CPU 및 메모리 프로파일링은 주로 객체와 메서드 호출에 초점을 맞추며, 이는 JVM에서 애플리케이션의 기본 빌딩 블록입니다. 일부 기술에서는 실행 중인 애플리케이션에서 의미론적 데이터를 추출하여 프로파일러에 표시하는 보다 상위 수준의 접근 방식이 필요합니다.
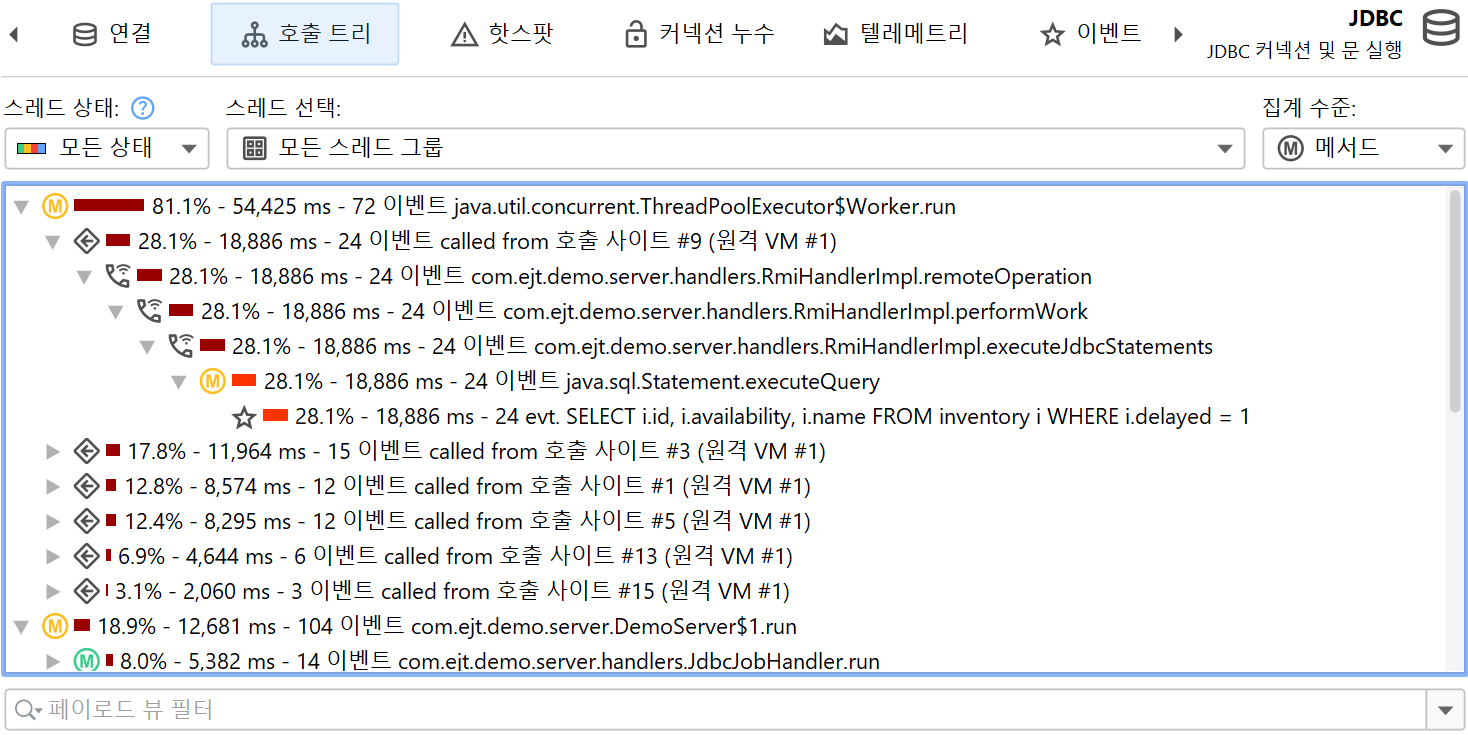
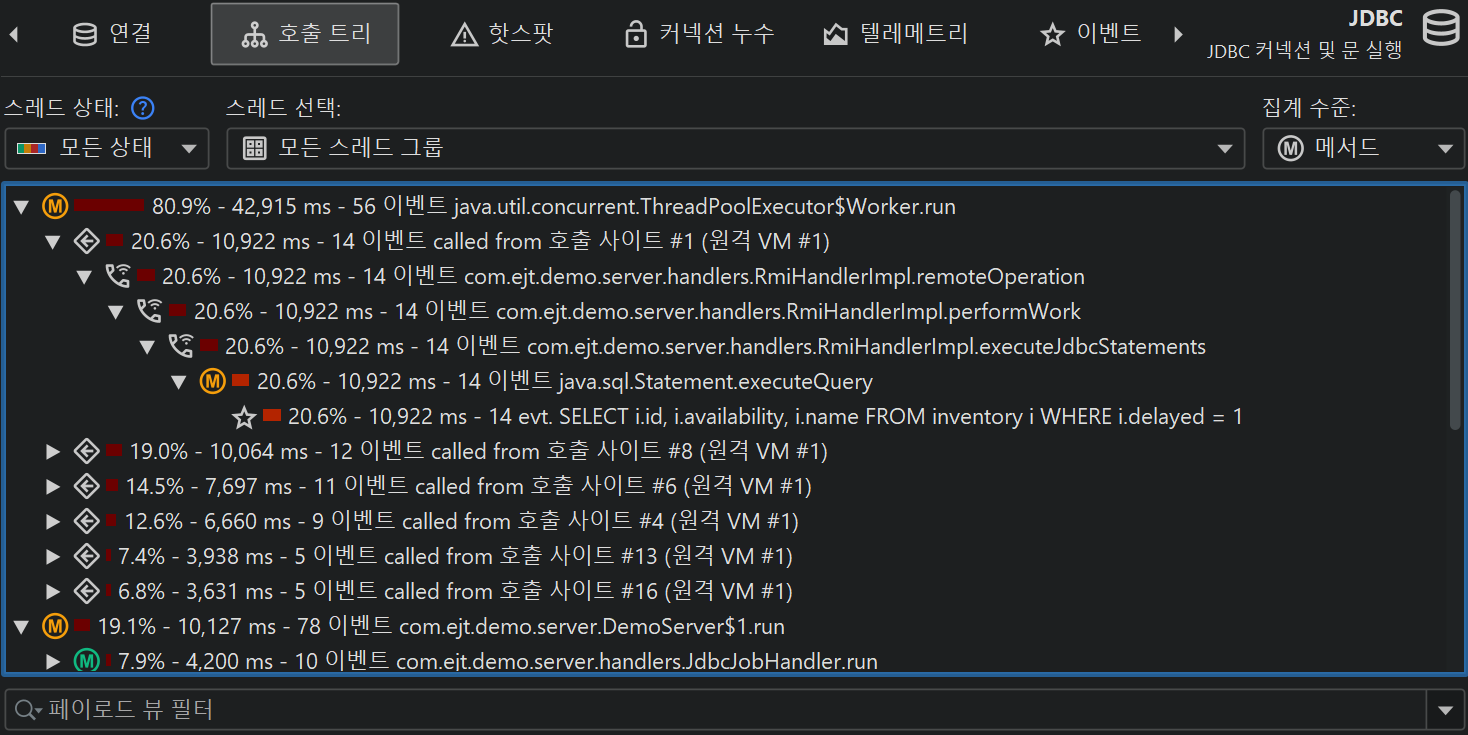
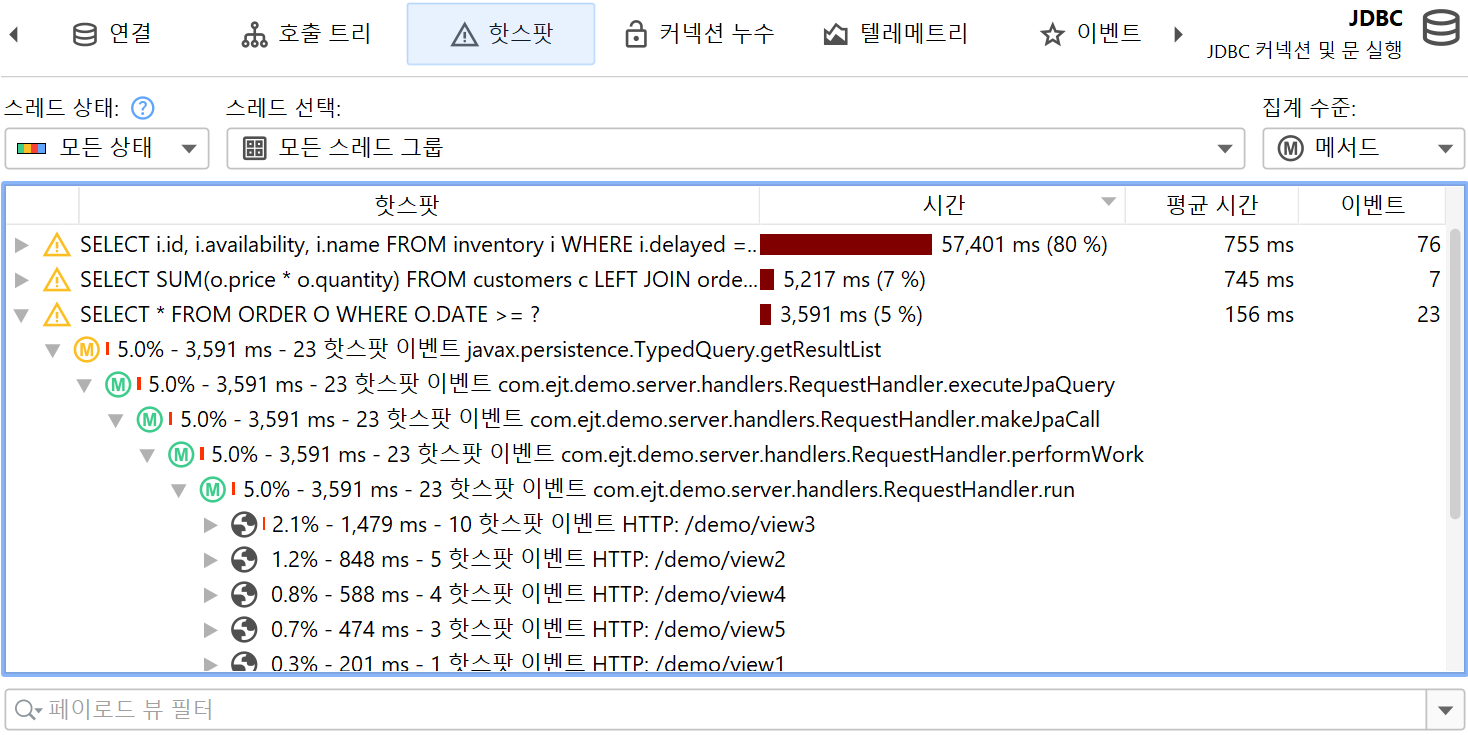
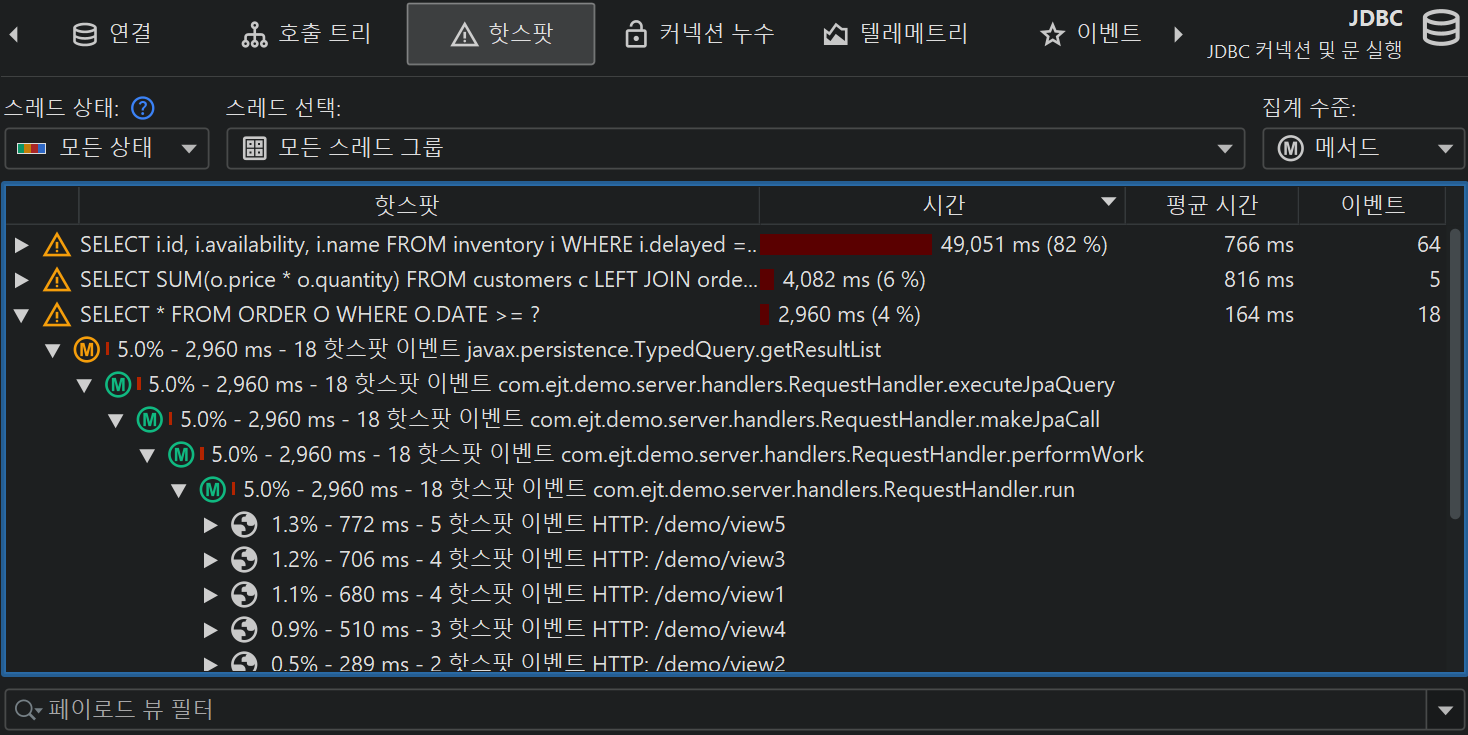
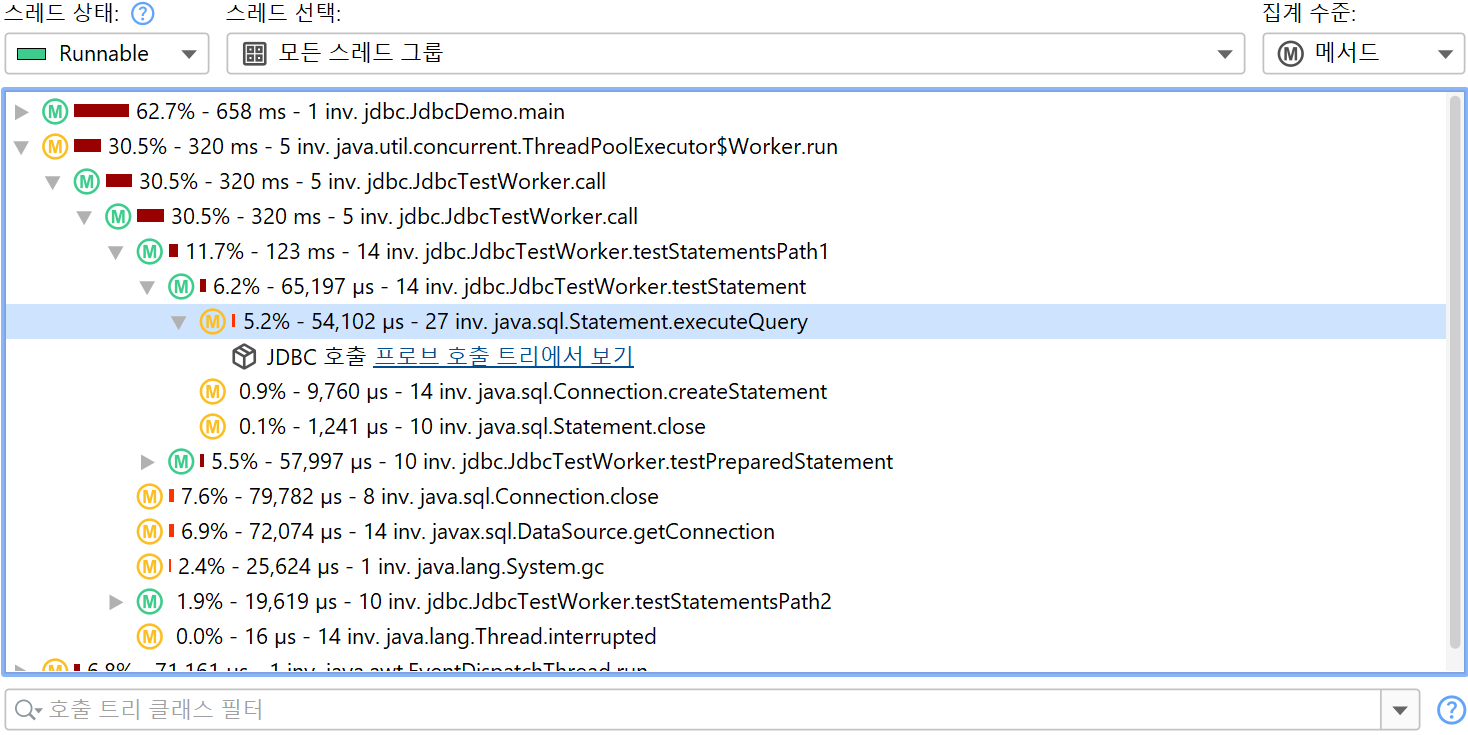
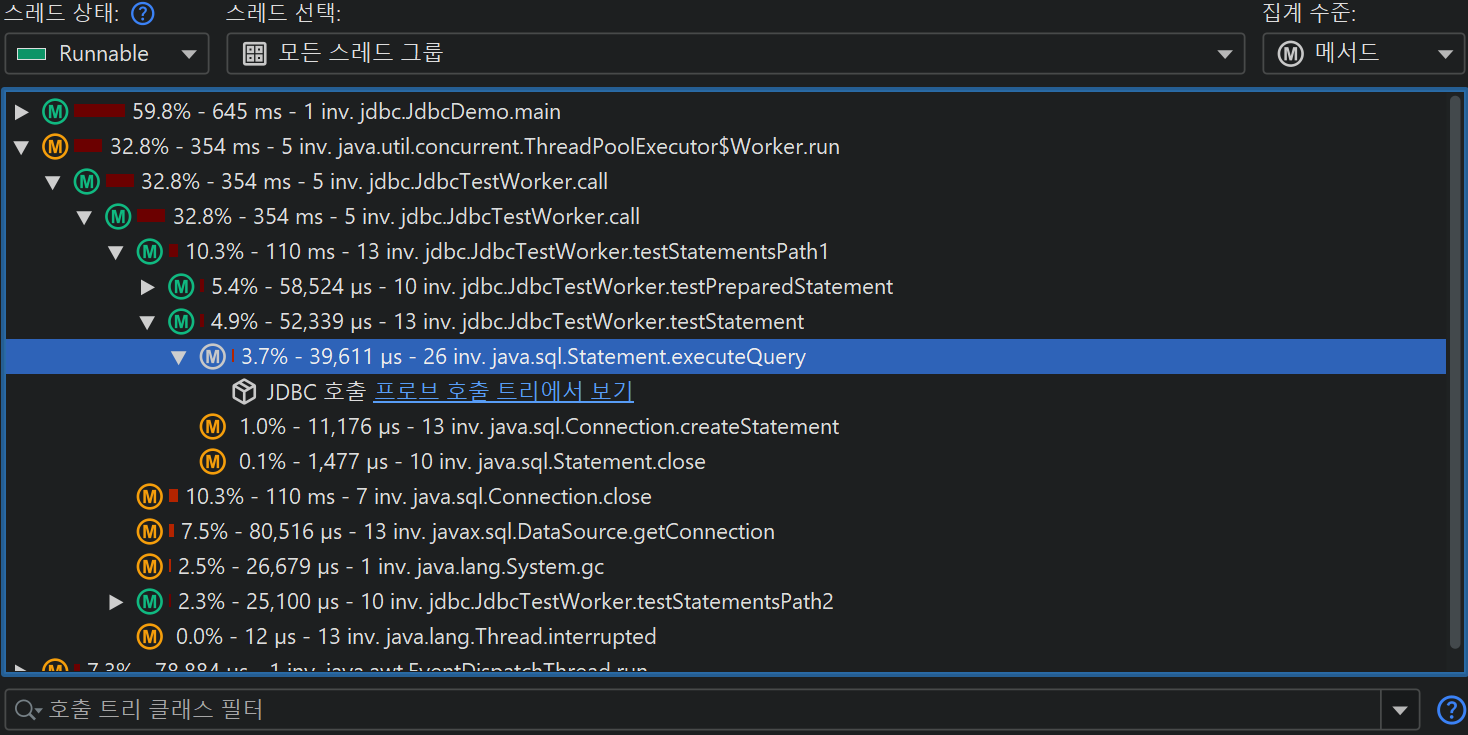
가장 대표적인 예는 JDBC를 통한 데이터베이스 호출을 프로파일링하는 것입니다. 호출 트리는 JDBC API를 사용할 때와 해당 호출이 얼마나 오래 걸리는지 보여줍니다. 그러나 각 호출마다 서로 다른 SQL 문이 실행될 수 있으며, 어떤 호출이 성능 병목의 원인인지 알 수 없습니다. 또한 JDBC 호출은 애플리케이션의 여러 위치에서 발생할 수 있으므로, 일반 호출 트리에서 일일이 찾아보는 대신 모든 데이터베이스 호출을 한 번에 보여주는 뷰가 중요합니다.
