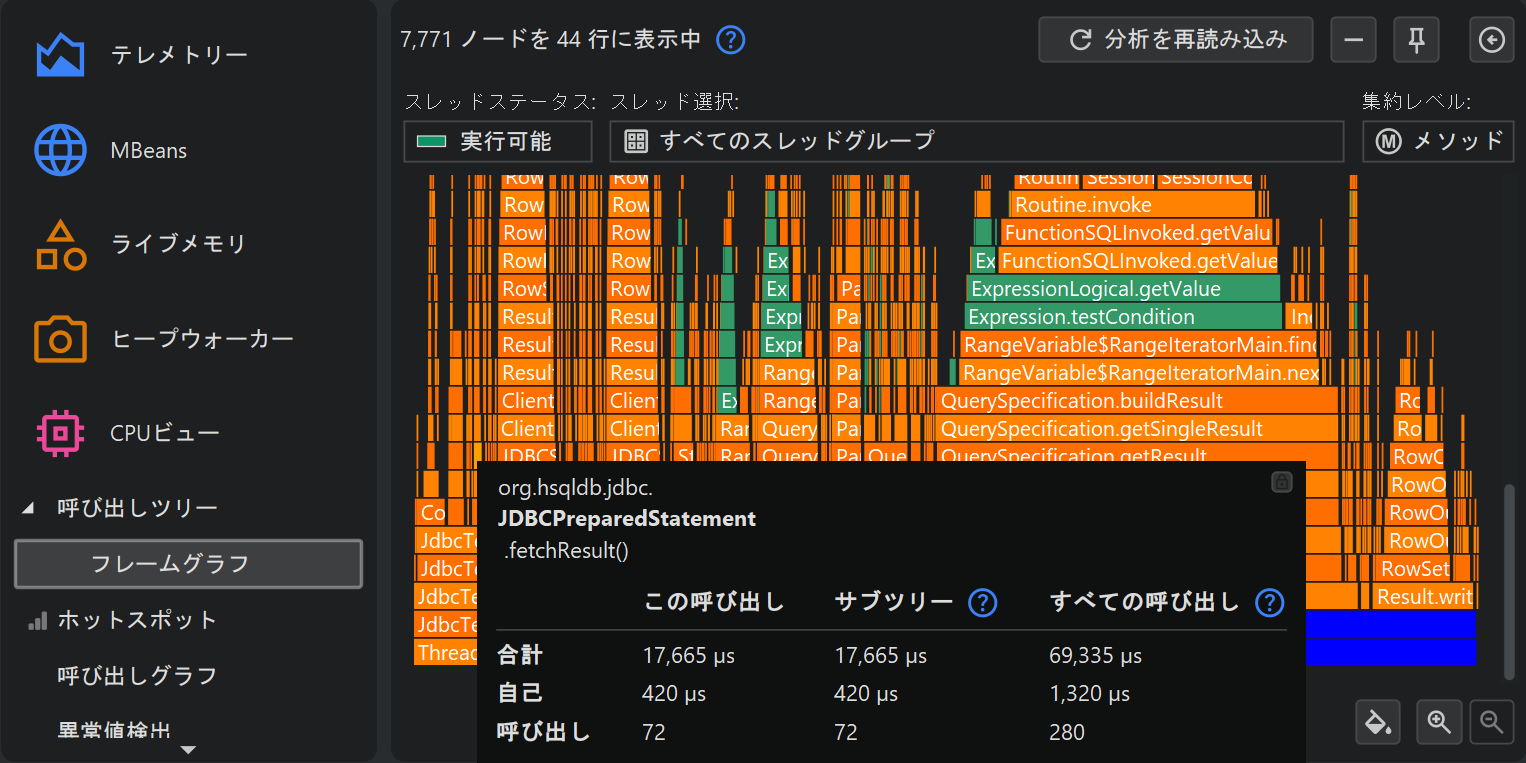
フレームグラフは呼び出しツリー全体の内容を1つの画像で示します。コールはフレームグラフの下部から始まり、上部に向かって伝播します。各ノードの子ノードは直上の行に配置されます。子ノードはアルファベット順に並び、親ノードの中央に配置されます。各ノードで消費された自己時間のため、「炎」は上に行くほど細くなります。ノードの詳細はツールチップに表示され、テキストを選択してクリップボードにコピーできます。
マウスカーソル付近のツールチップが分析の邪魔になる場合は、右上のボタンでロックし、上部のグリッパーで便利な位置に移動できます。同じボタンやフレームグラフのダブルクリックでツールチップを閉じられます。
フレームグラフは情報密度が非常に高いため、関心のあるノードとその子孫階層にフォーカスして表示内容を絞り込む必要がある場合があります。