힙 스냅샷
객체 간의 참조를 포함하는 모든 힙 분석은 힙 스냅샷이 필요합니다. JVM에 객체로 들어오는 참조를 직접 물어볼 수 없기 때문입니다. 해당 질문에 답하려면 전체 힙을 반복적으로 탐색해야 합니다. 이 힙 스냅샷에서 JProfiler는 힙 워커의 뷰에 필요한 데이터를 제공하기 위해 최적화된 내부 데이터베이스를 생성합니다.
힙 스냅샷의 소스는 두 가지가 있습니다: JProfiler 힙 스냅샷과 HPROF/PHD 힙 스냅샷입니다. JProfiler 힙 스냅샷은 힙 워커의 모든 기능을 지원합니다. 프로파일링 에이전트는 JVMTI 프로파일링 인터페이스를 사용하여 모든 참조를 반복적으로 탐색합니다. 프로파일된 JVM이 다른 머신에서 실행 중인 경우, 모든 정보가 로컬 머신으로 전송되어 추가 계산이 그곳에서 수행됩니다. HPROF/PHD 스냅샷은 JVM의 내장 메커니즘으로 생성되며, JProfiler가 읽을 수 있는 표준 포맷으로 디스크에 기록됩니다. HotSpot JVM은 HPROF 스냅샷을 생성할 수 있고, Eclipse OpenJ9 JVM은 PHD 스냅샷을 제공합니다.
힙 워커의 개요 페이지에서 JProfiler 힙 스냅샷 또는 HPROF/PHD 힙 스냅샷 중 어떤 것을 생성할지 선택할 수 있습니다. 기본적으로 JProfiler 힙 스냅샷이 권장됩니다. HPROF/PHD 힙 스냅샷은 다른 챕터에서 논의되는 특별한 상황에서 유용합니다.
선택 단계
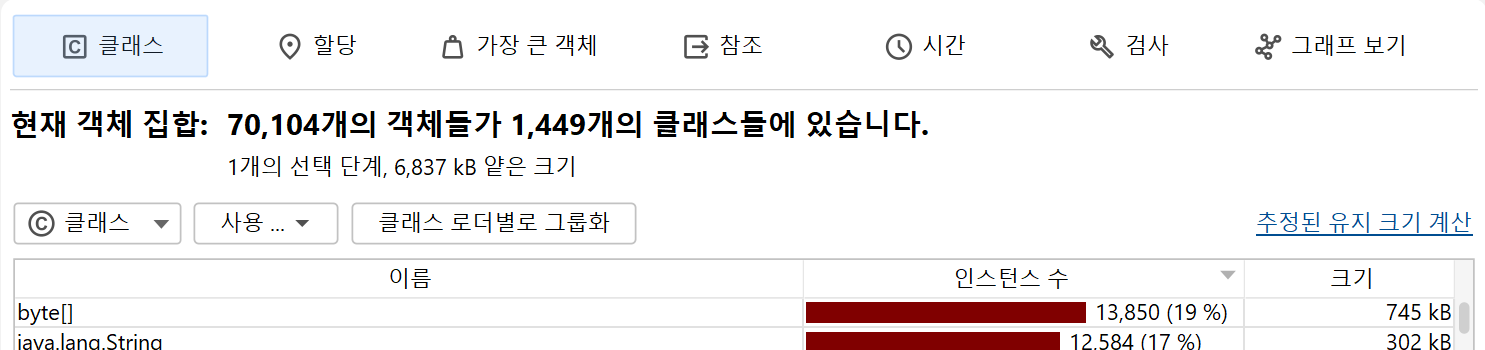
힙 워커는 선택된 객체 집합의 다양한 측면을 보여주는 여러 뷰로 구성되어 있습니다. 힙 스냅샷을 찍은 직후에는 힙에 있는 모든 객체를 보게 됩니다. 각 뷰에는 일부 선택된 객체를 현재 객체 집합으로 만드는 내비게이션 동작이 있습니다. 힙 워커의 헤더 영역에는 현재 객체 집합에 포함된 객체 수에 대한 정보가 표시됩니다.