이 문제를 해결하기 위해 JProfiler는 JRE의 주요 하위 시스템에 대한 여러 프로브를 제공합니다. 프로브는 특정 클래스에 계측을 추가하여 데이터를 수집하고, "Databases" 및 "JEE & Probes" 뷰 섹션의 전용 뷰에 표시합니다. 또한 프로브는 호출 트리에 데이터를 주석으로 추가하여 일반적인 CPU 프로파일링과 상위 수준의 데이터를 동시에 볼 수 있습니다.
JProfiler에서 직접 지원하지 않는 기술에 대한 추가 정보를 얻고 싶다면, 사용자 정의 프로브를 작성할 수 있습니다. 일부 라이브러리, 컨테이너 또는 데이터베이스 드라이버는 자체 임베디드 프로브를 제공할 수 있으며, 애플리케이션에서 사용될 때 JProfiler에서 자동으로 인식됩니다.
프로브 이벤트
프로브는 오버헤드를 추가하므로 기본적으로 기록되지 않으며, 각 프로브마다 별도로 녹화를 시작해야 합니다. 이는 수동 또는 자동으로 설정할 수 있습니다.
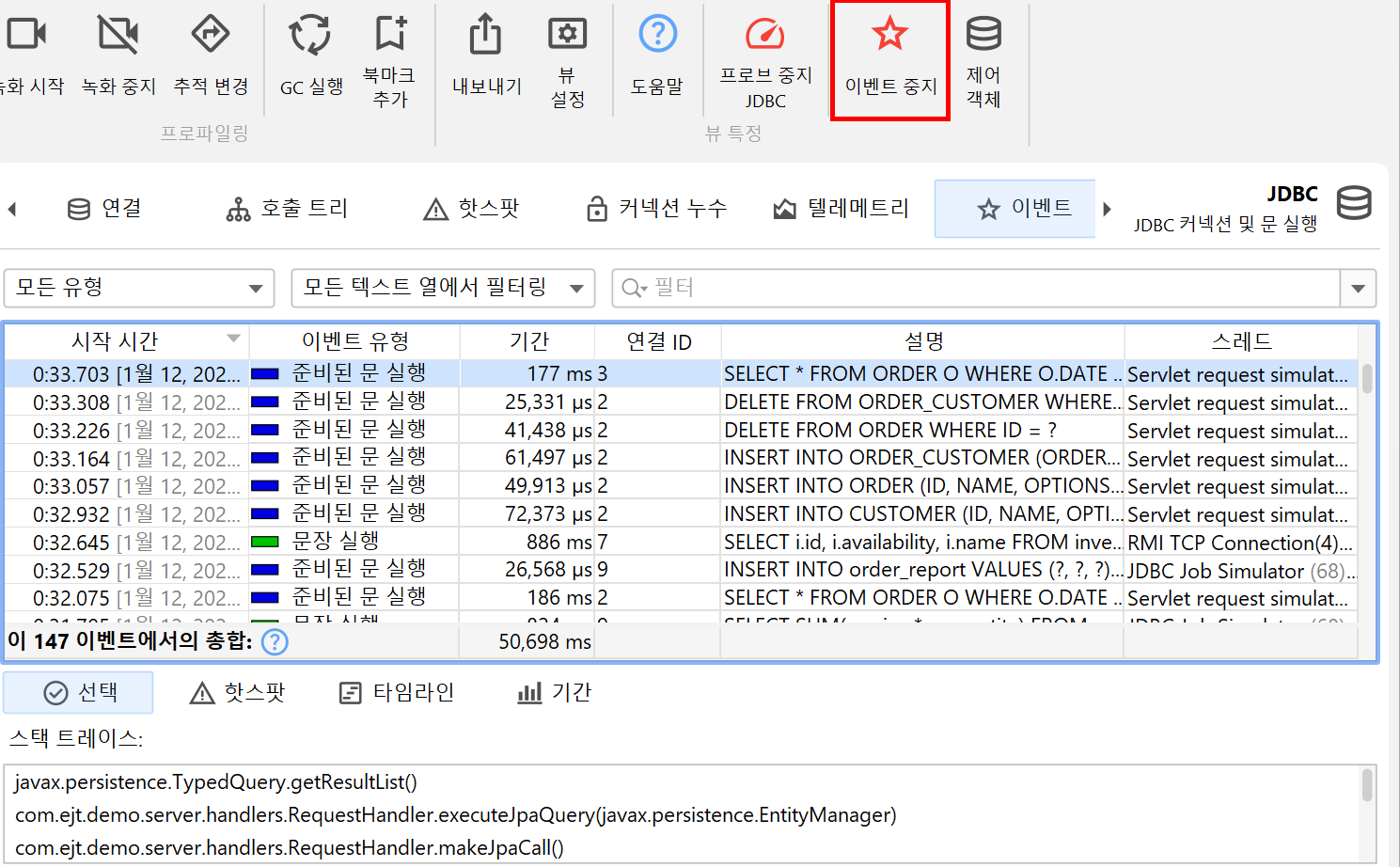
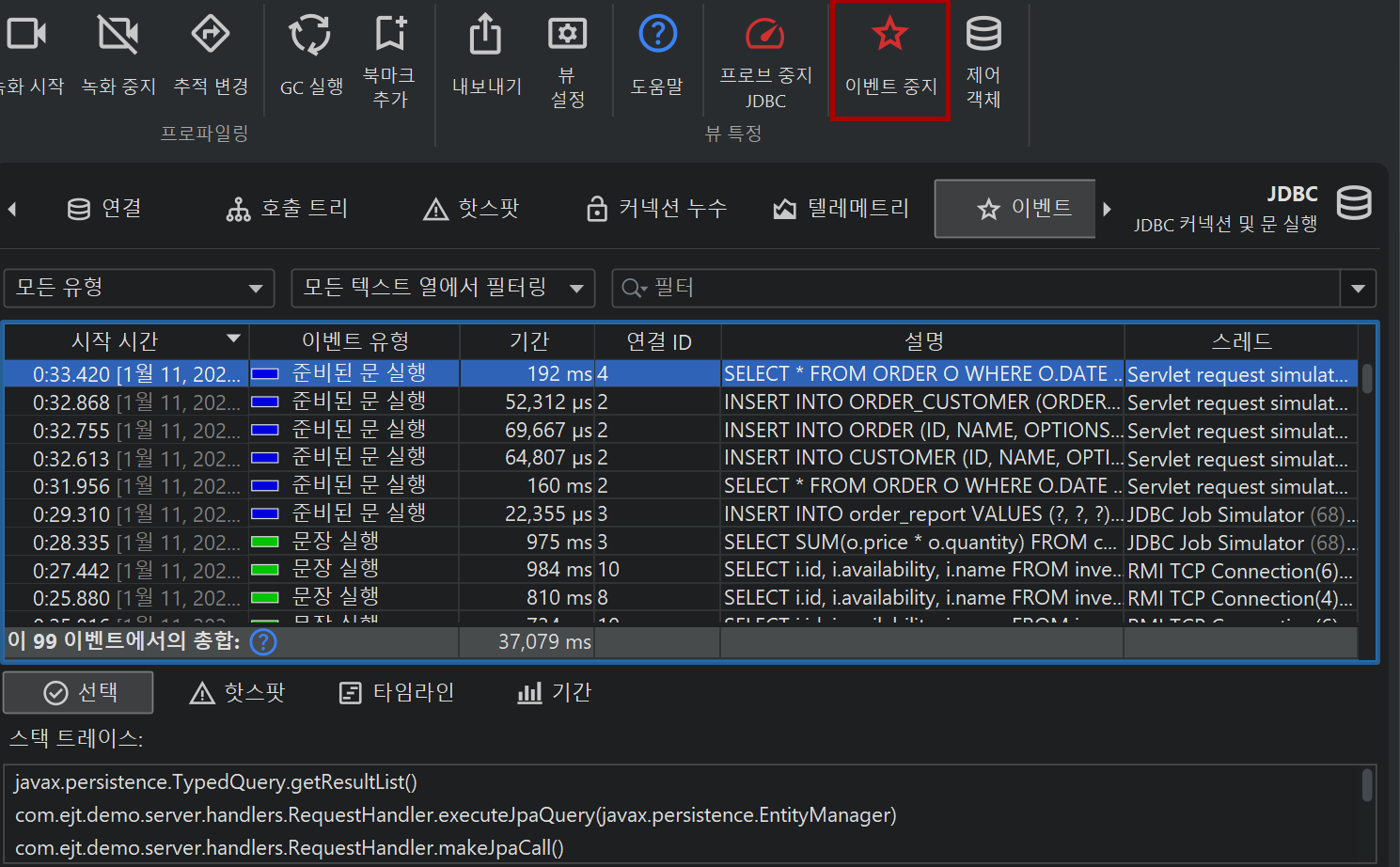
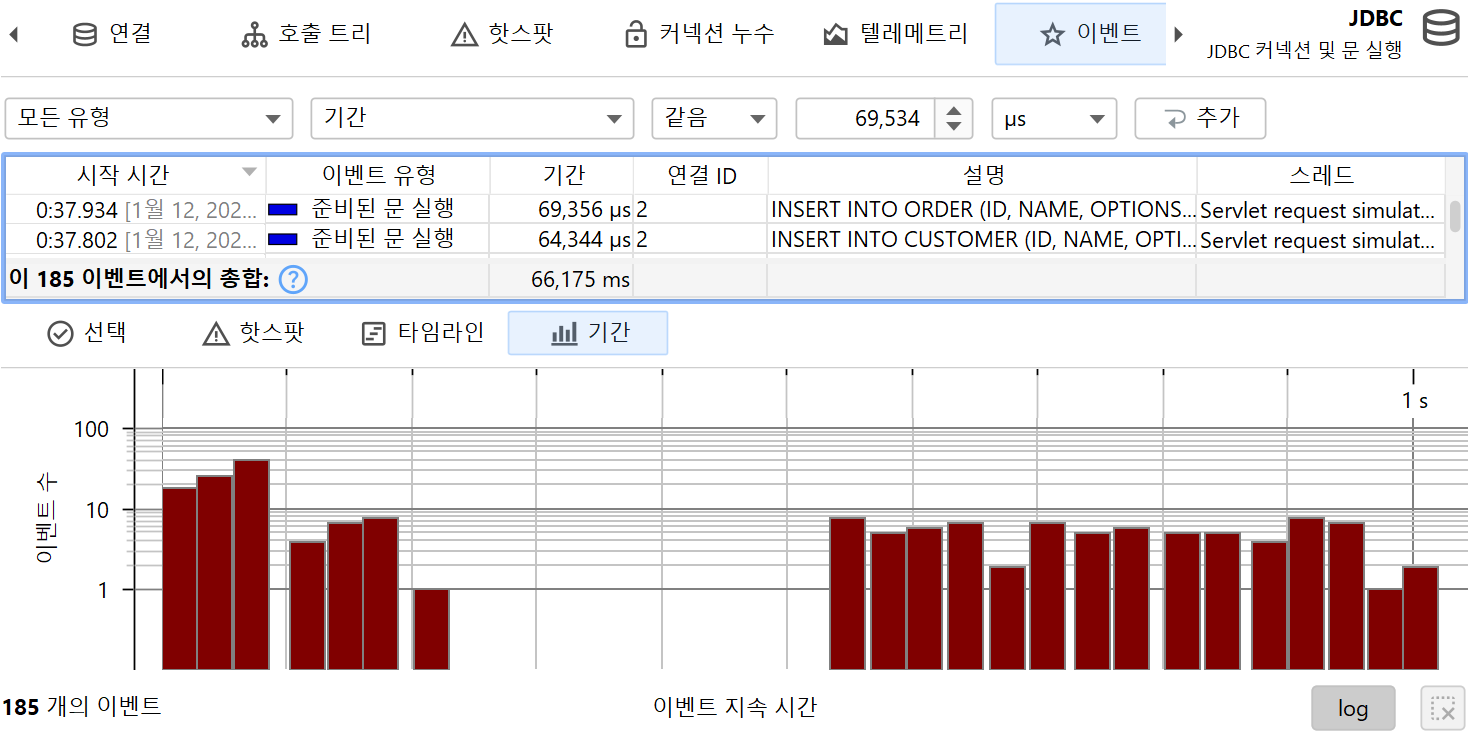
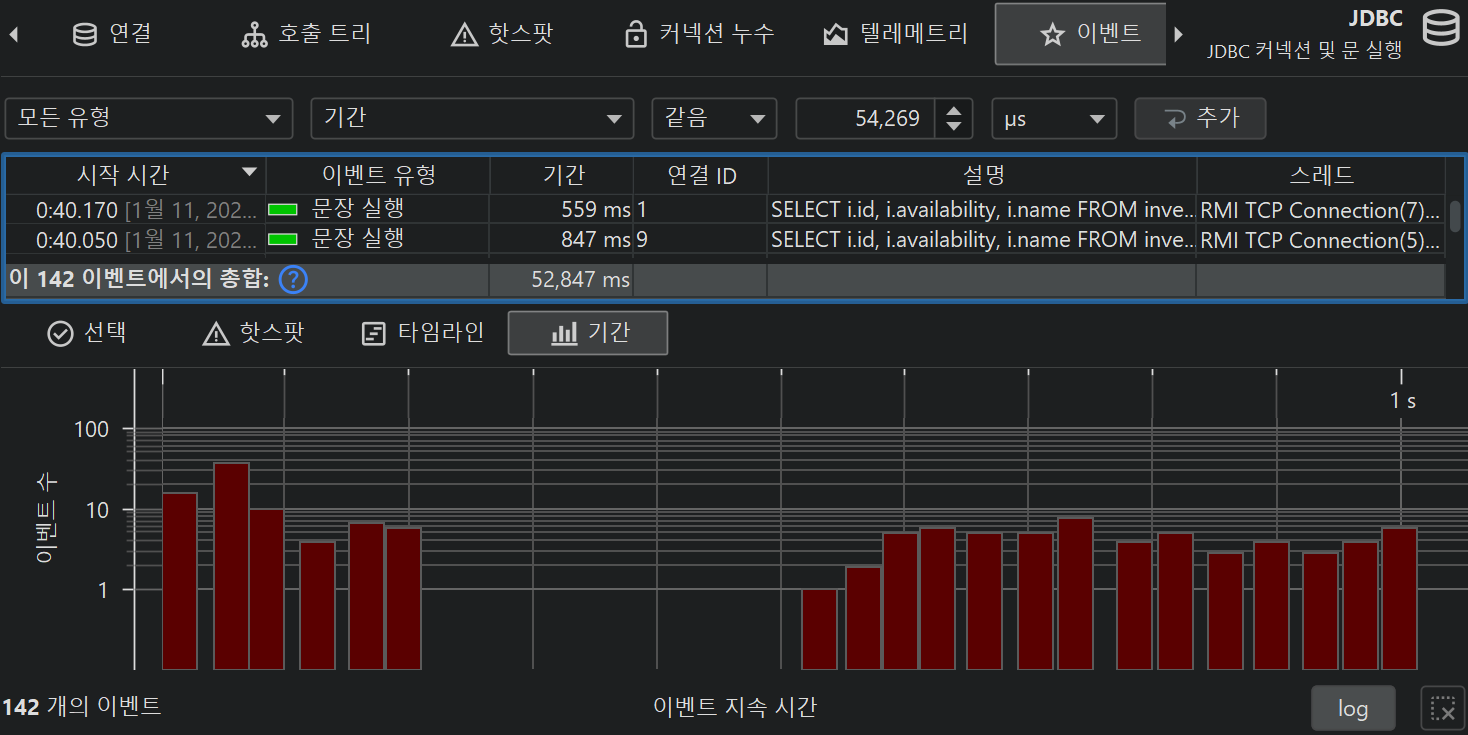
프로브의 기능에 따라 프로브 데이터는 여러 뷰에 표시됩니다. 가장 낮은 수준은 프로브 이벤트입니다. 다른 뷰에서는 프로브 이벤트가 누적된 데이터를 보여줍니다. 기본적으로 프로브 이벤트는 프로브가 녹화 중이어도 유지되지 않습니다. 단일 이벤트가 중요할 때는 프로브 이벤트 뷰에서 별도로 기록할 수 있습니다. 파일 프로브와 같이 이벤트가 매우 자주 발생하는 경우에는 일반적으로 단일 이벤트 기록을 권장하지 않습니다. 반면, "HTTP server" 프로브나 JDBC 프로브와 같이 이벤트 발생 빈도가 낮은 경우에는 단일 이벤트 기록이 적합할 수 있습니다.
프로브 이벤트는 메서드 파라미터, 반환값, 계측된 객체, 발생한 예외 등 다양한 소스에서 프로브 문자열을 캡처합니다. 프로브는 여러 메서드 호출에서 데이터를 수집할 수 있습니다. 예를 들어, JDBC 프로브는 실제 SQL 문자열을 구성하기 위해 prepared statement의 모든 setter 호출을 가로채야 합니다. 프로브 문자열은 프로브가 측정하는 상위 수준 하위 시스템에 대한 기본 정보입니다. 또한 이벤트에는 시작 시간, 선택적 지속 시간, 관련 스레드, 스택 트레이스가 포함됩니다.