ズームインするだけでなく、ノードをダブルクリックしたりコンテキストメニューを使ったりして新しいルートノードを設定できます。ルートを何度も変更した場合は、ルート履歴で戻ることもできます。
フレームグラフを分析するもう一つの方法は、クラス名やパッケージ名、任意の検索語に基づいてカラー化を追加することです。カラー化はコンテキストメニューから追加でき、カラー化ダイアログで管理できます。各ノードには最初に一致したカラー化が適用されます。カラー化はプロファイリングセッション間で保持され、すべてのセッションとスナップショットでグローバルに使用されます。
カラー化に加えて、クイックサーチ機能で関心のあるノードを検索できます。カーソルキーで一致結果を巡回し、現在ハイライトされた一致箇所のツールチップが表示されます。
ホットスポット
アプリケーションの動作が遅い場合、最も時間を消費しているメソッドを特定したいはずです。呼び出しツリーでこれらのメソッドを直接見つけられる場合もありますが、多くの場合はリーフノードが膨大な数になり、うまくいきません。
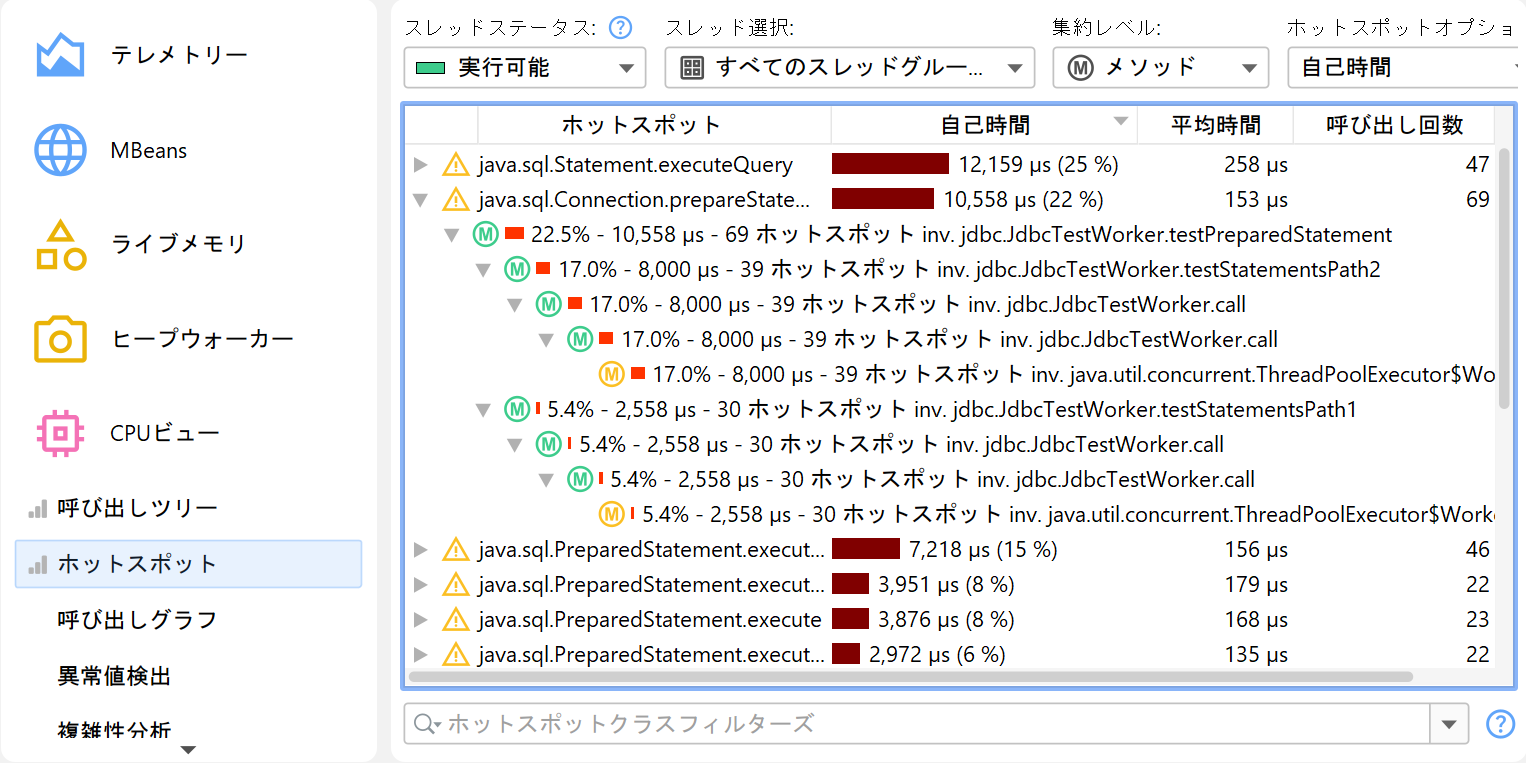
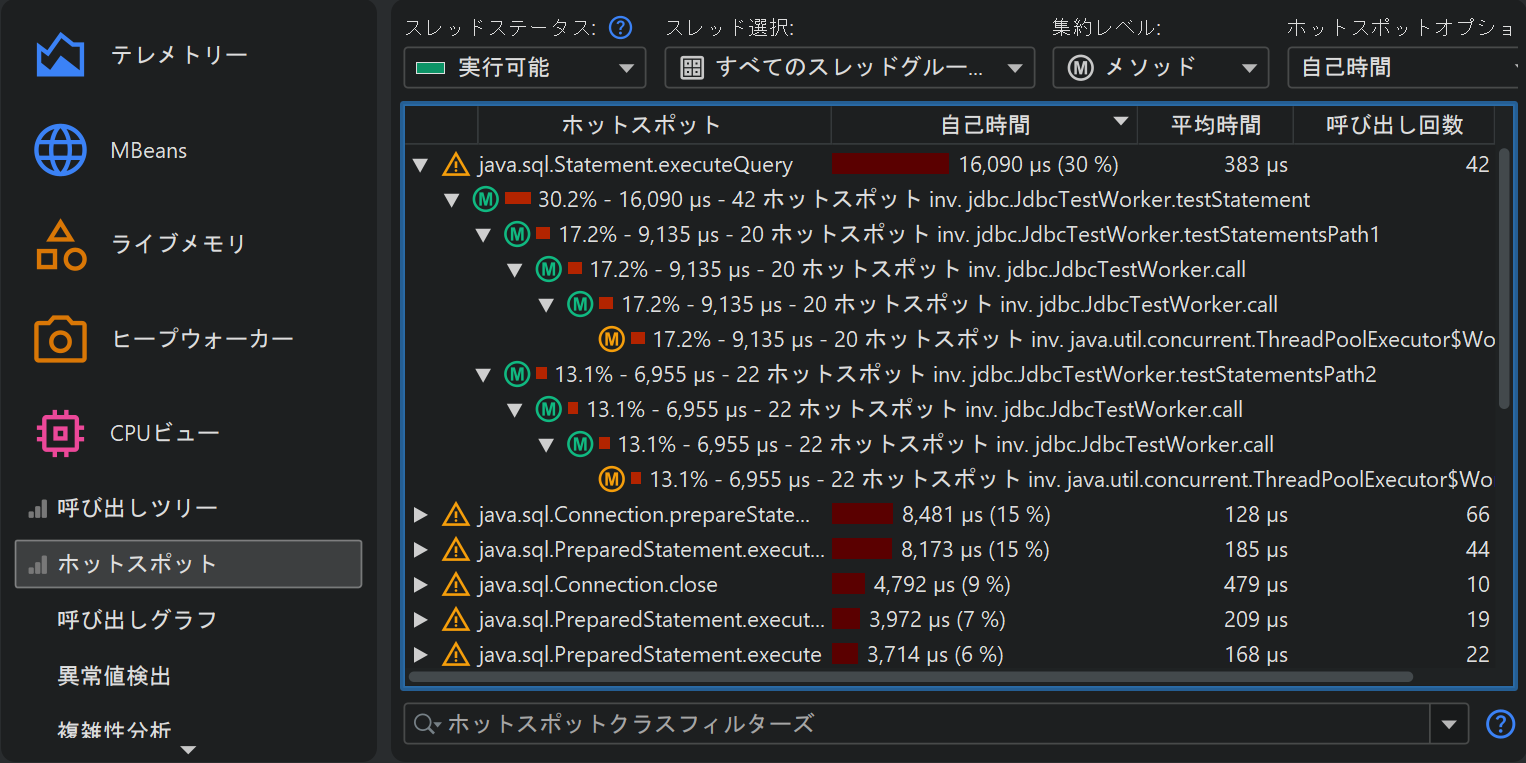
その場合、呼び出しツリーの逆、すなわちすべての異なる呼び出しスタックから累積された自己時間でソートされたメソッドのリストと、そのメソッドがどのように呼び出されたかを示すバックトレースが必要です。ホットスポットツリーでは、リーフがエントリポイント(例:アプリケーションのmainメソッドやスレッドのrunメソッド)となり、最も深いノードからトップレベルノードへとコールが伝播します。
バックトレースの呼び出し回数や実行時間はメソッドノード自体ではなく、そのパス上でトップレベルのホットスポットノードが呼び出された回数を示しています。これは重要なポイントです。