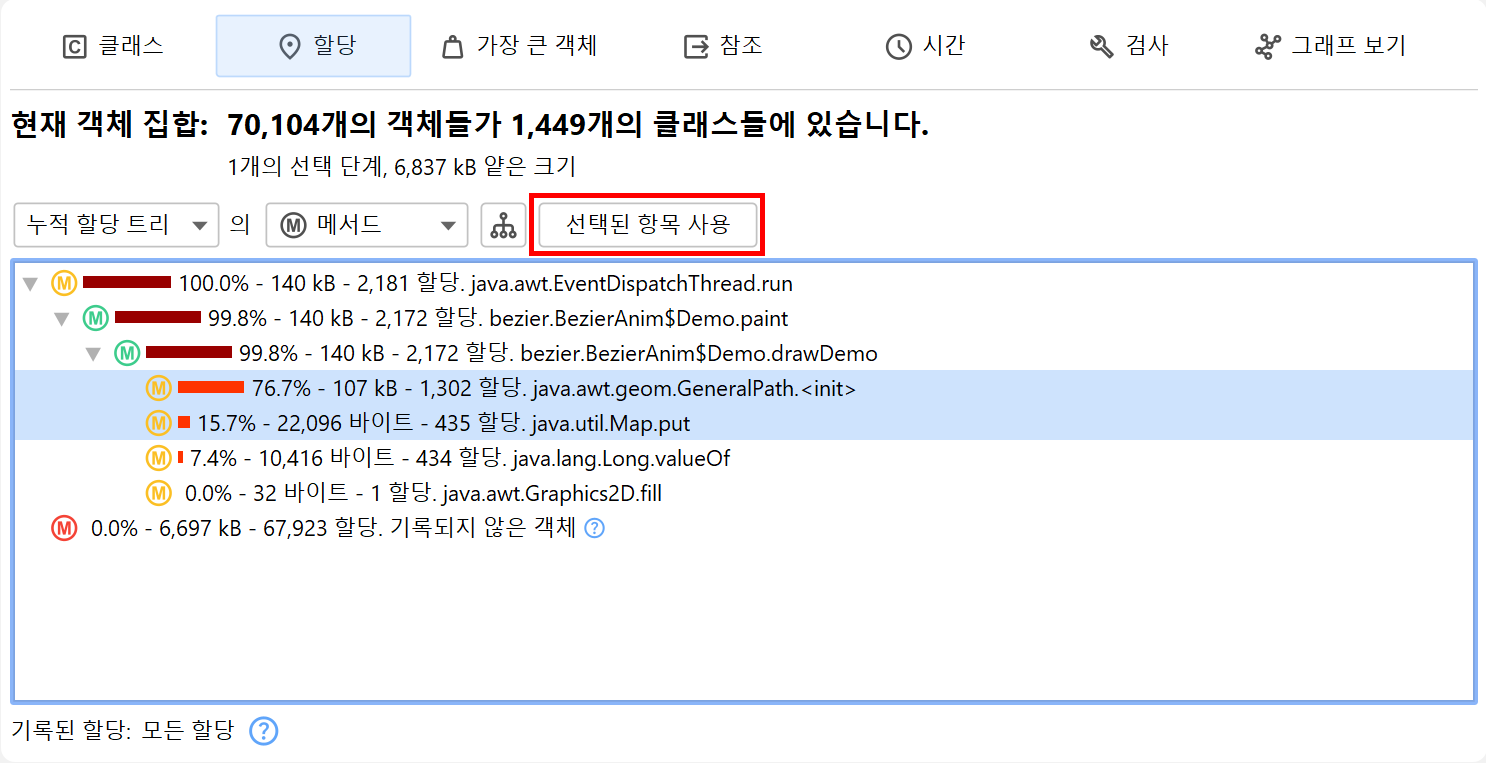
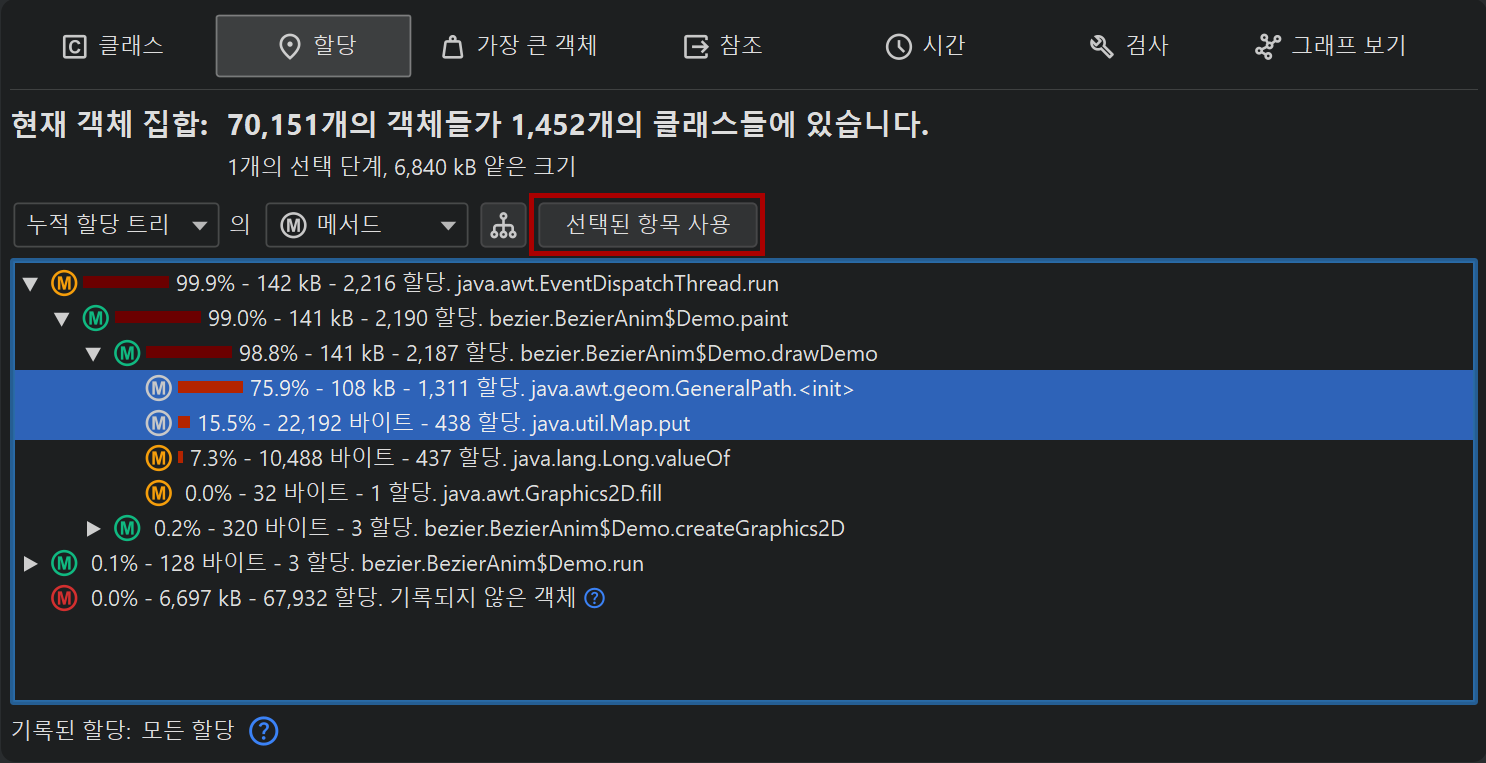
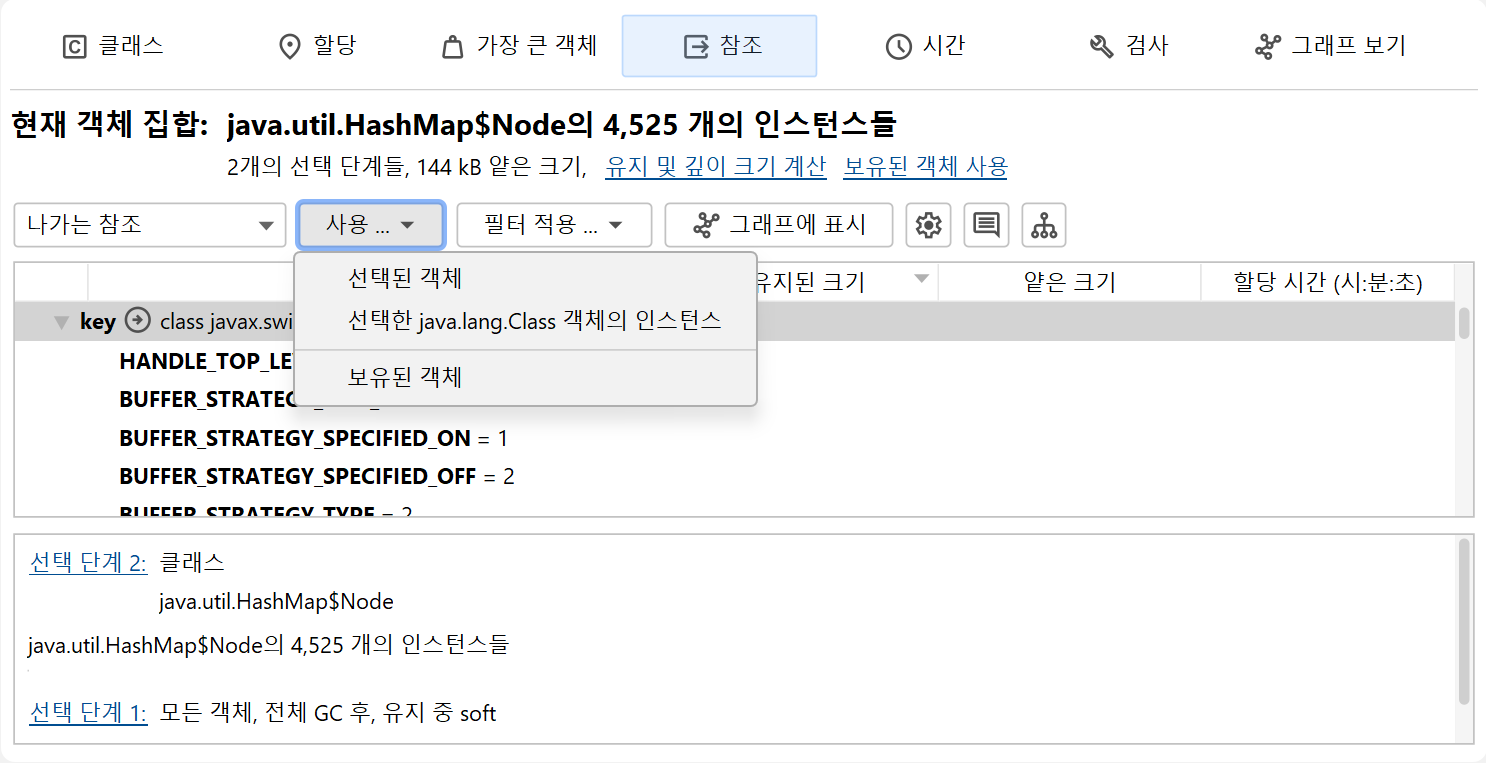
처음에는 "클래스" 뷰를 보게 되며, 이는 라이브 메모리 섹션의 "모든 객체" 뷰와 유사합니다. 클래스를 선택하고 Use→Selected Instances를 실행하면 해당 클래스의 인스턴스만 포함하는 새로운 객체 집합이 생성됩니다. 힙 워커에서 "사용"은 항상 새로운 객체 집합을 생성하는 것을 의미합니다.
새로운 객체 집합에 대해 힙 워커의 클래스 뷰를 다시 보여주는 것은 의미가 없으므로, JProfiler는 "새 객체 집합" 대화상자를 통해 다른 뷰를 제안합니다. 