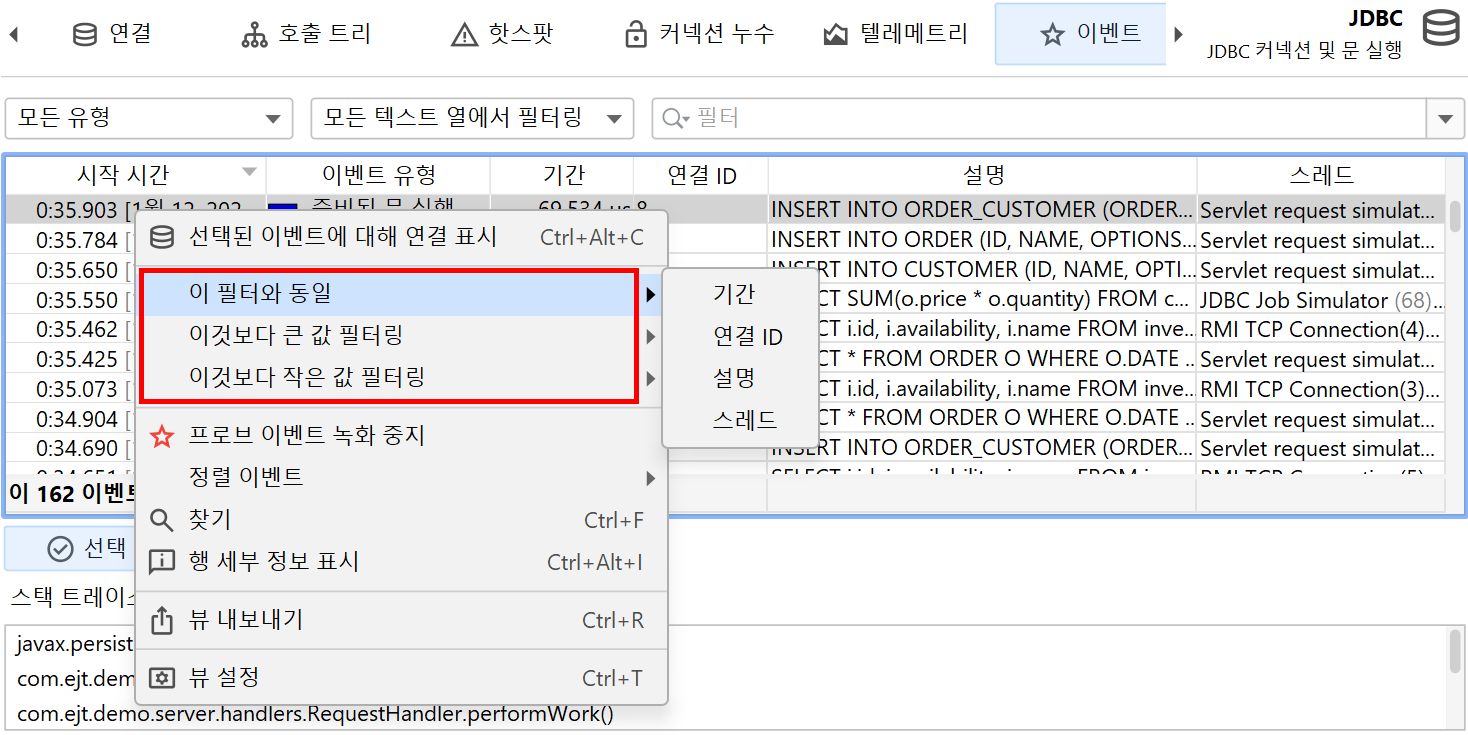
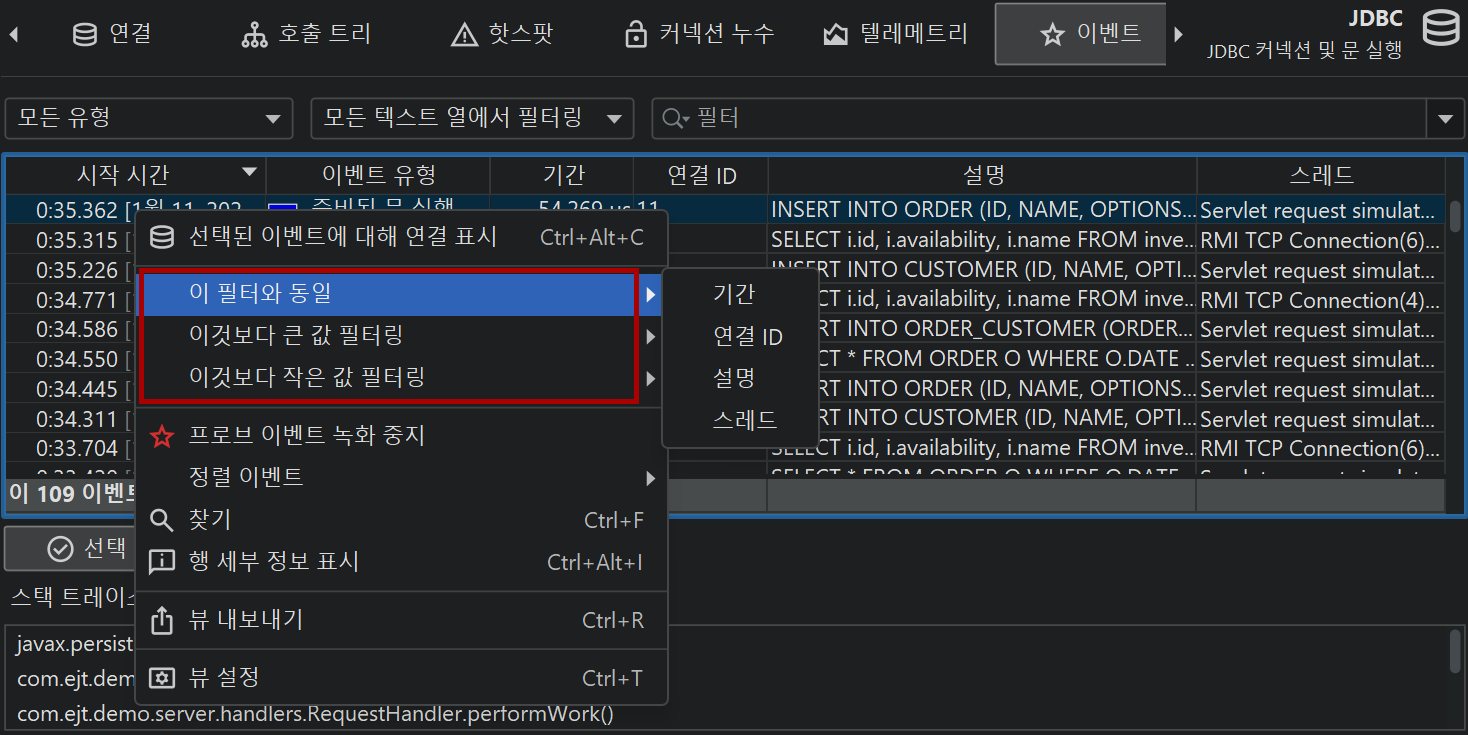
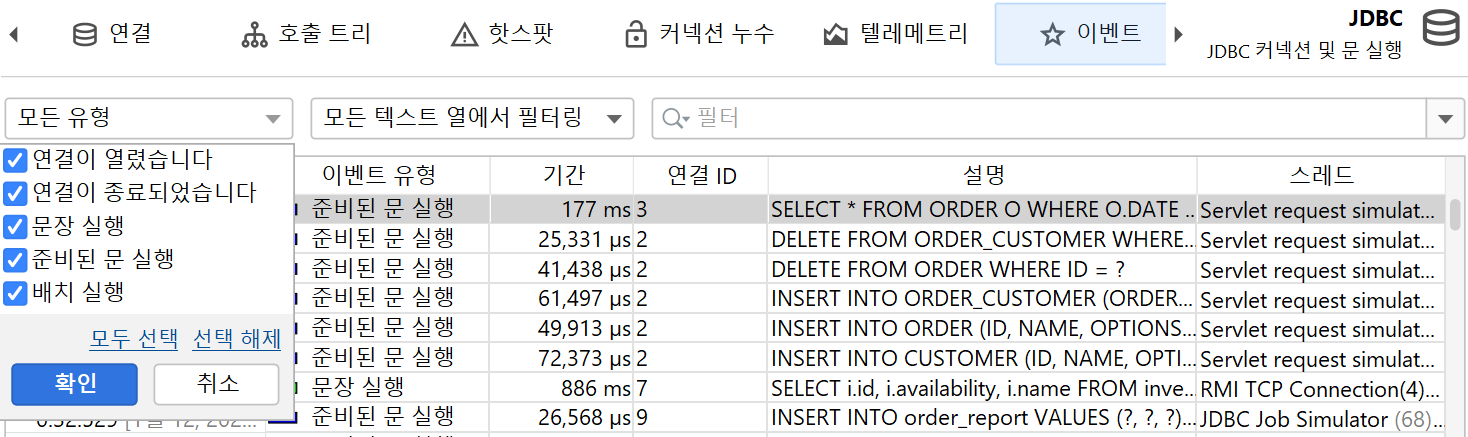
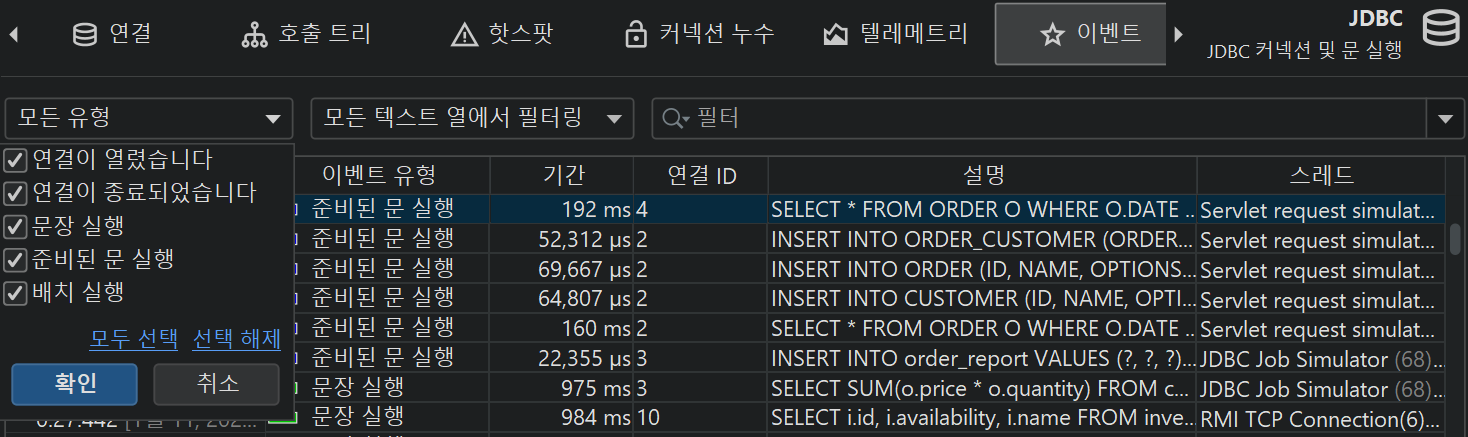
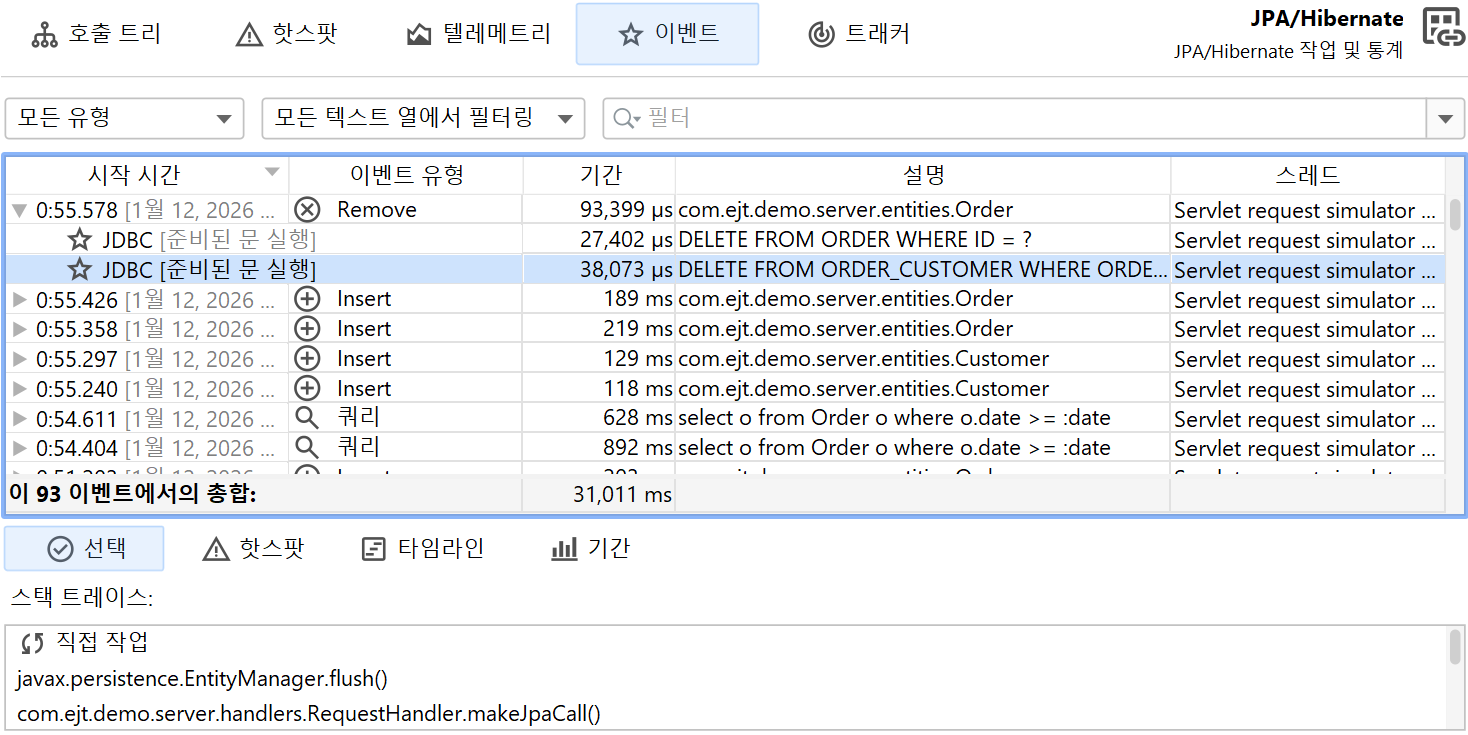
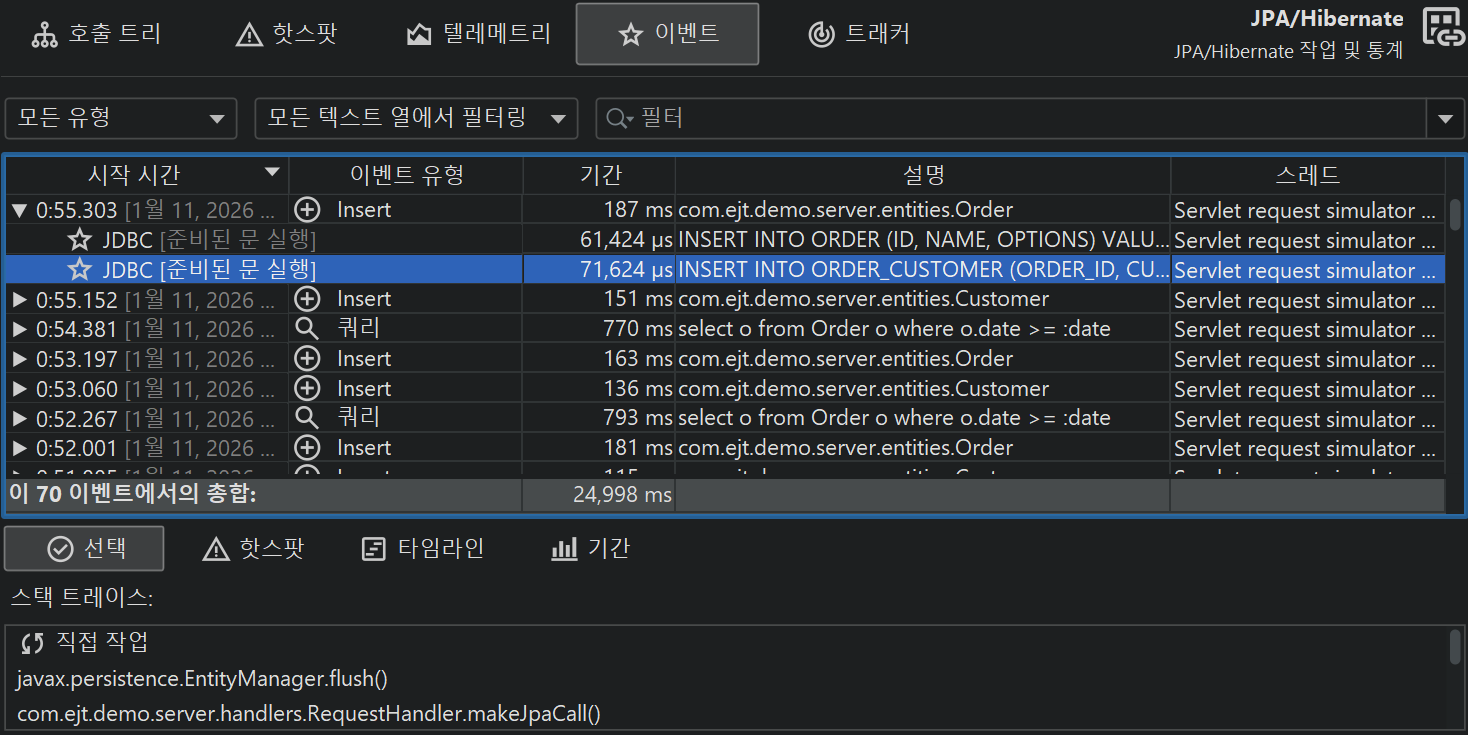
테이블 하단에는 표시된 이벤트의 총 개수와 테이블의 모든 숫자 컬럼의 합계를 보여주는 특별한 행이 있습니다. 기본 컬럼의 경우 Duration 컬럼만 포함됩니다. 테이블 상단의 필터 선택기와 함께, 선택한 이벤트의 부분 집합에 대해 수집된 데이터를 분석할 수 있습니다. 기본적으로 텍스트 필터는 모든 텍스트 필드 컬럼에 적용되지만, 텍스트 필드 앞의 드롭다운에서 특정 필터 컬럼을 선택할 수 있습니다. 필터 옵션은 컨텍스트 메뉴에서도 제공되며, 예를 들어 선택한 이벤트보다 지속 시간이 긴 모든 이벤트를 필터링할 수 있습니다.
다른 프로브 뷰에서도 프로브 이벤트를 필터링하는 옵션을 제공합니다. 프로브 텔레메트리 뷰에서는 시간 범위를 선택할 수 있고, 프로브 호출 트리 뷰에서는 선택한 호출 스택에서 이벤트를 필터링할 수 있습니다. 프로브 핫스팟 뷰에서는 선택한 백트레이스 또는 핫스팟을 기준으로 프로브 이벤트 필터를 제공합니다. 제어 객체 및 타임라인 뷰에서는 선택한 제어 객체에 대한 프로브 이벤트를 필터링하는 동작을 제공합니다.