一見するとノードの情報がそのノードへの呼び出し回数を示しているように思えますが、ホットスポットツリーではその情報はノードがトップレベルノードに与えた寄与を示します。つまり、こう読み取ります:「この逆呼び出しスタック上で、トップレベルのホットスポットはn回、合計t秒呼び出された」。
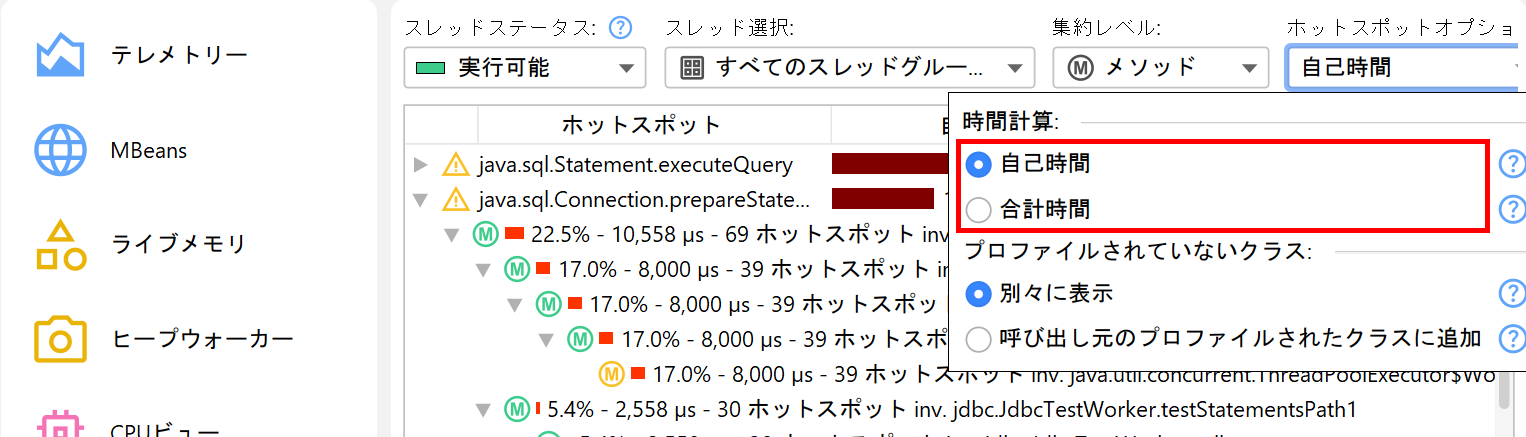
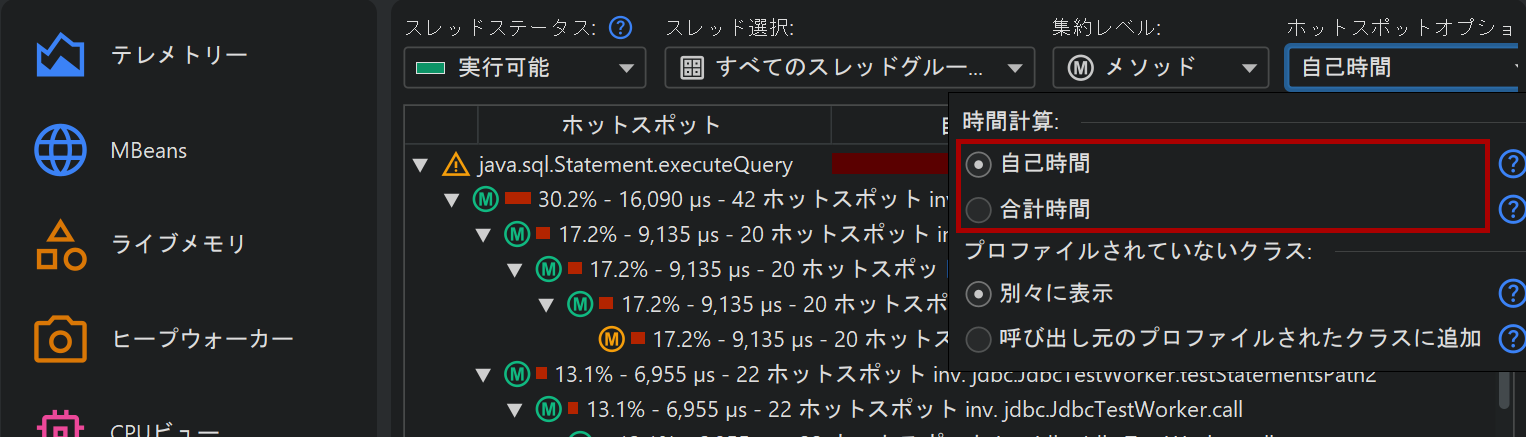
デフォルトでは、ホットスポットは自己時間から計算されます。合計時間から計算することも可能ですが、パフォーマンスボトルネックの分析にはあまり役立ちません。すべてのメソッドのリストを見たい場合には有用です。ホットスポットビューはオーバーヘッドを減らすために表示するメソッド数に上限があります。そのため、探しているメソッドが表示されない場合は、下部のビュー・フィルターでパッケージやクラスを絞り込んでください。