이 대화상자를 취소하면 새 객체 집합이 폐기되고 이전 뷰로 돌아갑니다. 기본적으로는 아웃고잉 참조 뷰가 제안되지만, 다른 뷰를 선택할 수도 있습니다. 이는 처음 표시되는 뷰에만 해당하며, 이후에는 힙 워커의 뷰 선택기에서 언제든지 뷰를 전환할 수 있습니다.
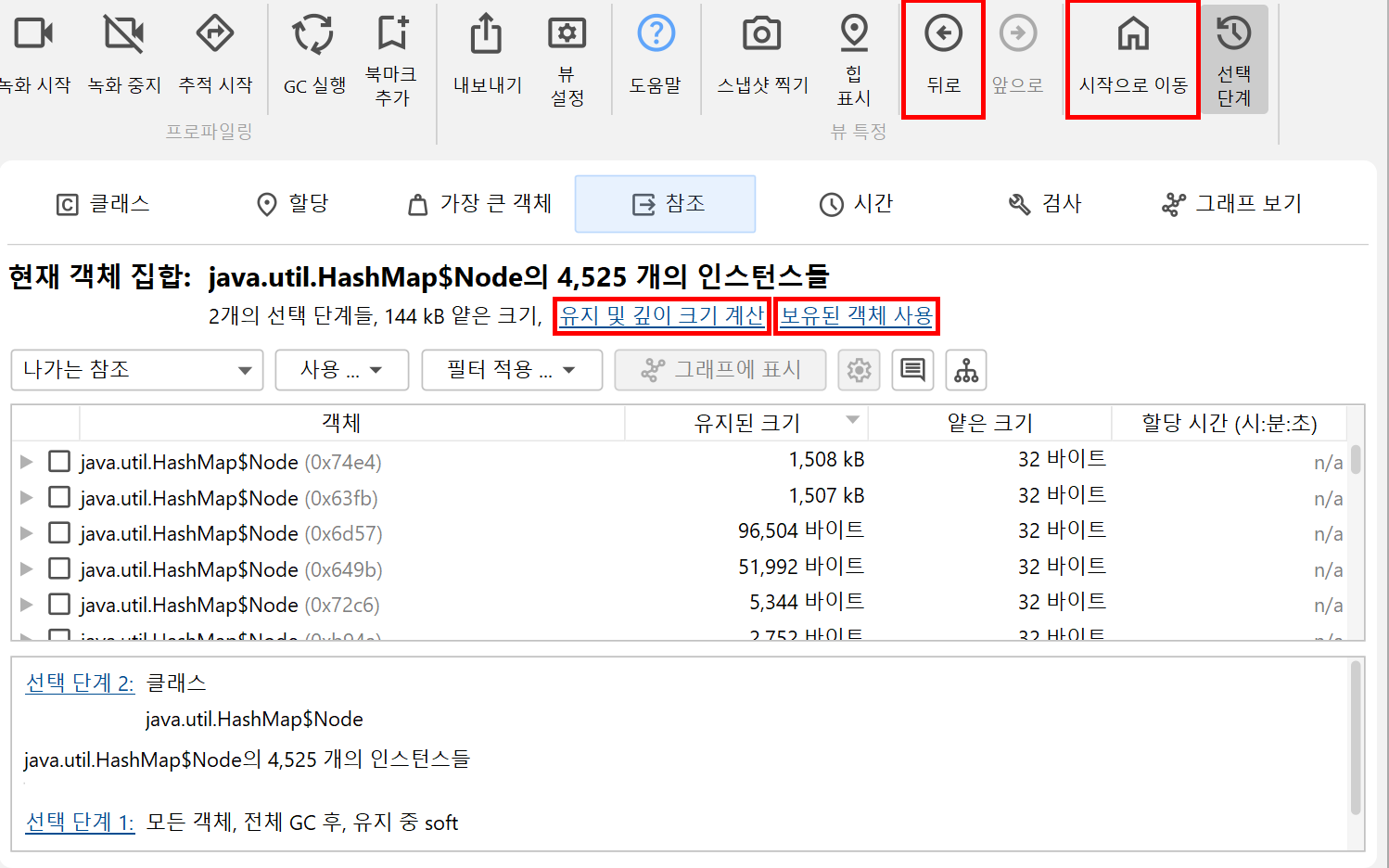
헤더 영역에는 이제 두 개의 선택 단계가 있음을 알려주며, 유지 및 딥 사이즈 계산 또는 현재 객체 집합에 의해 유지되는 모든 객체를 사용하는 링크가 포함되어 있습니다. 후자의 경우 또 다른 선택 단계가 추가되고, 해당 객체 집합에 여러 클래스가 있을 가능성이 있으므로 클래스 뷰가 제안됩니다.