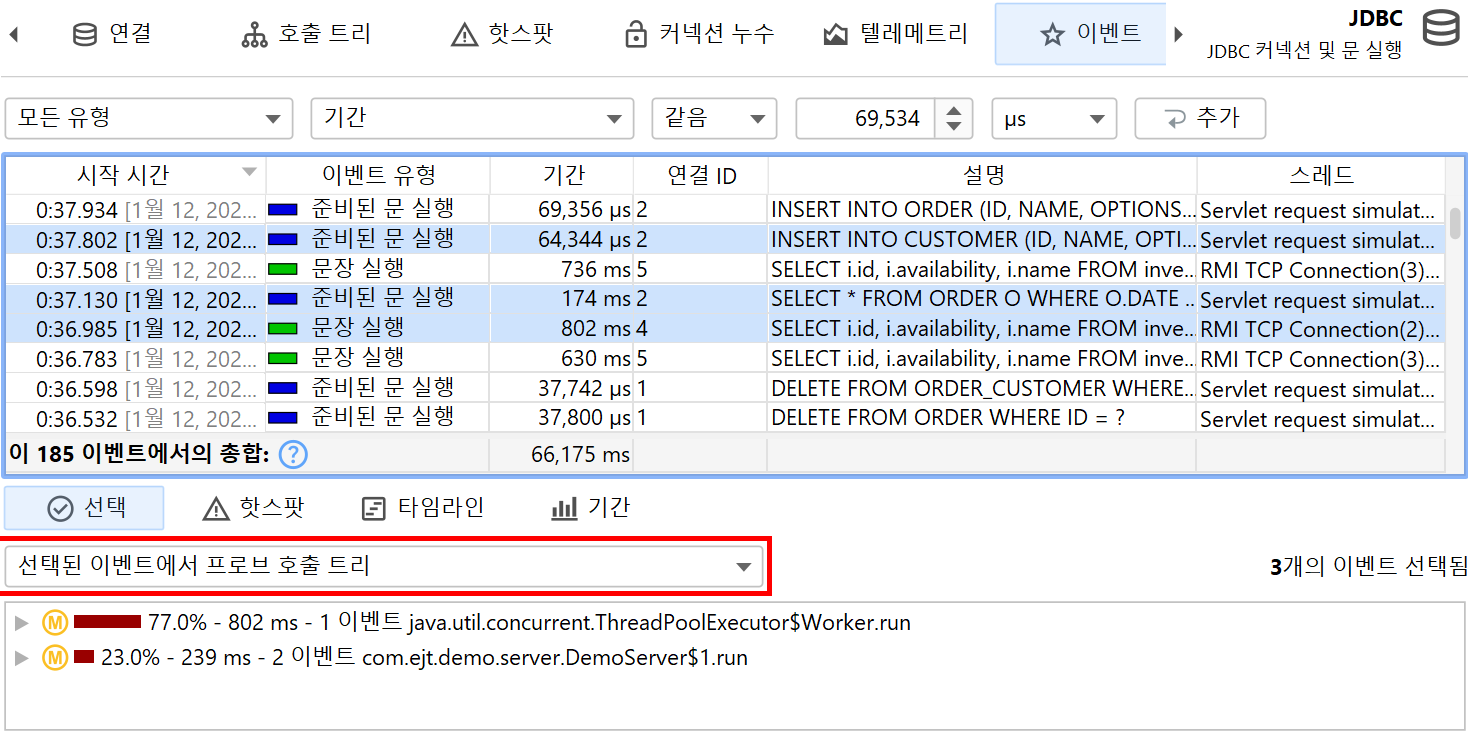
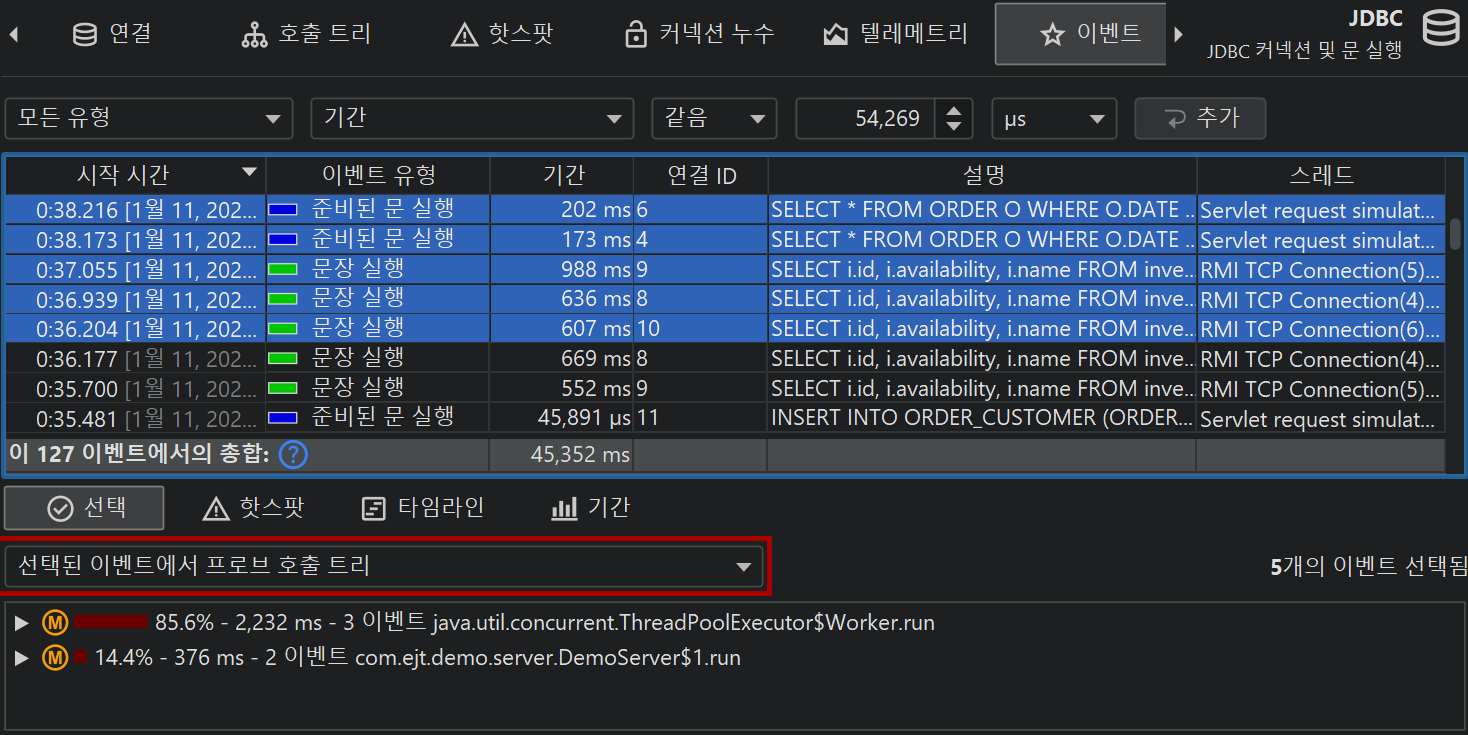
선택한 프로브 이벤트의 스택 트레이스는 하단에 표시됩니다. 여러 프로브 이벤트를 선택하면, 스택 트레이스가 누적되어 호출 트리, 프로브 핫스팟(백트레이스 포함), CPU 핫스팟(백트레이스 포함)으로 표시됩니다.
스택 트레이스 뷰 옆에는 이벤트 지속 시간과 기록된 처리량(옵션)에 대한 히스토그램 뷰가 표시됩니다. 마우스로 히스토그램에서 지속 시간 범위를 선택하여 위의 테이블에서 프로브 이벤트를 필터링할 수 있습니다.
프로브는 다양한 종류의 활동을 기록할 수 있으며, 각 프로브 이벤트에 이벤트 타입을 연결할 수 있습니다. 예를 들어, JDBC 프로브는 statement, prepared statement, batch 실행을 서로 다른 색상의 이벤트 타입으로 표시합니다.
단일 이벤트가 기록될 때 과도한 메모리 사용을 방지하기 위해 JProfiler는 이벤트를 통합합니다. 이벤트 상한은 프로파일링 설정에서 구성되며 모든 프로브에 적용됩니다. 가장 최근의 이벤트만 유지되고, 오래된 이벤트는 폐기됩니다. 이 통합은 상위 수준 뷰에는 영향을 주지 않습니다.
프로브 호출 트리 및 핫스팟
프로브 녹화는 CPU 녹화와 밀접하게 연동됩니다. 프로브 이벤트는 프로브 호출 트리로 집계되며, 프로브 문자열이 리프 노드(페이로드)로 사용됩니다. 프로브 이벤트가 생성된 호출 스택만 해당 트리에 포함됩니다. 메서드 노드의 정보는 기록된 페이로드 이름을 참조합니다. 예를 들어, 특정 호출 스택에서 SQL 문이 42회 실행되고 총 9000ms가 소요되었다면, 해당 호출 트리의 모든 상위 노드에 이벤트 수 42와 시간 9000ms가 누적됩니다. 모든 기록된 페이로드의 누적이 프로브별 시간 소비가 많은 호출 경로를 보여주는 호출 트리를 형성합니다. 프로브 트리의 초점은 페이로드이므로, 뷰 필터는 기본적으로 페이로드를 검색하지만, 컨텍스트 메뉴에서 클래스 필터 모드도 제공합니다.
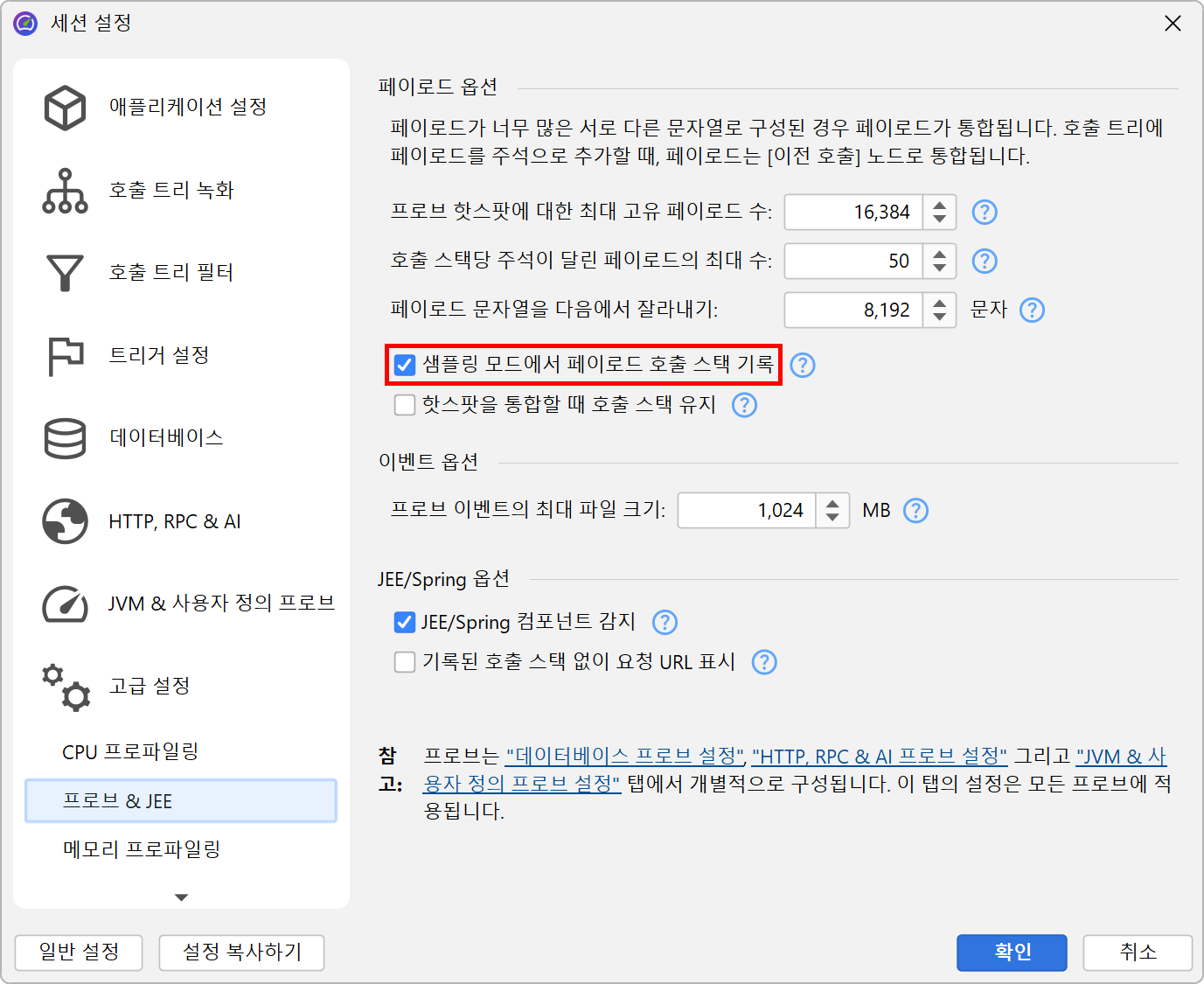
CPU 녹화가 꺼져 있으면, 백트레이스에는 "No CPU data was recorded" 노드만 포함됩니다. CPU 데이터가 일부만 기록된 경우, 실제 백트레이스와 이러한 노드가 혼합되어 나타날 수 있습니다. 샘플링이 활성화되어 있어도, JProfiler는 기본적으로 프로브 페이로드에 대해 정확한 호출 추적을 기록합니다. 이 오버헤드를 피하고 싶다면 프로파일링 설정에서 비활성화할 수 있습니다. 데이터 수집을 늘리거나 오버헤드를 줄이기 위한 여러 프로브 녹화 튜닝 옵션도 제공됩니다.
핫스팟은 프로브 호출 트리에서 계산할 수 있습니다. 핫스팟 노드는 이제 메서드 호출이 아니라 페이로드입니다(CPU 뷰 섹션과 다름). 이는 프로브에서 가장 즉각적으로 유용한 뷰입니다. CPU 녹화가 활성화되어 있으면, 최상위 핫스팟을 열어 메서드 백트레이스를 분석할 수 있으며, 일반 CPU 핫스팟 뷰와 동일하게 동작합니다. 백트레이스 노드의 숫자는 해당 호출 스택을 따라 측정된 프로브 이벤트 수와 총 지속 시간을 나타냅니다.
프로브 호출 트리와 프로브 핫스팟 뷰 모두에서 스레드 또는 스레드 그룹, 스레드 상태, 메서드 노드의 집계 수준을 선택할 수 있습니다. 이는 CPU 뷰와 동일합니다. CPU 뷰에서 데이터를 비교할 때, 프로브 뷰의 기본 스레드 상태가 "All states"이고 CPU 뷰는 "Runnable"임을 유념해야 합니다. 이는 프로브 이벤트가 데이터베이스 호출, socket 작업, 프로세스 실행 등 외부 시스템과 관련된 경우가 많아, JVM이 실제로 작업한 시간뿐만 아니라 전체 시간을 보는 것이 중요하기 때문입니다.
제어 객체
외부 리소스에 접근할 수 있도록 해주는 많은 라이브러리는 리소스와 상호작용할 수 있는 커넥션 객체를 제공합니다. 예를 들어, 프로세스를 시작할 때
java.lang.Process 객체를 통해 출력 스트림에서 읽고 입력 스트림에 쓸 수 있습니다. JDBC를 사용할 때는 SQL 쿼리를 수행하기 위해
java.sql.Connection 객체가 필요합니다. JProfiler에서는 이러한 객체를 "제어 객체"라고 부릅니다.
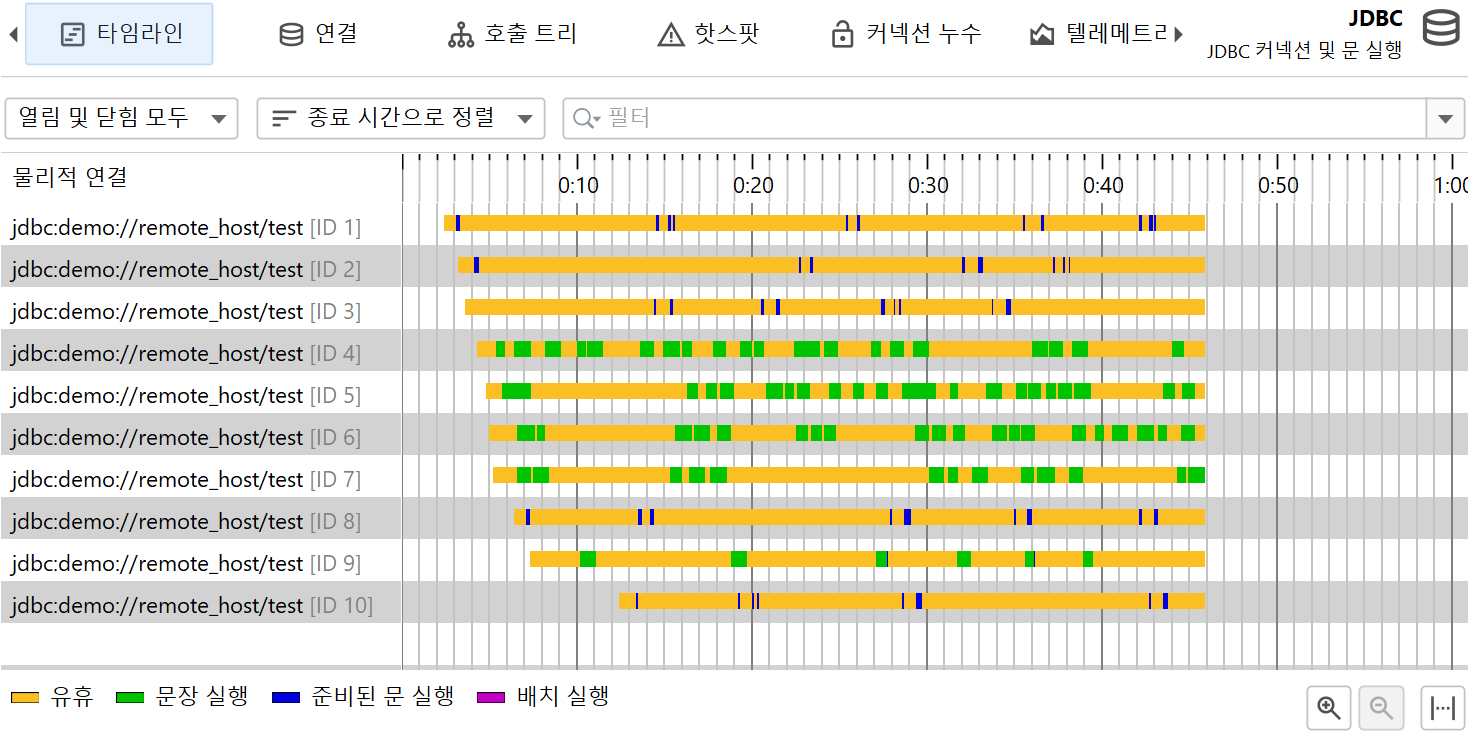
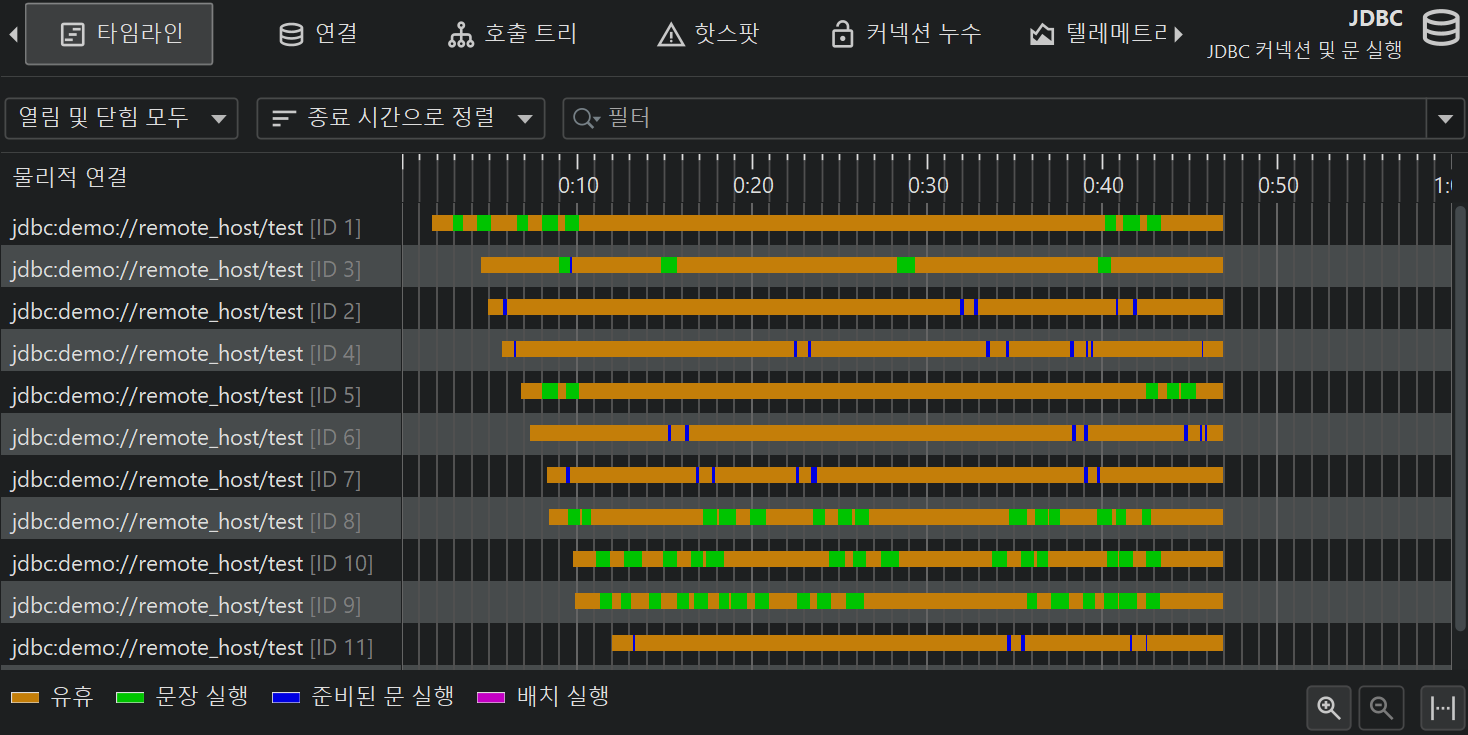
프로브 이벤트를 제어 객체와 함께 그룹화하고, 그 생명주기를 표시하면 문제의 원인을 더 잘 이해할 수 있습니다. 또한 제어 객체 생성은 비용이 크기 때문에, 애플리케이션이 너무 많이 생성하거나 제대로 닫지 않는지 확인하는 것이 중요합니다. 이를 위해 제어 객체를 지원하는 프로브는 "Timeline"과 "Control objects" 뷰를 제공합니다. 후자는 예를 들어 JDBC 프로브의 경우 "Connections"와 같이 더 구체적으로 명명될 수 있습니다. 제어 객체가 열리거나 닫힐 때, 프로브는 특별한 프로브 이벤트를 생성하여 이벤트 뷰에 표시하므로, 관련된 스택 트레이스를 확인할 수 있습니다.