呼び出しツリーと異なり、ホットスポットビューのフィルターはトップレベルノードのみを対象とします。ホットスポットビューのカットオフはグローバルではなく、表示されているクラスごとに適用されるため、フィルター適用後に新しいノードが現れることもあります。
ホットスポットとフィルター
ホットスポットの概念は絶対的なものではなく、呼び出しツリーフィルターに依存します。呼び出しツリーフィルターが全くない場合、最大のホットスポットはJREのコアクラス(文字列操作、I/Oルーチン、コレクション操作など)になることがほとんどです。これらのホットスポットは、これらのメソッドの呼び出しを直接制御できず、また高速化の手段もないため、あまり有用ではありません。
有用なホットスポットとは、自分のクラス内のメソッド、または自分が直接呼び出すライブラリクラスのメソッドです。呼び出しツリーフィルターの観点では、自分のクラスは「プロファイルされた」フィルター、ライブラリクラスは「コンパクト」フィルターに該当します。
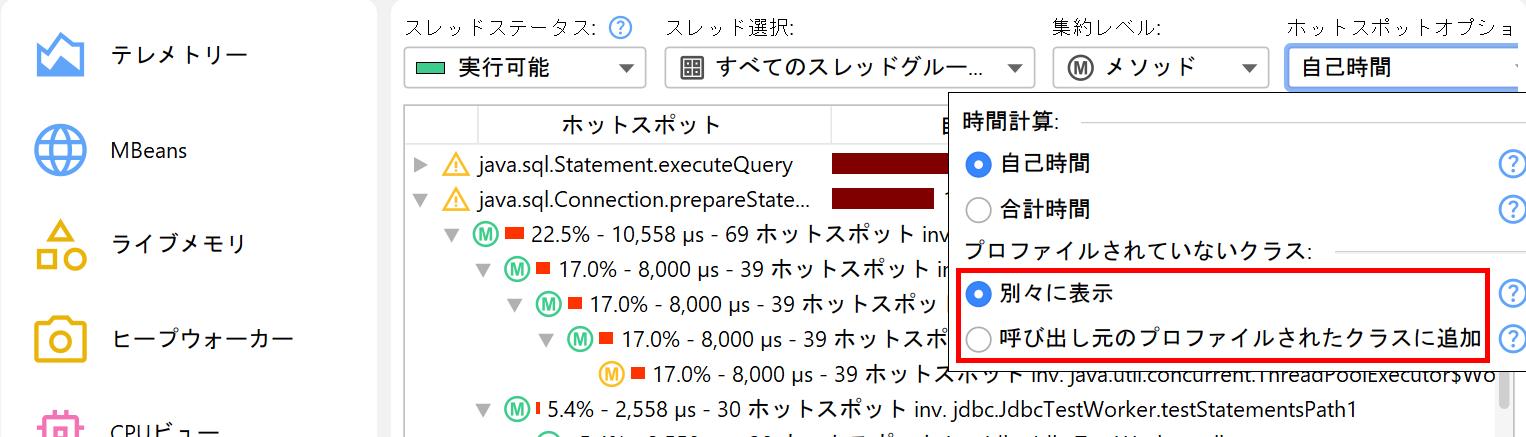
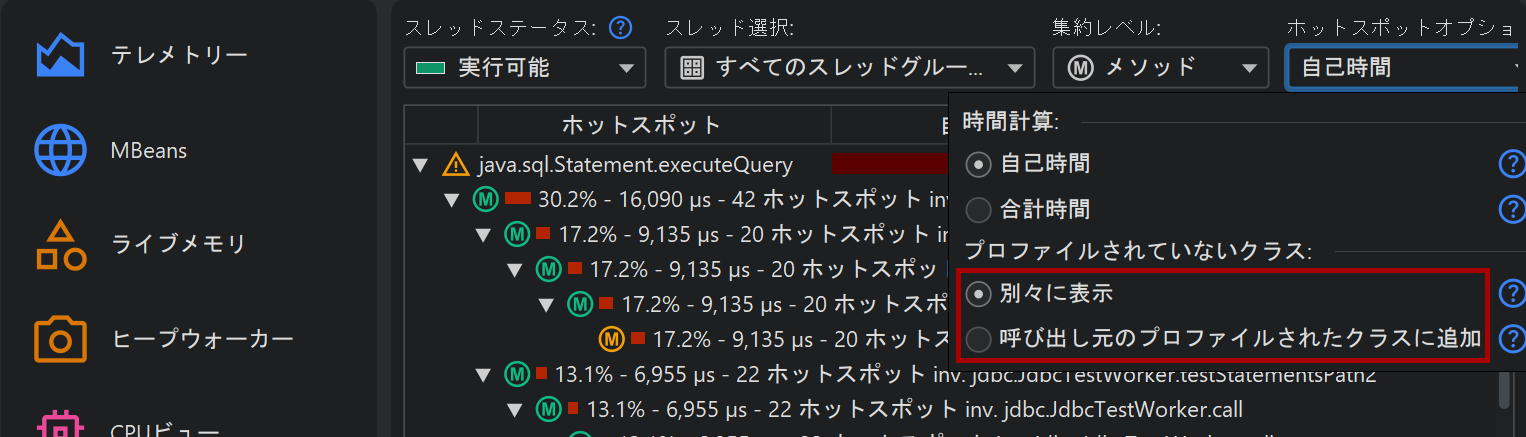
パフォーマンス問題を解決する際、ライブラリ層を除外して自分のクラスだけを見たい場合があります。呼び出しツリーで呼び出し元のプロファイルされたクラスに追加ラジオボタンをホットスポットオプションポップアップで選択することで、すぐにその視点に切り替えられます。
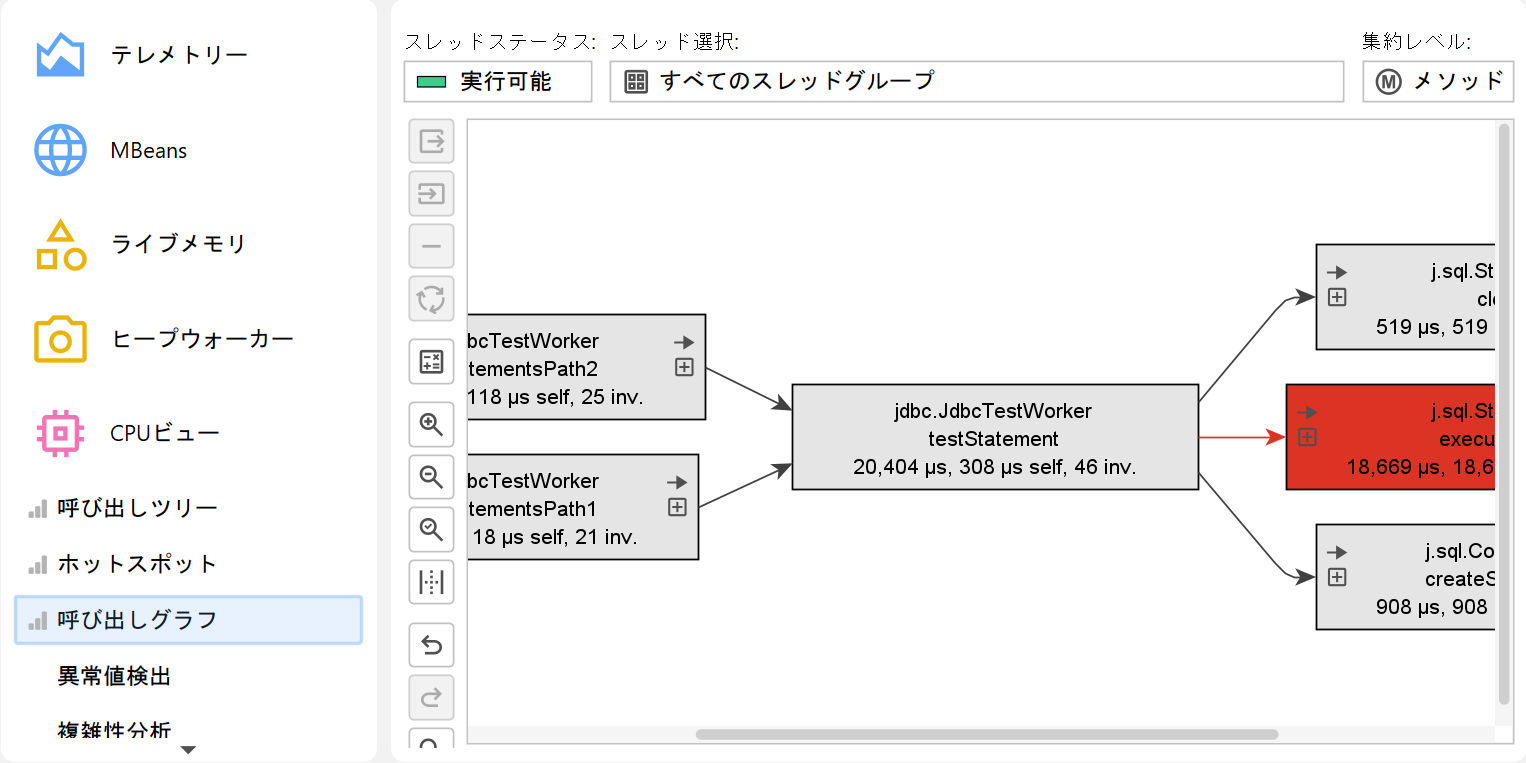
呼び出しグラフ
呼び出しツリーやホットスポットビューでは、各ノードが複数回出現することがあります。特に再帰呼び出しがある場合です。状況によっては、各メソッドが一度だけ現れ、すべての入出力コールが可視化されるメソッド中心の統計に興味があることもあります。そのようなビューはグラフで表示するのが最適であり、JProfilerではこれを呼び出しグラフと呼びます。