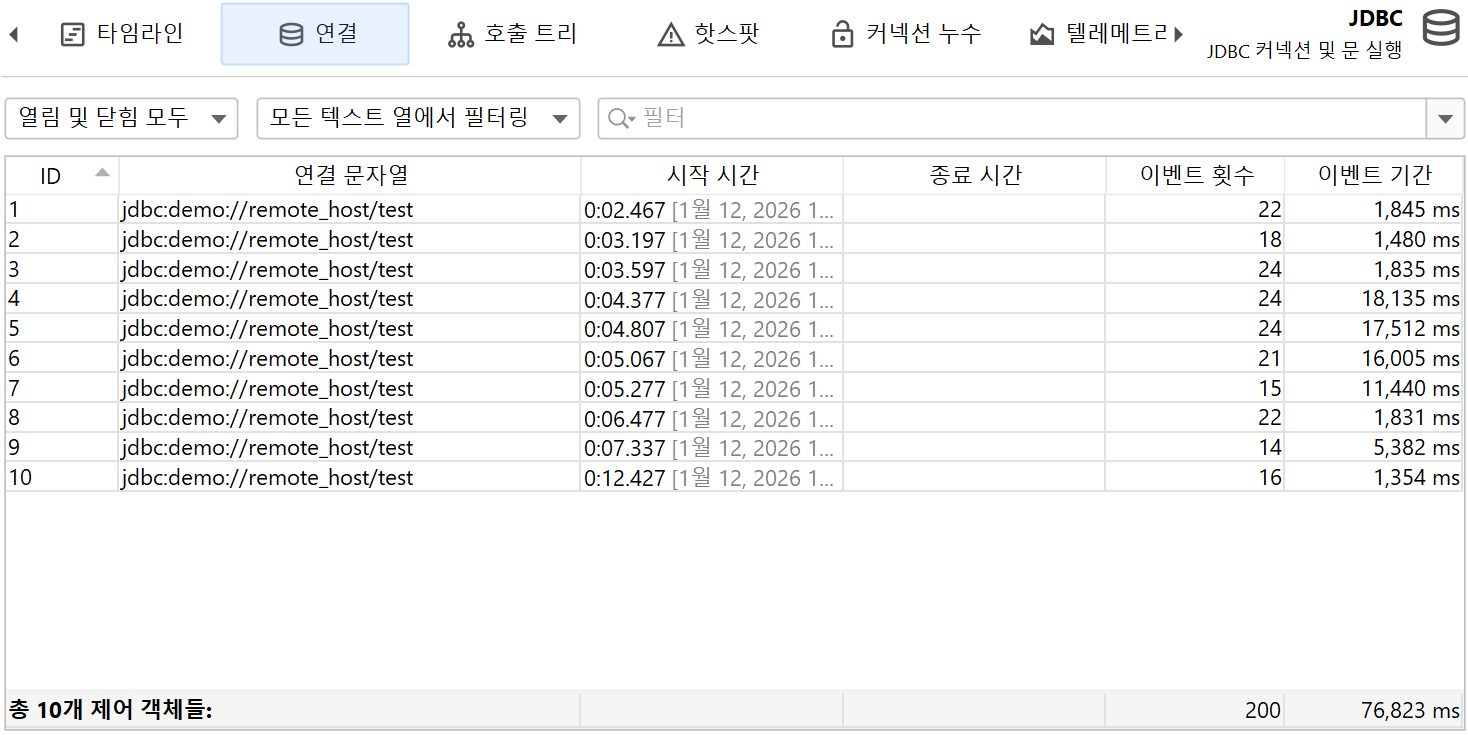
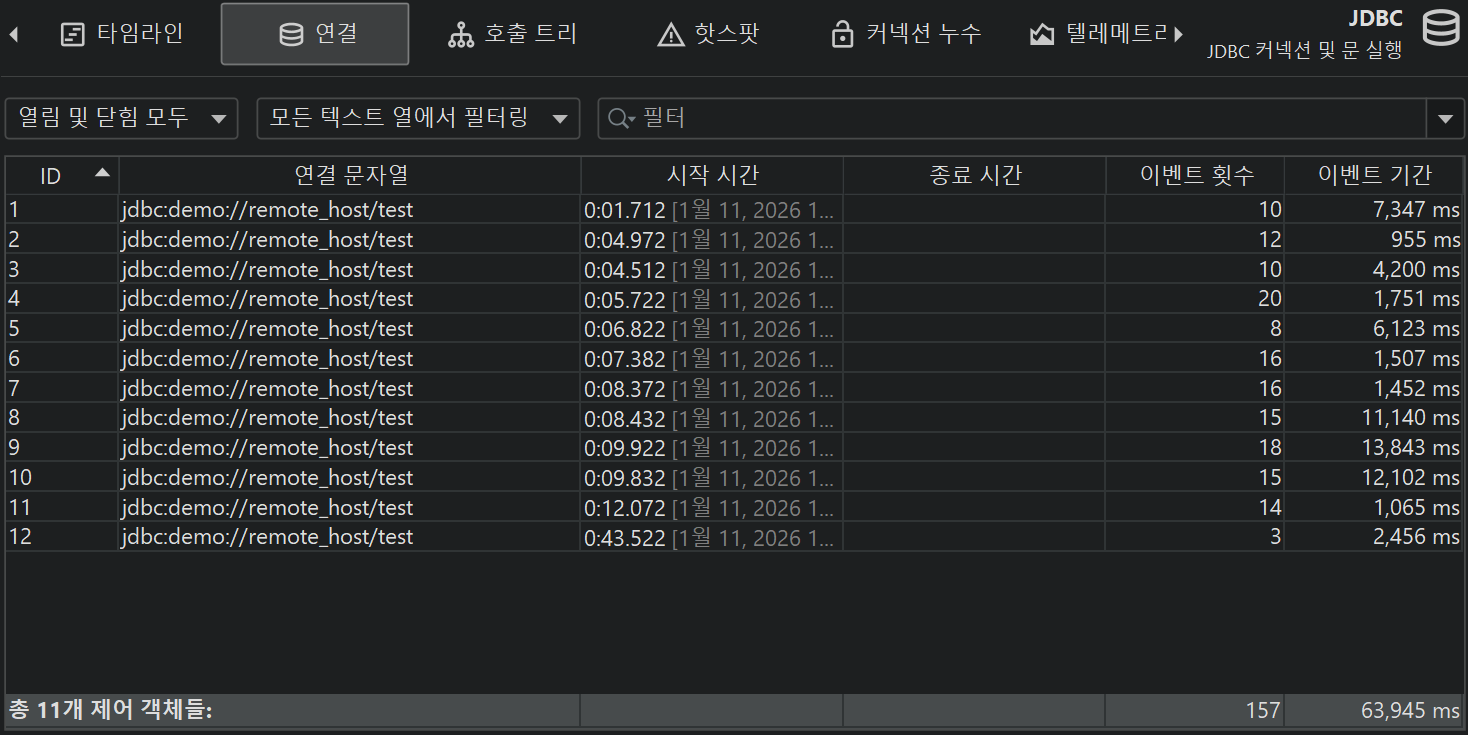
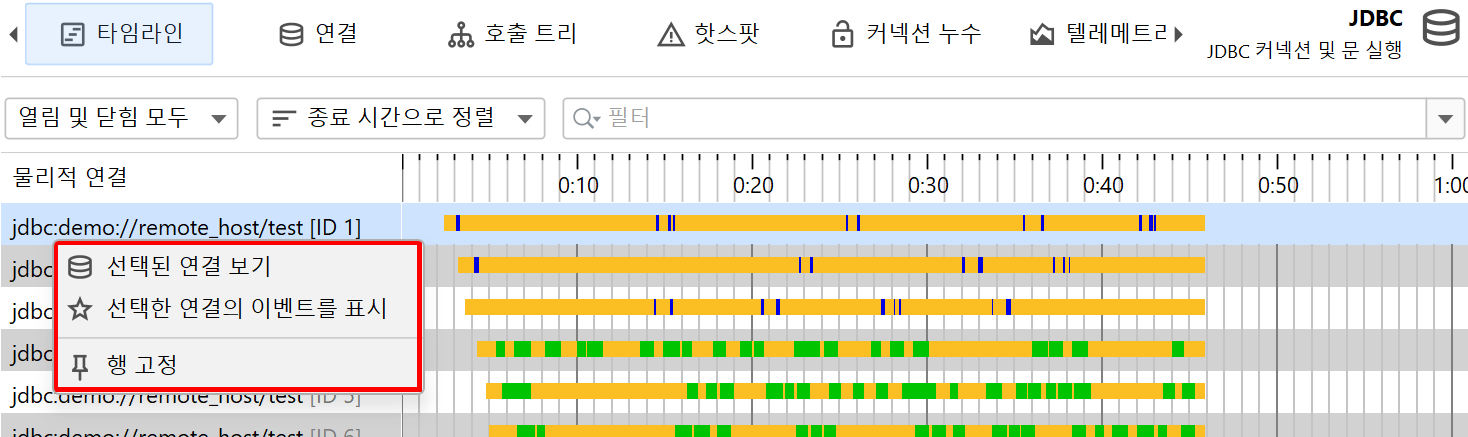
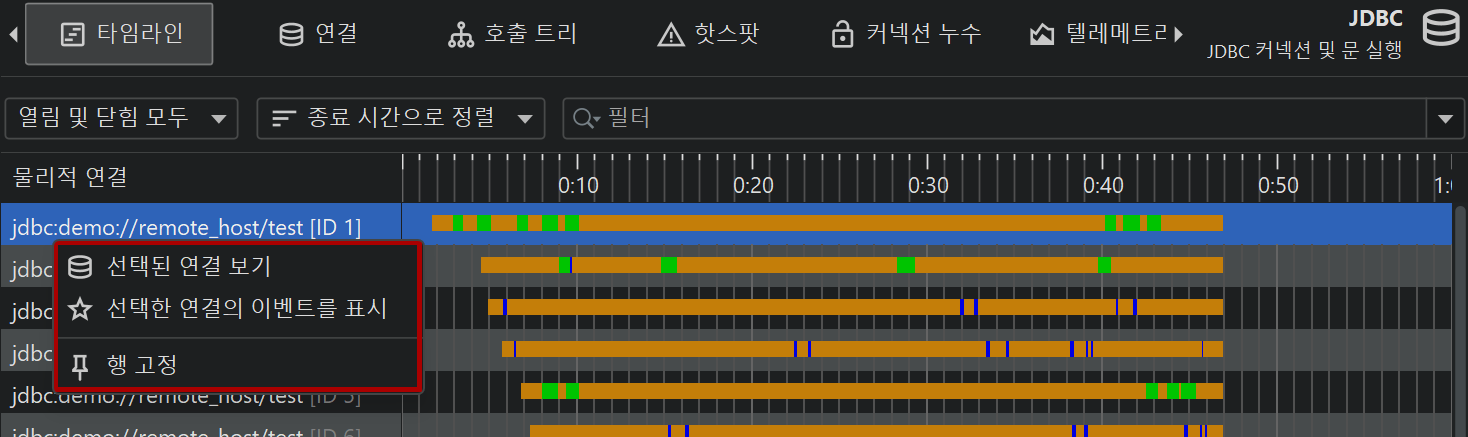
타임라인 뷰에서는 각 제어 객체가 바 형태로 표시되며, 색상으로 제어 객체가 활성화된 시점을 보여줍니다. 프로브는 다양한 이벤트 타입을 기록할 수 있으며, 타임라인은 이에 따라 색상이 지정됩니다. 이 상태 정보는 이벤트 목록에서 가져오는 것이 아니라, 마지막 상태를 기준으로 100ms마다 샘플링됩니다. 제어 객체에는 식별할 수 있는 이름이 있습니다. 예를 들어, 파일 프로브는 파일명을 이름으로 사용하고, JDBC 프로브는 커넥션 문자열을 제어 객체의 이름으로 표시합니다.
제어 객체 뷰는 모든 제어 객체를 표 형태로 보여줍니다. 기본적으로 열려 있는 객체와 닫힌 객체 모두 표시됩니다. 상단의 컨트롤을 사용하여 열려 있거나 닫힌 제어 객체만 표시하거나, 특정 컬럼의 내용을 필터링할 수 있습니다. 제어 객체의 기본 생명주기 데이터 외에도, 테이블에는 각 제어 객체의 누적 활동 데이터(예: 이벤트 수, 평균 이벤트 지속 시간)가 표시됩니다.
프로브마다 표시되는 컬럼이 다르며, 예를 들어 프로세스 프로브는 읽기 및 쓰기 이벤트에 대해 별도의 컬럼 집합을 보여줍니다. 단일 이벤트 기록이 비활성화되어 있어도 이 정보는 제공됩니다. 이벤트 뷰와 마찬가지로, 하단의 합계 행을 필터링과 함께 사용하여 제어 객체의 부분 집합에 대한 누적 데이터를 얻을 수 있습니다.
프로브는 중첩 테이블에서 특정 속성을 표시할 수 있습니다. 이는 메인 테이블의 정보 과부하를 줄이고 컬럼 공간을 더 확보하기 위함입니다. 파일 및 프로세스 프로브와 같이 중첩 테이블이 있는 경우, 각 행의 왼쪽에 확장 핸들이 있어 속성-값 테이블을 펼칠 수 있습니다.
타임라인, 제어 객체 뷰, 이벤트 뷰는 탐색 동작으로 연결되어 있습니다. 예를 들어, 타임라인 뷰에서 행을 우클릭하면 다른 뷰로 이동하여 선택한 제어 객체의 데이터만 표시할 수 있습니다. 이는 제어 객체 ID를 선택한 값으로 필터링하여 이루어집니다.
텔레메트리 및 트래커
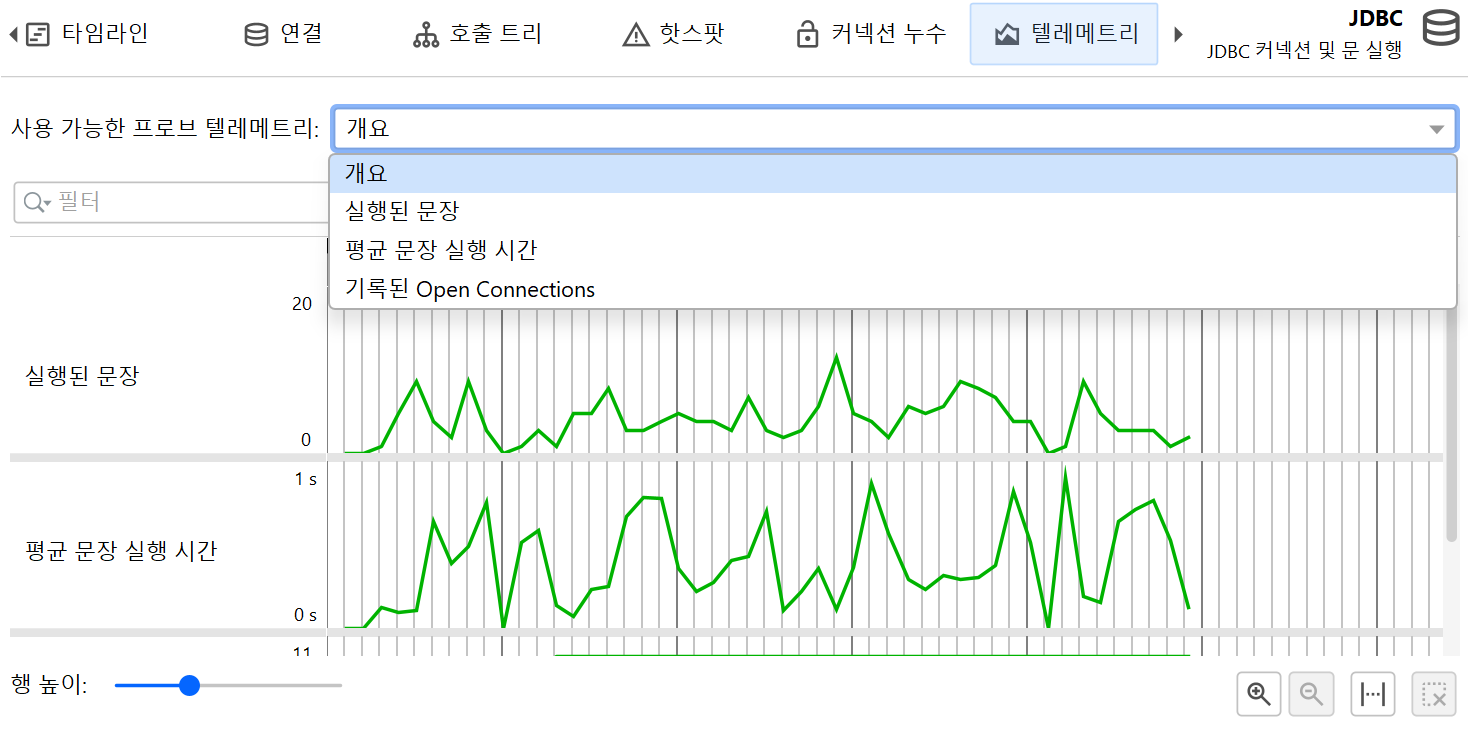
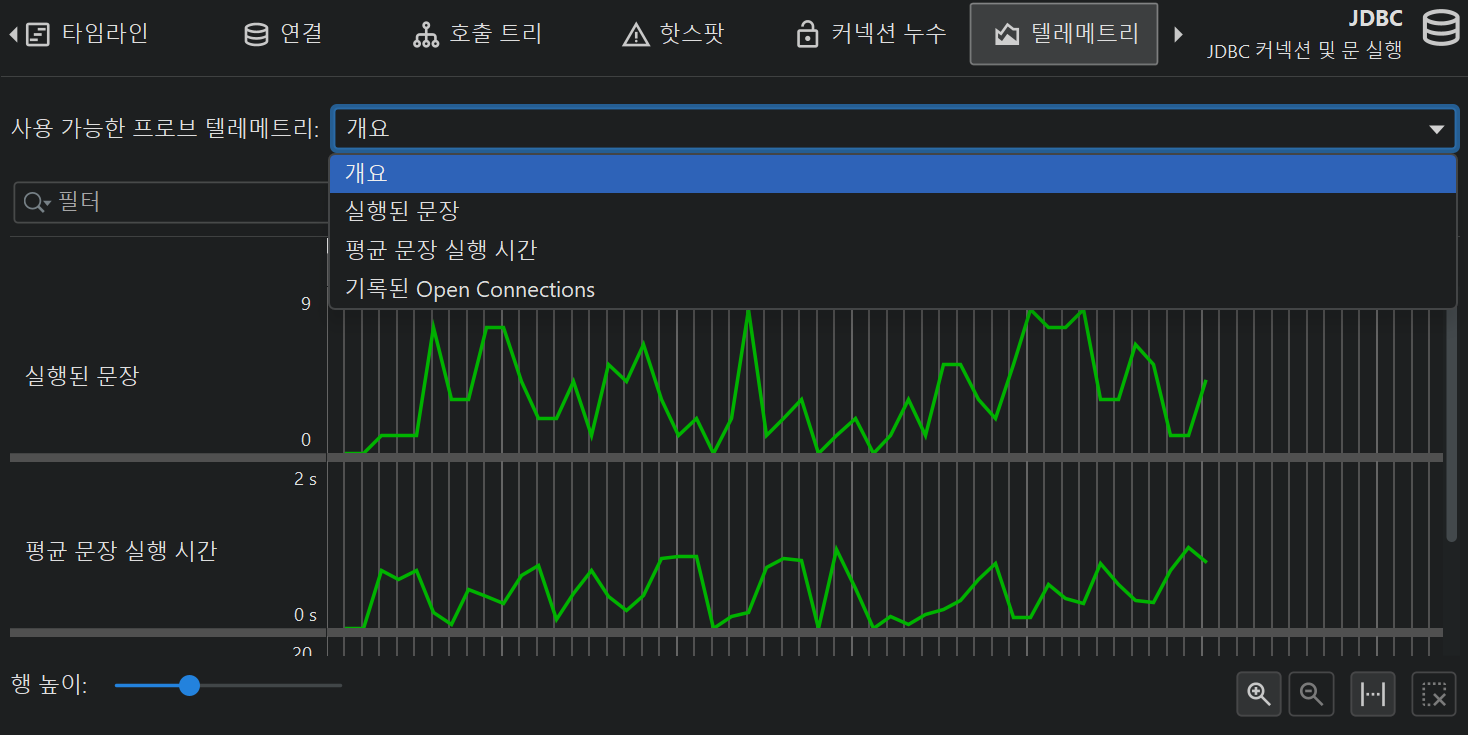
프로브가 수집한 누적 데이터로부터 여러 텔레메트리가 기록됩니다. 모든 프로브에 대해 초당 프로브 이벤트 수, 평균 이벤트 지속 시간 또는 I/O 작업의 처리량과 같은 평균 측정값이 제공됩니다. 제어 객체가 있는 프로브의 경우, 열린 제어 객체 수 또한 표준 텔레메트리입니다. 각 프로브는 추가 텔레메트리를 더할 수 있습니다. 예를 들어, JPA 프로브는 쿼리 수와 엔티티 작업 수에 대한 별도의 텔레메트리를 제공합니다.
핫스팟 뷰와 제어 객체 뷰는 시간이 지남에 따라 추적할 만한 누적 데이터를 보여줍니다. 이러한 특별한 텔레메트리는 프로브 트래커로 기록됩니다. 추적을 설정하는 가장 쉬운 방법은 핫스팟 또는 제어 객체 뷰에서 선택 항목을 트래커에 추가 동작으로 새 텔레메트리를 추가하는 것입니다. 두 경우 모두 시간 또는 카운트 중 어떤 것을 추적할지 선택해야 합니다. 제어 객체를 추적할 때 텔레메트리는 서로 다른 프로브 이벤트 타입에 대한 누적 영역 그래프입니다. 추적된 핫스팟의 경우, 추적된 시간은 서로 다른 스레드 상태로 분할됩니다.
프로브 텔레메트리는 "텔레메트리" 섹션에 추가하여 시스템 텔레메트리나 사용자 정의 텔레메트리와 비교할 수 있습니다. 이때 텔레메트리 개요의 컨텍스트 메뉴 동작을 통해 프로브 녹화도 제어할 수 있습니다.
JDBC 및 JPA
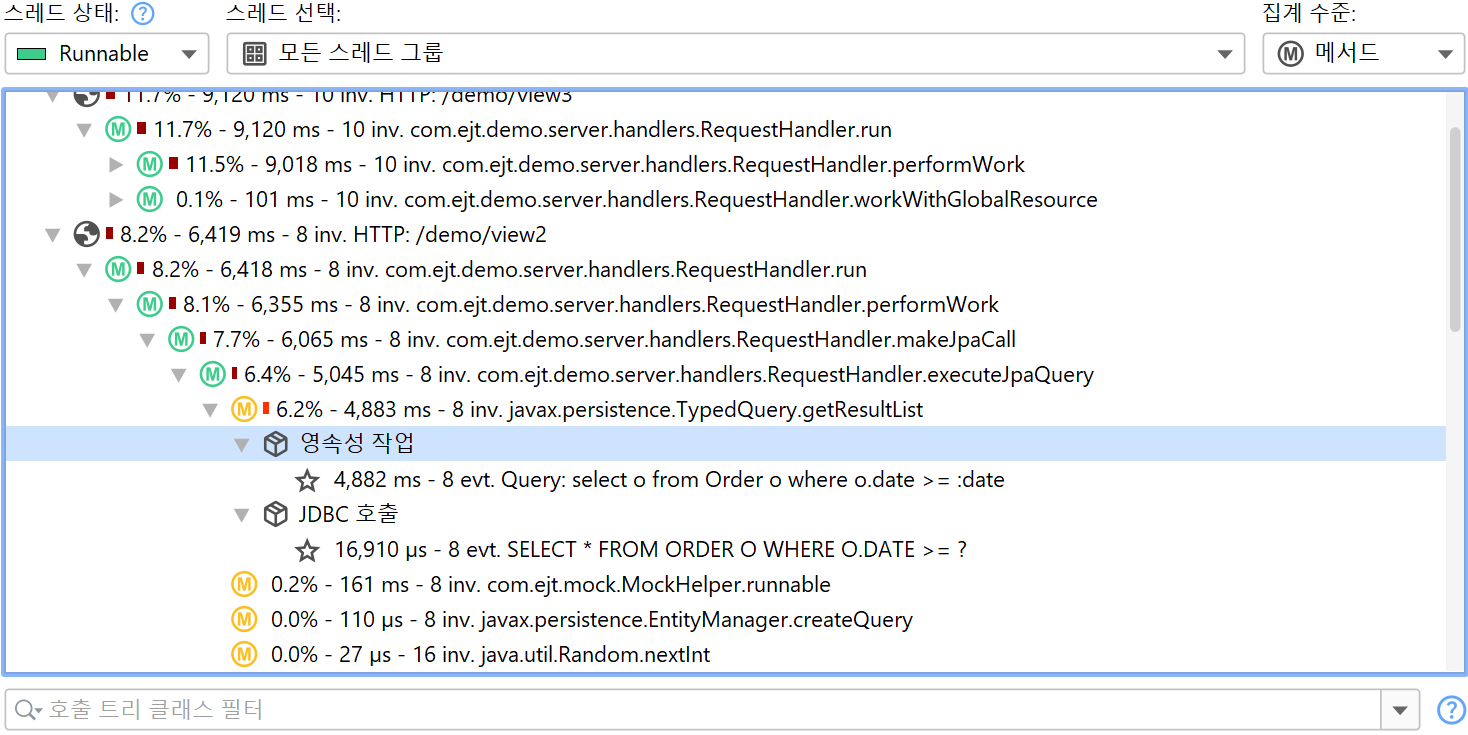
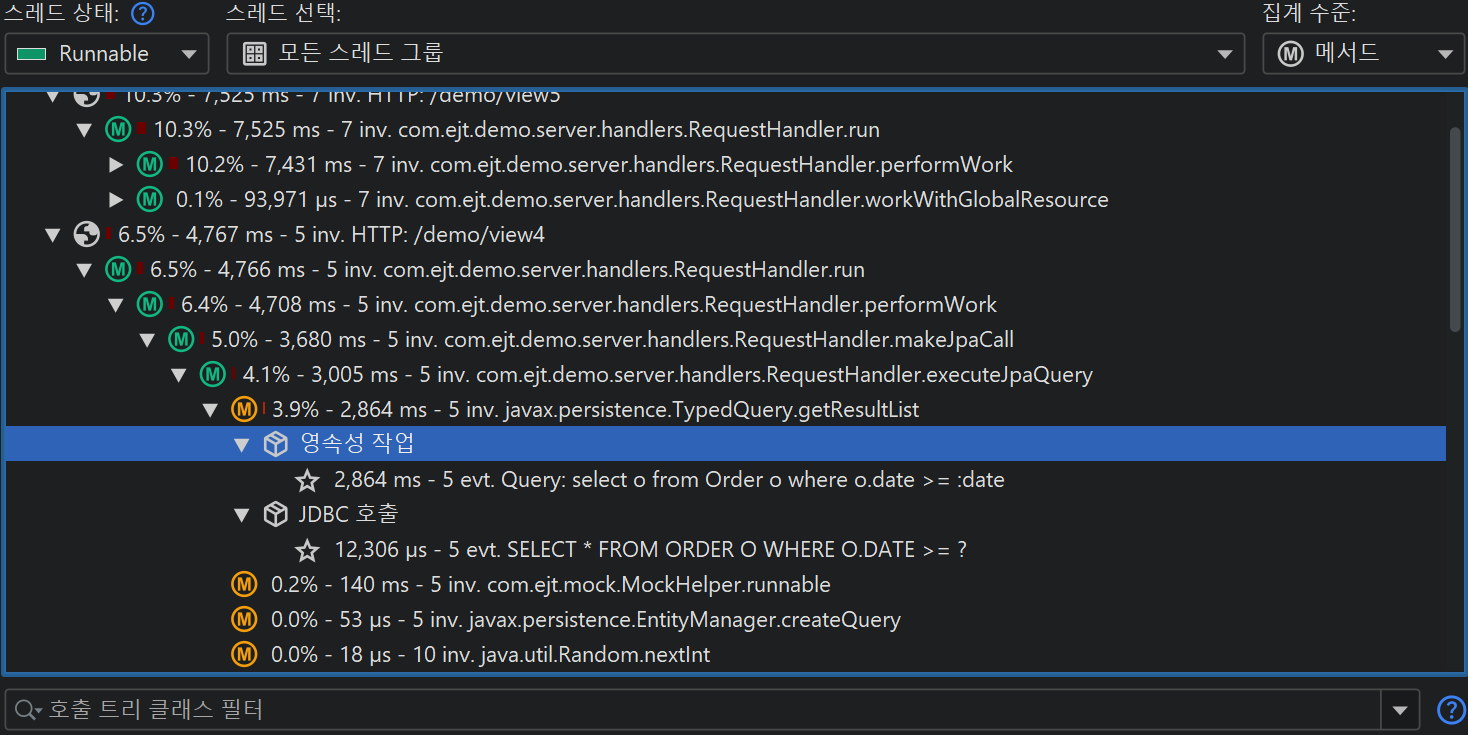
JDBC와 JPA 프로브는 서로 연동하여 동작합니다. JPA 프로브의 이벤트 뷰에서 단일 이벤트를 확장하면, JDBC 프로브가 함께 기록된 경우 관련된 JDBC 이벤트를 볼 수 있습니다.
마찬가지로, 핫스팟 뷰는 모든 핫스팟에 "JDBC calls" 노드를 추가하여 JPA 작업에 의해 트리거된 JDBC 호출을 포함합니다. 일부 JPA 작업은 비동기적으로 실행되어 즉시 처리되지 않고, 세션이 flush될 때 임의의 시점에 실행됩니다. 성능 문제를 찾을 때, 해당 flush의 스택 트레이스는 도움이 되지 않으므로, JProfiler는 기존 엔티티가 획득되거나 새 엔티티가 영속화된 위치의 스택 트레이스를 기억하여 프로브 이벤트에 연결합니다. 이 경우, 핫스팟의 백트레이스는 "Deferred operations" 노드에 포함되며, 그렇지 않으면 "Direct operations" 노드가 삽입됩니다.
MongoDB 프로브와 같은 다른 프로브도 직접 및 비동기 작업을 모두 지원합니다. 비동기 작업은 현재 스레드가 아닌 다른 스레드(동일 JVM 또는 다른 프로세스)에서 실행됩니다. 이러한 프로브의 경우, 핫스팟의 백트레이스는 "Direct operations"와 "Async operation" 컨테이너 노드로 분류됩니다.