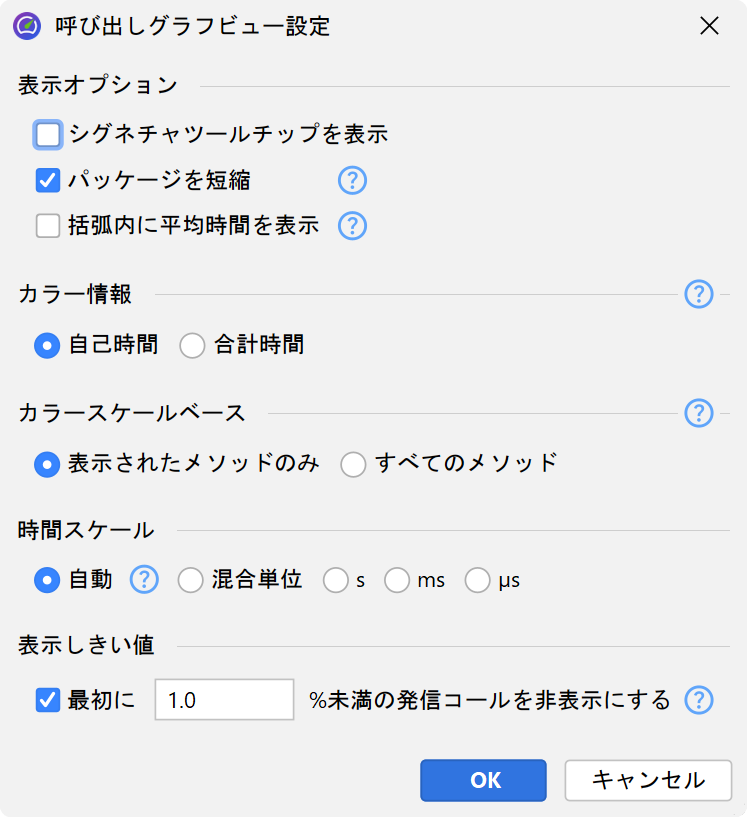
グラフの欠点は、ツリーに比べて視覚的な情報密度が低いことです。そのため、JProfilerはデフォルトでパッケージ名を省略し、合計時間の1%未満のアウトゴーイングコールは非表示にします。ノードにアウトゴーイング展開アイコンがあれば、再度クリックしてすべてのコールを表示できます。ビュー設定でこの閾値やパッケージ省略の有無を設定可能です。
呼び出しグラフを展開すると、特に複数回バックトラックした場合にすぐに複雑になります。undo機能を使ってグラフの以前の状態に戻せます。呼び出しツリーと同様に、呼び出しグラフでもクイックサーチが利用できます。グラフ上で入力を開始すると検索が始まります。
グラフとツリービューにはそれぞれ利点と欠点があるため、状況によってビュータイプを切り替えたくなることもあります。インタラクティブセッションでは、呼び出しツリーとホットスポットビューはライブデータを表示し、定期的に更新されます。一方、呼び出しグラフはリクエスト時に計算され、ノードを展開しても内容は変わりません。呼び出しツリーの呼び出しグラフで表示アクションを使うと、新しい呼び出しグラフが計算され、選択したメソッドが表示されます。
グラフから呼び出しツリーへの切り替えはできません。なぜなら、後の時点ではデータが通常比較できなくなるためです。ただし、呼び出しグラフではビュー→分析アクションで呼び出しツリー分析を提供しており、選択したノードごとに累積されたアウトゴーイングコールやバックトレースのツリーを表示できます。
基本を超えて
呼び出しツリー、ホットスポットビュー、呼び出しグラフの組み合わせには多くの高度な機能があり、別の章で詳しく説明しています。また、別途紹介している他の高度なCPUビューもあります。