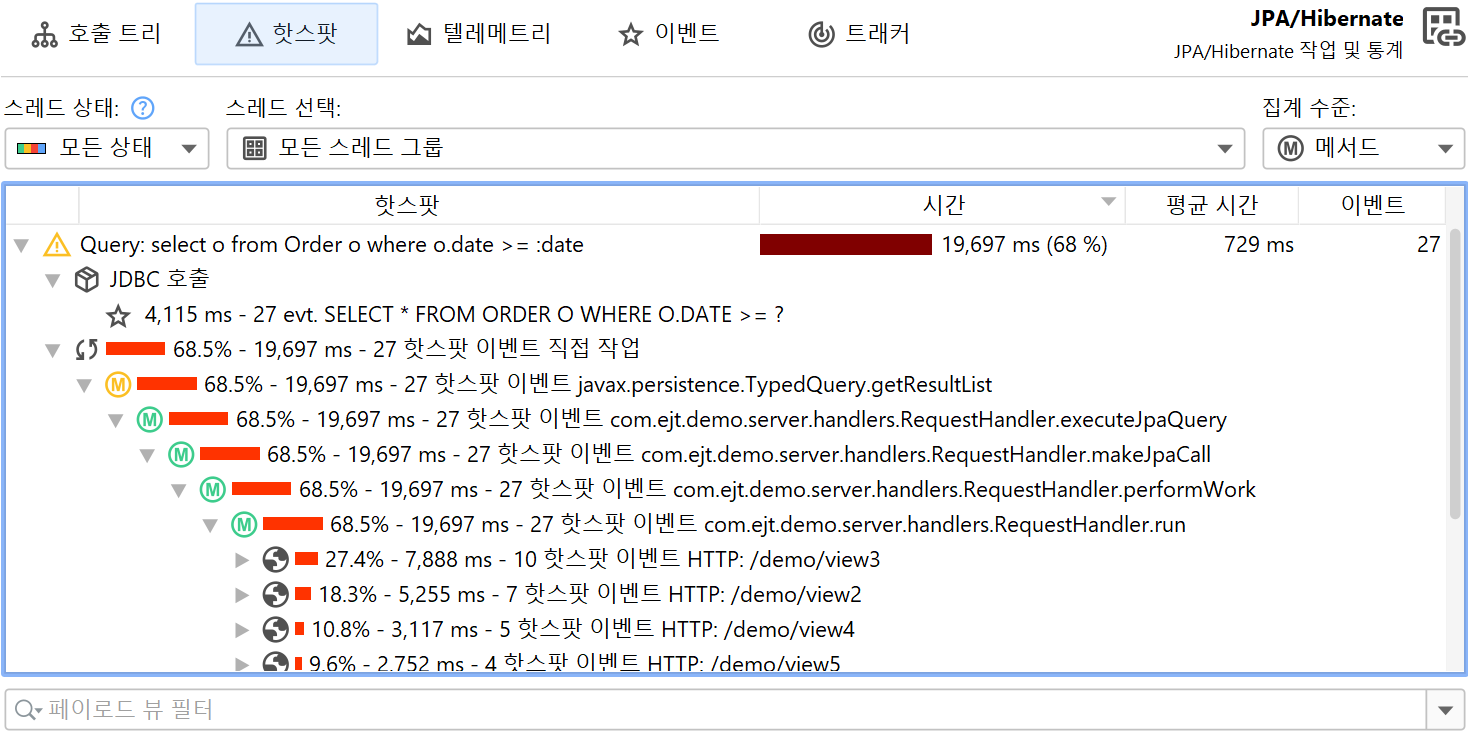
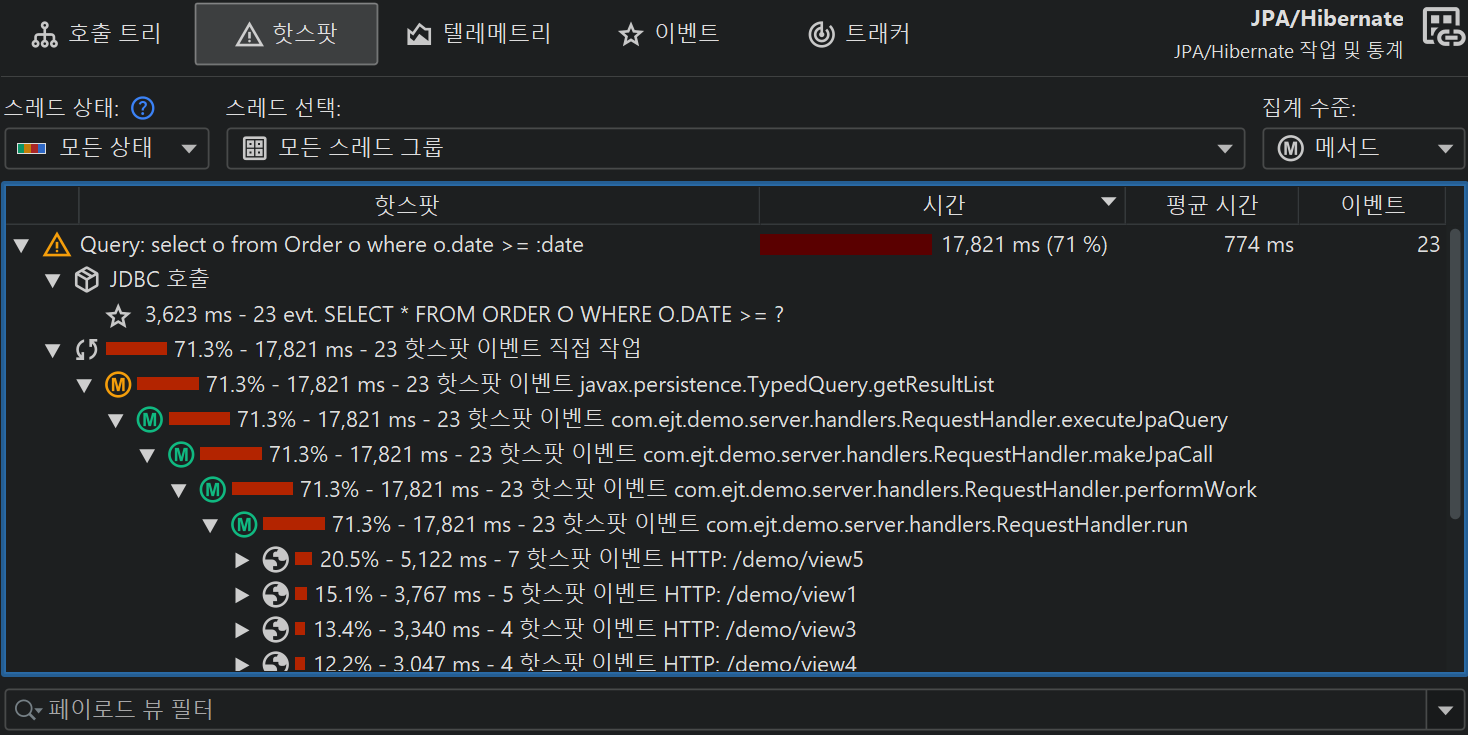
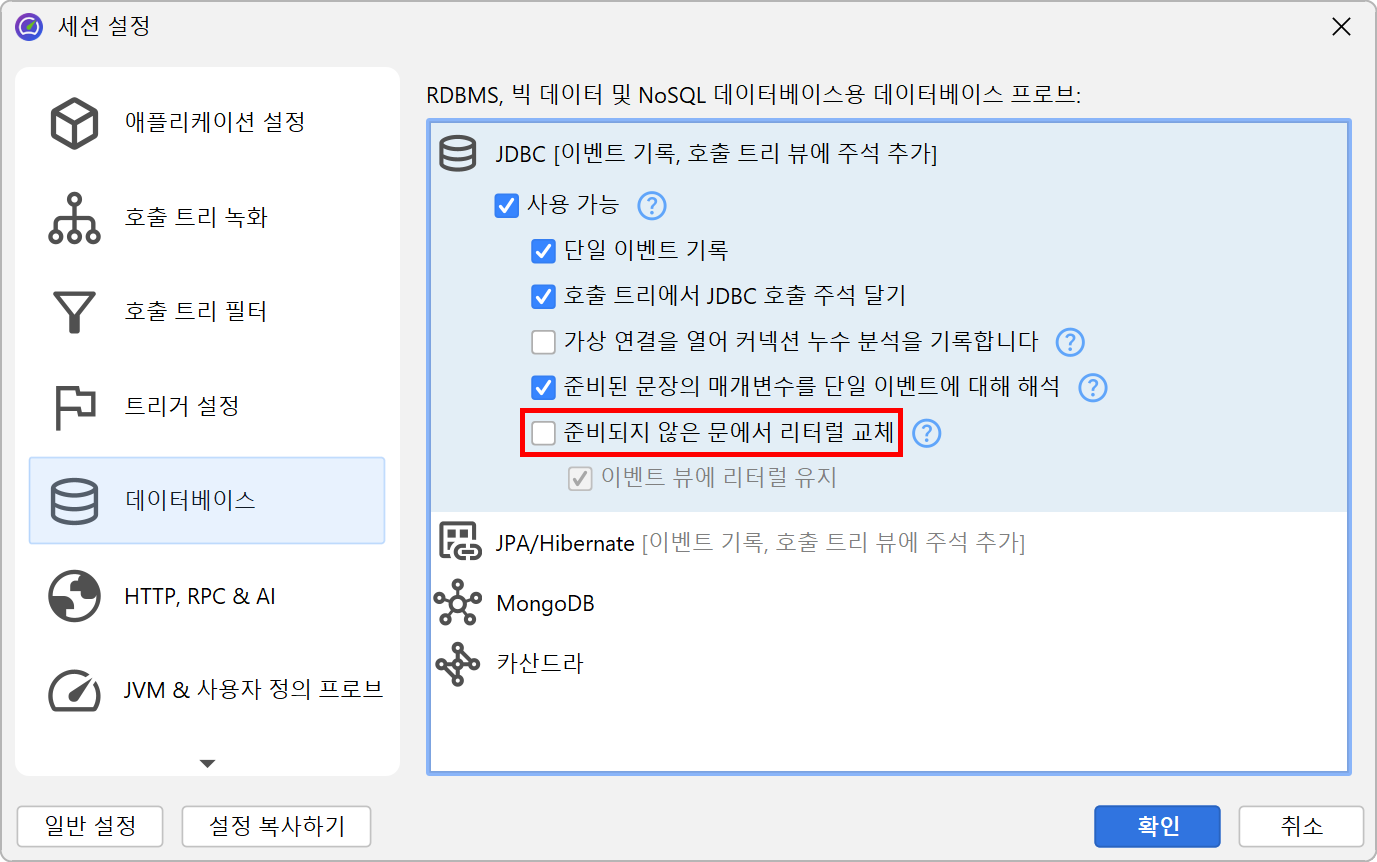
JDBC 프로브의 특별한 문제는, SQL 문자열에 리터럴 데이터(예: ID)가 포함되지 않을 때만 좋은 핫스팟을 얻을 수 있다는 점입니다. prepared statement를 사용하면 자동으로 해당 조건이 충족되지만, 일반 statement를 실행할 경우에는 그렇지 않습니다. 이 경우 대부분의 쿼리가 한 번만 실행되어 핫스팟 목록이 길어질 수 있습니다. 이를 해결하기 위해, JProfiler는 JDBC 프로브 설정에서 unprepared statement의 리터럴을 대체하는 비기본 옵션을 제공합니다. 디버깅 목적으로 이벤트 뷰에서 리터럴을 보고 싶을 수도 있습니다. 해당 옵션을 비활성화하면 JProfiler가 다양한 문자열을 캐시할 필요가 없어 메모리 오버헤드가 줄어듭니다.
반면, JProfiler는 prepared statement의 파라미터를 수집하여 이벤트 뷰에 플레이스홀더 없는 완전한 SQL 문자열을 표시합니다. 이 역시 디버깅에 유용하지만, 필요하지 않다면 프로브 설정에서 비활성화하여 메모리를 절약할 수 있습니다.
JDBC 커넥션 누수
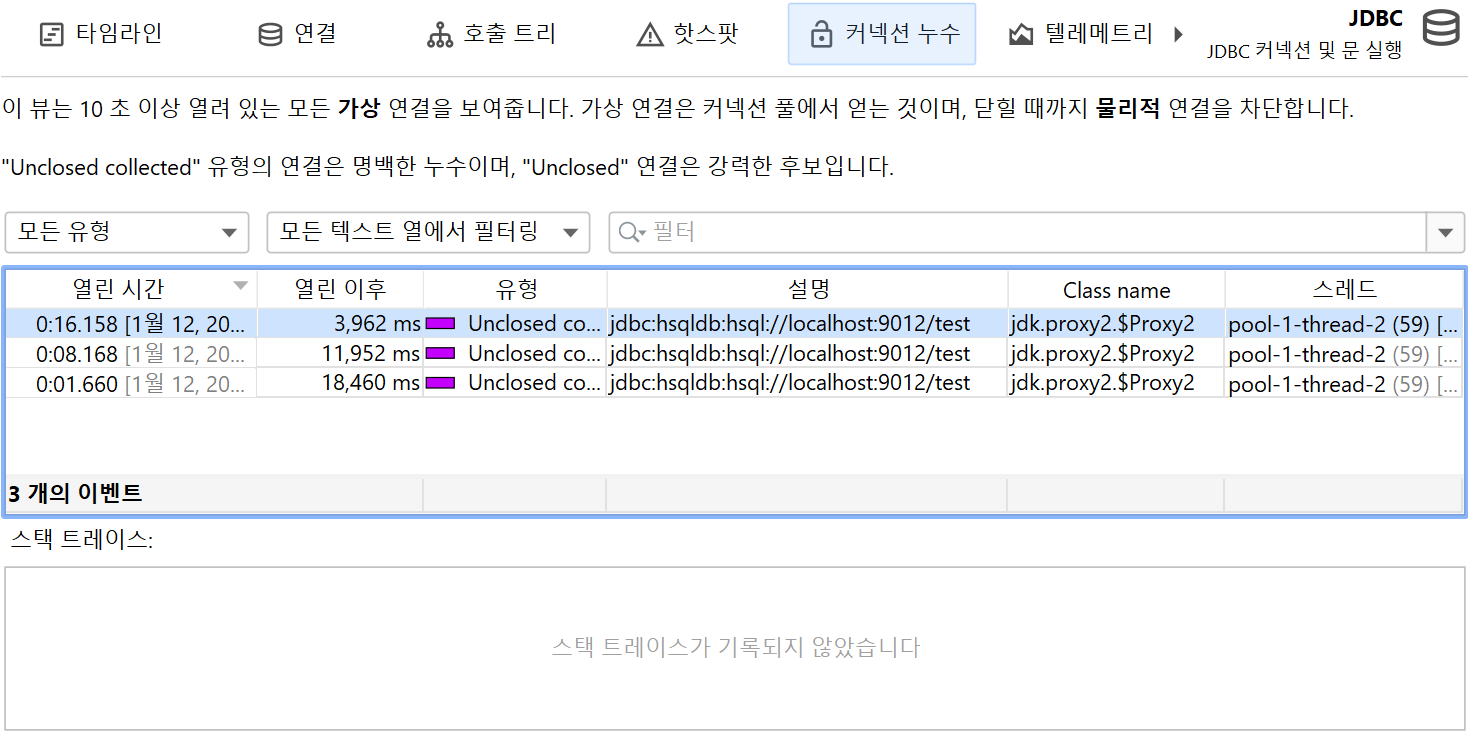
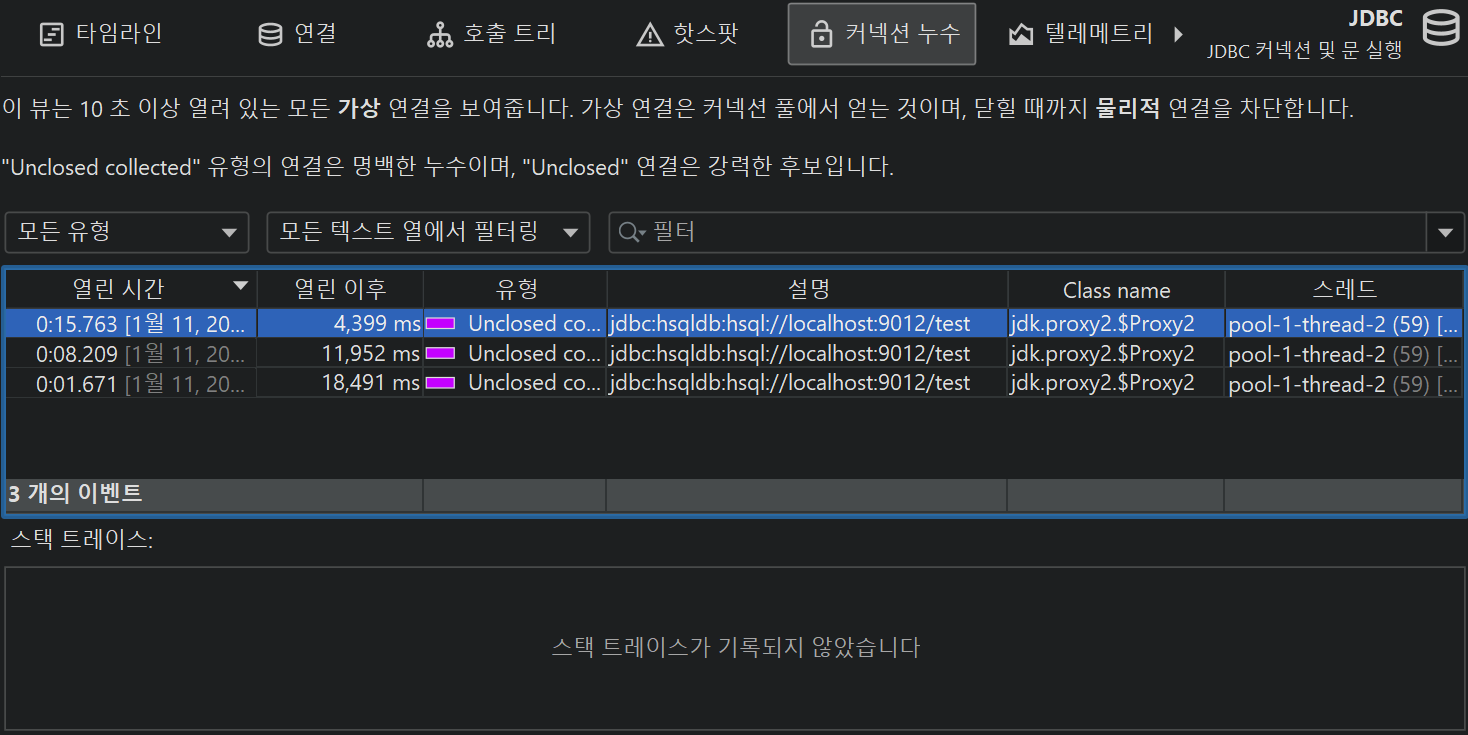
JDBC 프로브에는 "커넥션 누수" 뷰가 있어, 데이터베이스 풀에 반환되지 않은 열린 가상 데이터베이스 커넥션을 보여줍니다. 이는 풀링된 데이터베이스 소스에서 생성된 가상 커넥션에만 해당됩니다. 가상 커넥션은 닫힐 때까지 실제 커넥션을 점유합니다.
누수 후보에는 "unclosed" 커넥션과 "unclosed collected" 커넥션의 두 가지 유형이 있습니다. 두 유형 모두 데이터베이스 풀에서 반환된 커넥션 객체가 여전히 힙에 있지만,
close()가 호출되지 않은 가상 커넥션입니다. "Unclosed collected" 커넥션은 가비지 컬렉션이 완료된 확실한 커넥션 누수입니다.
"Unclosed" 커넥션 객체는 여전히 힙에 남아 있습니다. Open Since 지속 시간이 길수록 해당 가상 커넥션이 누수 후보일 가능성이 높습니다. 가상 커넥션이 10초 이상 열려
있으면 잠재적 누수로 간주됩니다. 그러나 close()가 호출되면 "커넥션 누수" 뷰에서 해당 항목이 제거됩니다.
커넥션 누수 테이블에는 커넥션 클래스 이름을 보여주는 Class Name 컬럼이 있습니다. 이를 통해 어떤 풀에서 커넥션이 생성되었는지 알 수 있습니다. JProfiler는 많은 데이터베이스 드라이버와 커넥션 풀을 명시적으로 지원하며, 어떤 클래스가 가상/실제 커넥션인지 알고 있습니다. 알 수 없는 풀이나 드라이버의 경우, JProfiler가 실제 커넥션을 가상 커넥션으로 오인할 수 있습니다. 실제 커넥션은 보통 장시간 유지되므로, 이 경우 "커넥션 누수" 뷰에 표시될 수 있습니다. 이때 커넥션 객체의 클래스 이름을 통해 오탐 여부를 확인할 수 있습니다.
기본적으로 프로브 녹화를 시작할 때 커넥션 누수 분석은 활성화되어 있지 않습니다. 커넥션 누수 뷰에는 별도의 녹화 버튼이 있으며, 이는 JDBC 프로브 설정의 커넥션 누수 분석을 위한 열린 가상 커넥션 기록 체크박스와 상태가 연동됩니다. 이벤트 녹화와 마찬가지로 버튼의 상태는 지속되므로, 한 번 분석을 시작하면 다음 프로브 녹화 세션에서도 자동으로 시작됩니다.
호출 트리의 페이로드 데이터
CPU 호출 트리를 볼 때, 프로브가 페이로드 데이터를 기록한 위치를 확인하는 것은 매우 유용합니다. 해당 데이터는 측정된 CPU 시간을 해석하는 데 도움이 됩니다. 그래서 많은 프로브가 CPU 호출 트리에 크로스 링크를 추가합니다. 예를 들어, 클래스 로더 프로브는 클래스 로딩이 트리거된 위치를 보여줄 수 있습니다. 이는 호출 트리에서 기본적으로 보이지 않으며, 예기치 않은 오버헤드를 유발할 수 있습니다. 호출 트리 뷰에서 불투명한 데이터베이스 호출도, 해당 프로브에서 한 번의 클릭으로 추가 분석이 가능합니다. 이 기능은 호출 트리 분석에서 프로브 호출 트리 뷰로 자동 전환되어, 프로브 링크를 클릭하면 즉시 분석이 반복됩니다.
또 다른 방법은 페이로드 정보를 CPU 호출 트리에 직접 인라인으로 표시하는 것입니다. 관련 프로브에는 해당 목적을 위한 호출 트리에 주석 달기 옵션이 설정에 있습니다. 이 경우에는 프로브 호출 트리로의 링크가 제공되지 않습니다. 각 프로브는 자체 페이로드 컨테이너 노드를 가집니다. 동일한 페이로드 이름의 이벤트는 집계되며, 호출 횟수와 총 시간이 표시됩니다. 페이로드 이름은 호출 스택별로 통합되며, 오래된 항목은 "[earlier calls]" 노드로 집계됩니다. 호출 스택별로 기록되는 페이로드 이름의 최대 개수는 프로파일링 설정에서 구성할 수 있습니다.
호출 트리 분할
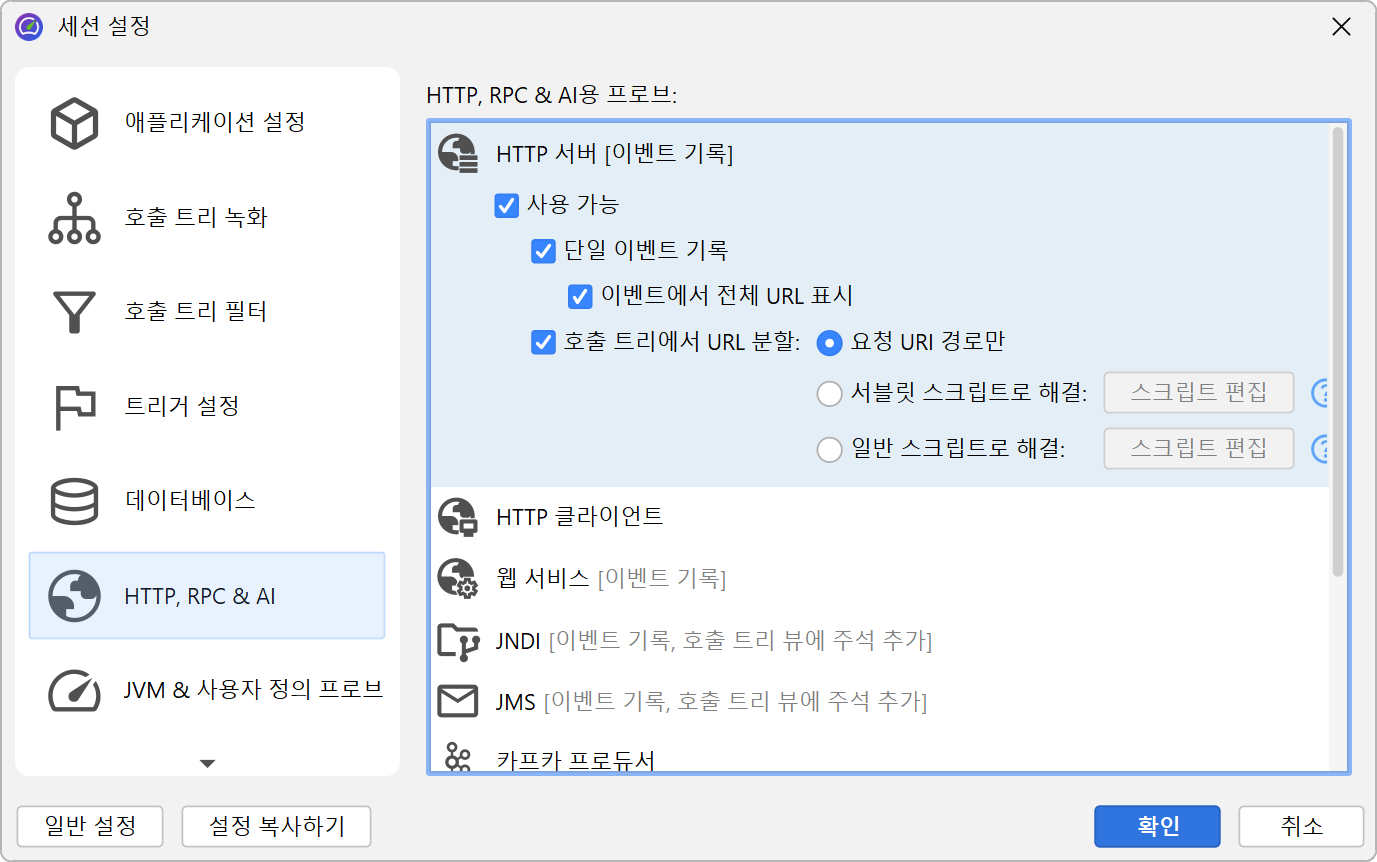
일부 프로브는 프로브 문자열을 사용하여 페이로드 데이터를 호출 트리에 주석으로 추가하지 않고, 각기 다른 프로브 문자열마다 호출 트리를 분할합니다. 이는 서버 타입 프로브에서 특히 유용하며, 서로 다른 유형의 요청마다 호출 트리를 별도로 보고 싶을 때 사용됩니다. "HTTP server" 프로브는 URL을 가로채어, URL의 어떤 부분을 호출 트리 분할에 사용할지 세밀하게 제어할 수 있습니다. 기본적으로 요청 URI 경로만 사용하며, 파라미터는 포함하지 않습니다.
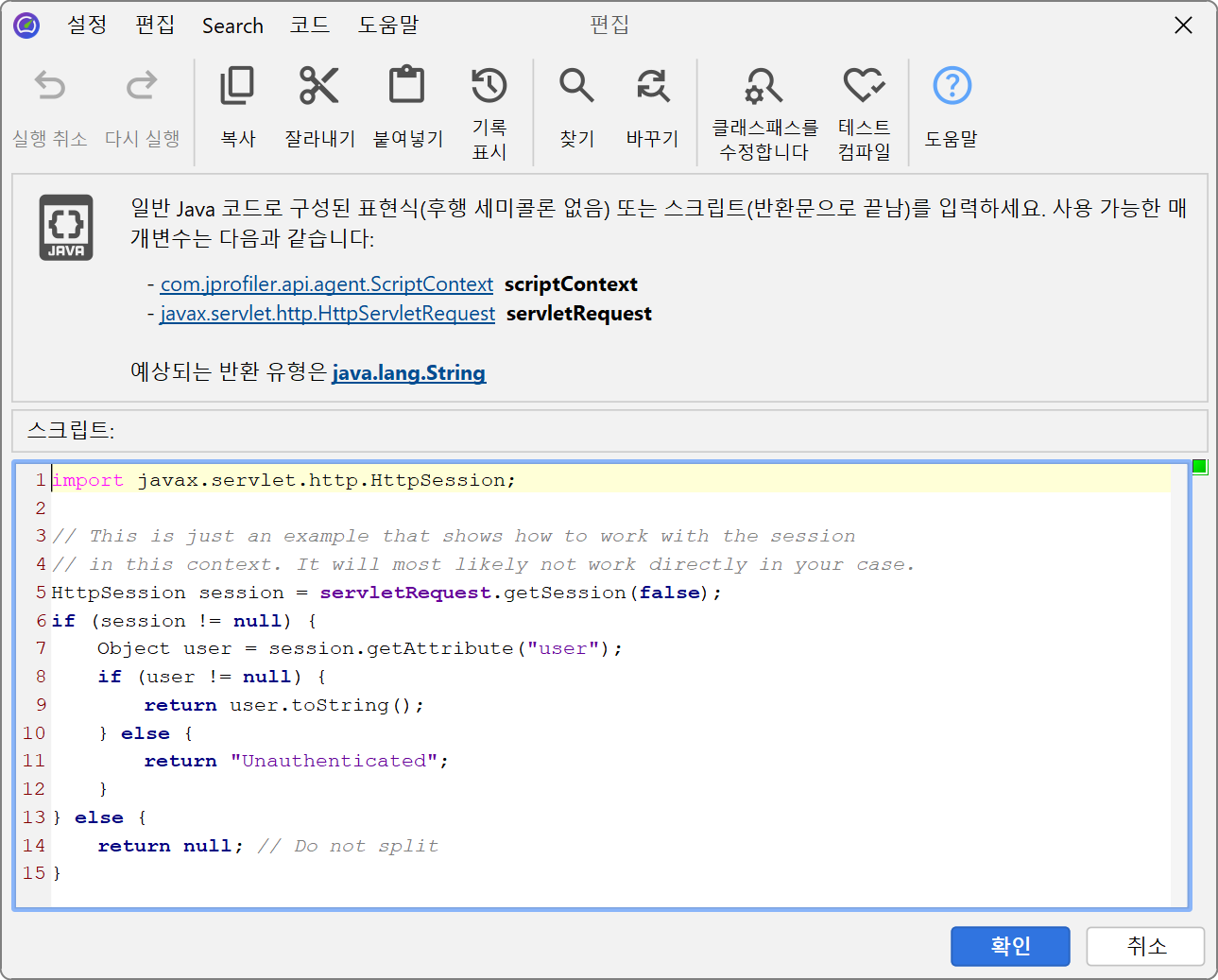
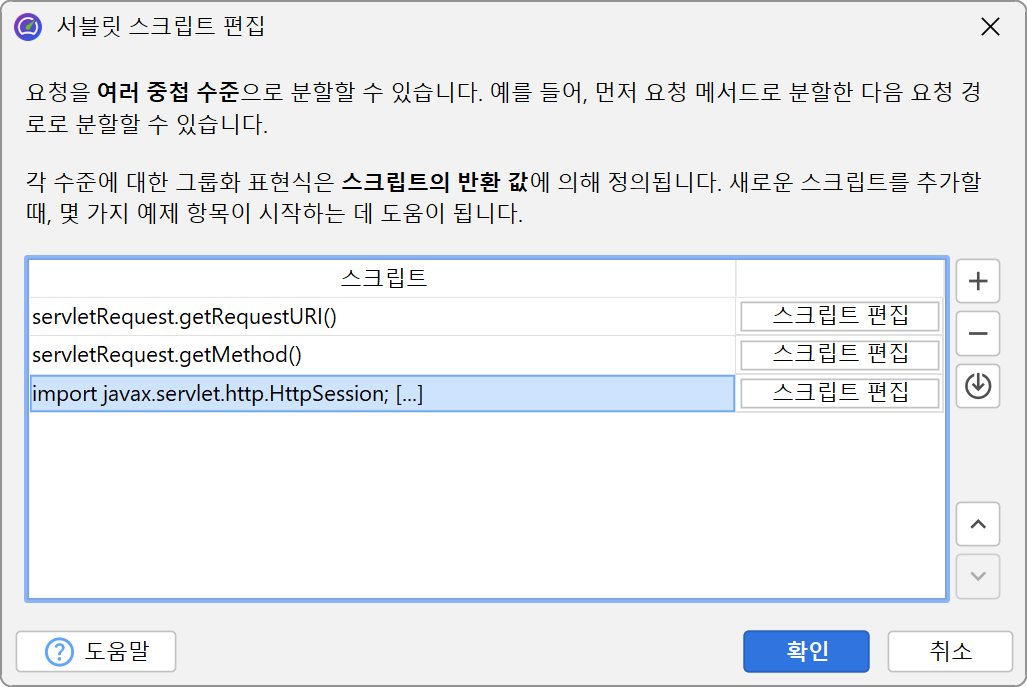
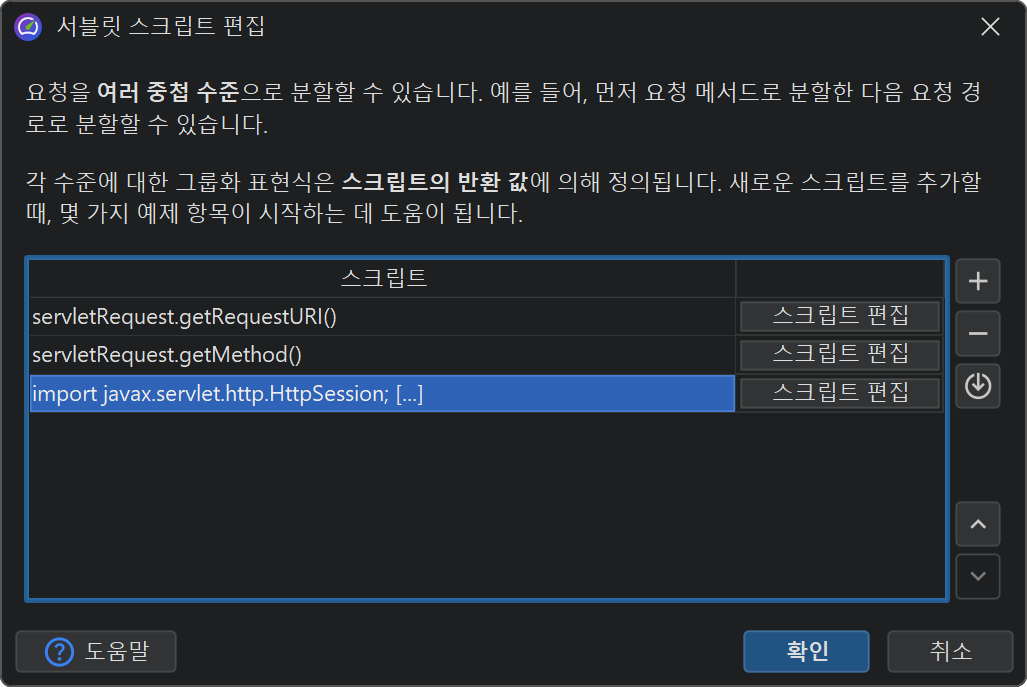
더 유연하게 사용하려면, 분할 문자열을 결정하는 스크립트를 정의할 수 있습니다. 스크립트에서는 현재 javax.servlet.http.HttpServletRequest를
파라미터로 받아 원하는 문자열을 반환합니다.
또한 단일 분할 수준에만 국한되지 않고, 여러 중첩 분할을 정의할 수 있습니다. 예를 들어, 먼저 요청 URI 경로로 분할한 뒤, HTTP 세션 객체에서 추출한 사용자 이름으로 다시 분할할 수 있습니다. 또는 요청 메서드별로 그룹화한 뒤, 요청 URI로 분할할 수도 있습니다.
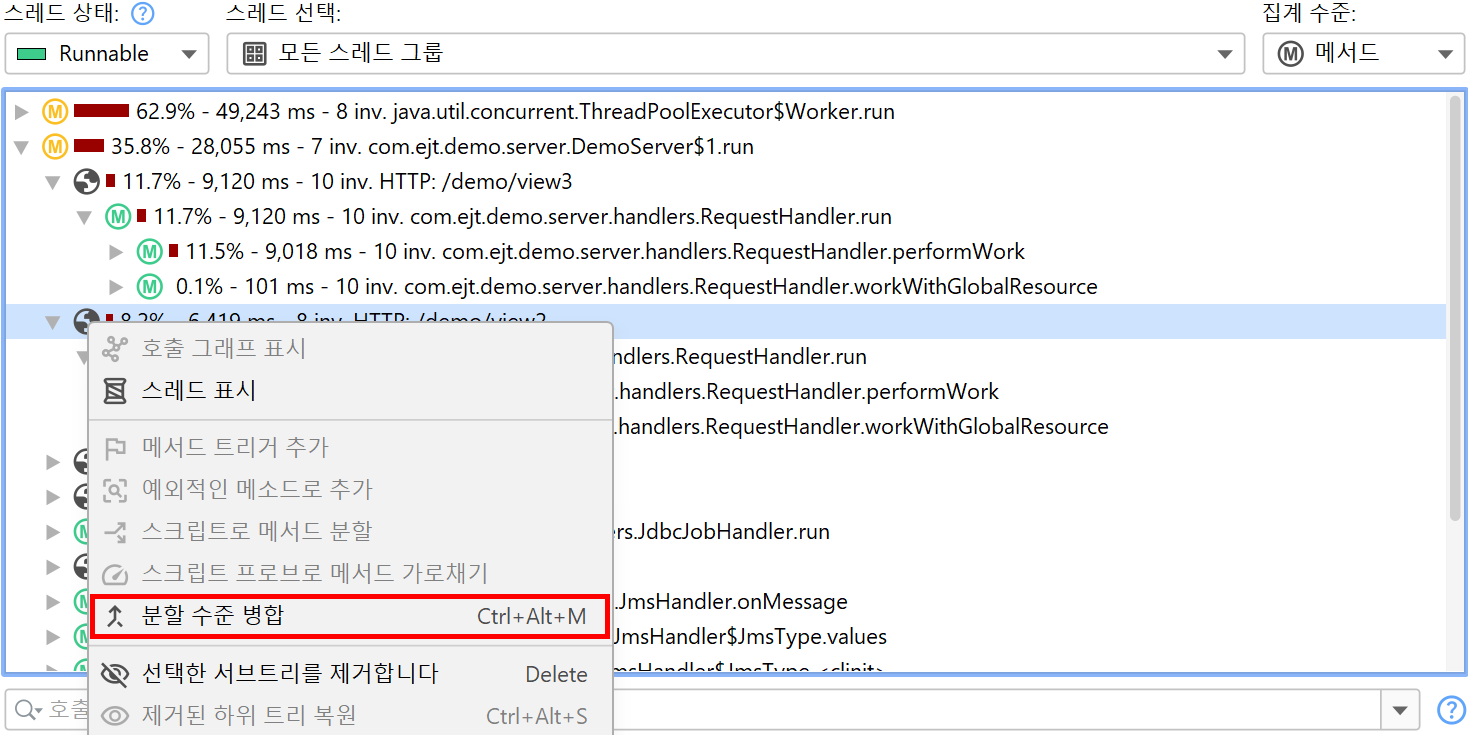
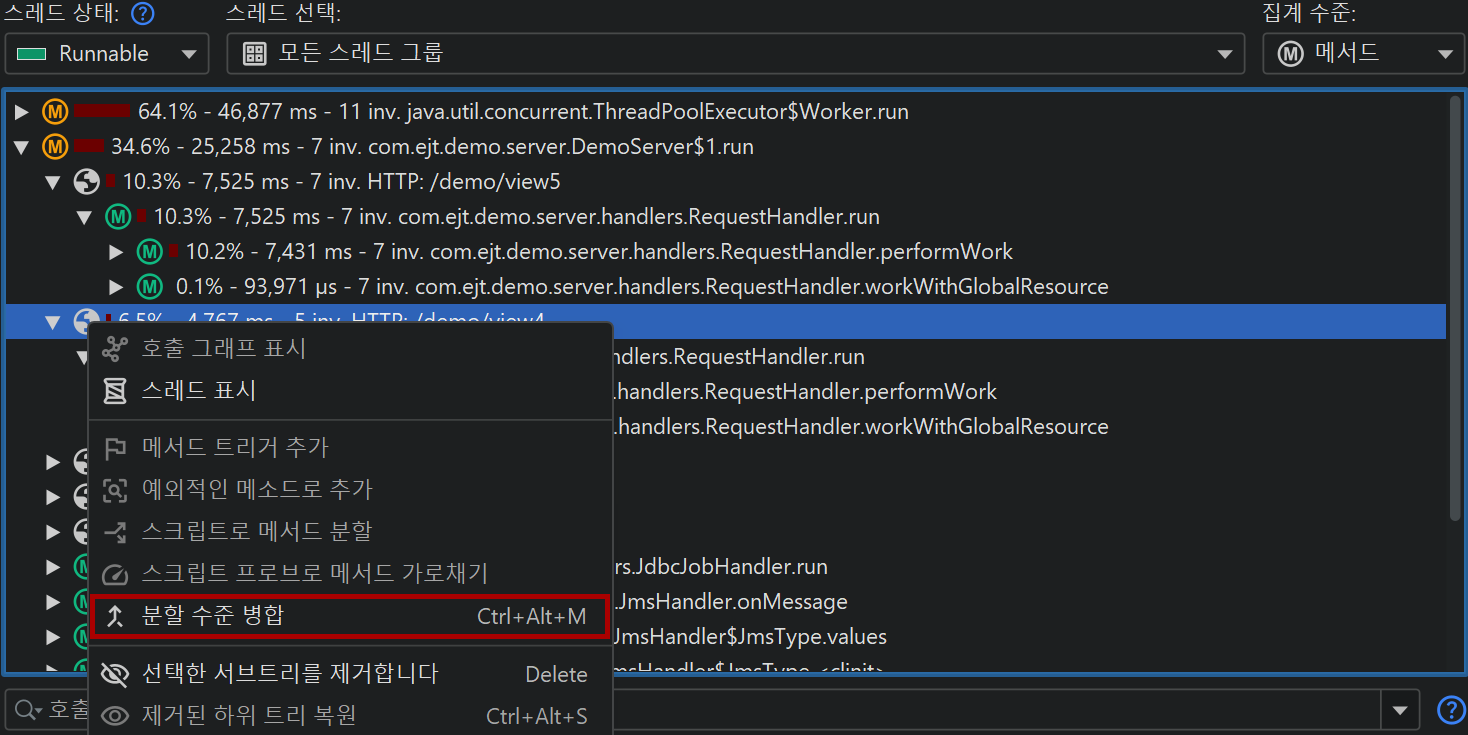
중첩 분할을 사용하면, 호출 트리의 각 수준별로 별도의 데이터를 볼 수 있습니다. 호출 트리를 볼 때 특정 수준이 불필요하다면, "HTTP server" 프로브 설정에서 해당 수준을 제거할 수 있습니다. 더 편리하게는, 기록된 데이터를 잃지 않고도 호출 트리에서 해당 분할 노드의 컨텍스트 메뉴를 사용해 분할 수준을 일시적으로 병합/해제할 수 있습니다.
호출 트리 분할은 상당한 메모리 오버헤드를 유발할 수 있으므로 신중하게 사용해야 합니다. 메모리 과부하를 방지하기 위해 JProfiler는 분할의 최대 개수를 제한합니다. 특정 분할 수준에서 상한에 도달하면, "[capped nodes]" 분할 노드가 추가되고, 상한 카운터를 재설정하는 하이퍼링크가 제공됩니다. 기본 상한이 너무 낮으면, 프로파일링 설정에서 값을 높일 수 있습니다.