힙 워커 하단에는 지금까지의 선택 단계가 나열됩니다. 하이퍼링크를 클릭하면 어느 선택 단계로든 돌아갈 수 있습니다. 첫 번째 데이터 집합은 툴바의 Go To Start 버튼으로도 접근할 수 있습니다. 툴바의 뒤로/앞으로 버튼은 분석 중에 되돌아가야 할 때 유용합니다.
클래스 뷰
힙 워커 상단의 뷰 선택기에는 현재 객체 집합에 대한 다양한 정보를 보여주는 다섯 개의 뷰가 있습니다. 그 중 첫 번째가 "클래스" 뷰입니다.
클래스 뷰는 라이브 메모리 섹션의 "모든 객체" 뷰와 유사하며, 클래스를 패키지로 그룹화할 수 있는 집계 수준 선택기가 있습니다. 또한 클래스별로 추정 유지 사이즈를 표시할 수 있습니다. 이는 해당 클래스의 모든 인스턴스를 힙에서 제거할 경우 해제되는 메모리 양입니다. 추정 유지 사이즈 계산 하이퍼링크를 클릭하면 새로운 Retained Size 컬럼이 추가됩니다. 표시되는 유지 사이즈는 추정된 하한값이며, 정확한 수치를 계산하는 것은 너무 느릴 수 있습니다. 정말로 정확한 수치가 필요하다면, 관심 있는 클래스나 패키지를 선택하고 새 객체 집합의 헤더에 있는 유지 및 딥 사이즈 계산 하이퍼링크를 사용하세요.
하나 이상의 클래스 또는 패키지를 선택하면 인스턴스 자체, 연관된 java.lang.Class 객체, 또는 모든 유지 객체를 선택할 수 있습니다.
더블 클릭은 가장 빠른 선택 모드이며, 선택된 인스턴스를 사용합니다. 이처럼 여러 선택 모드가 가능한 경우, 뷰 상단에 Use 드롭다운 메뉴가 표시됩니다.
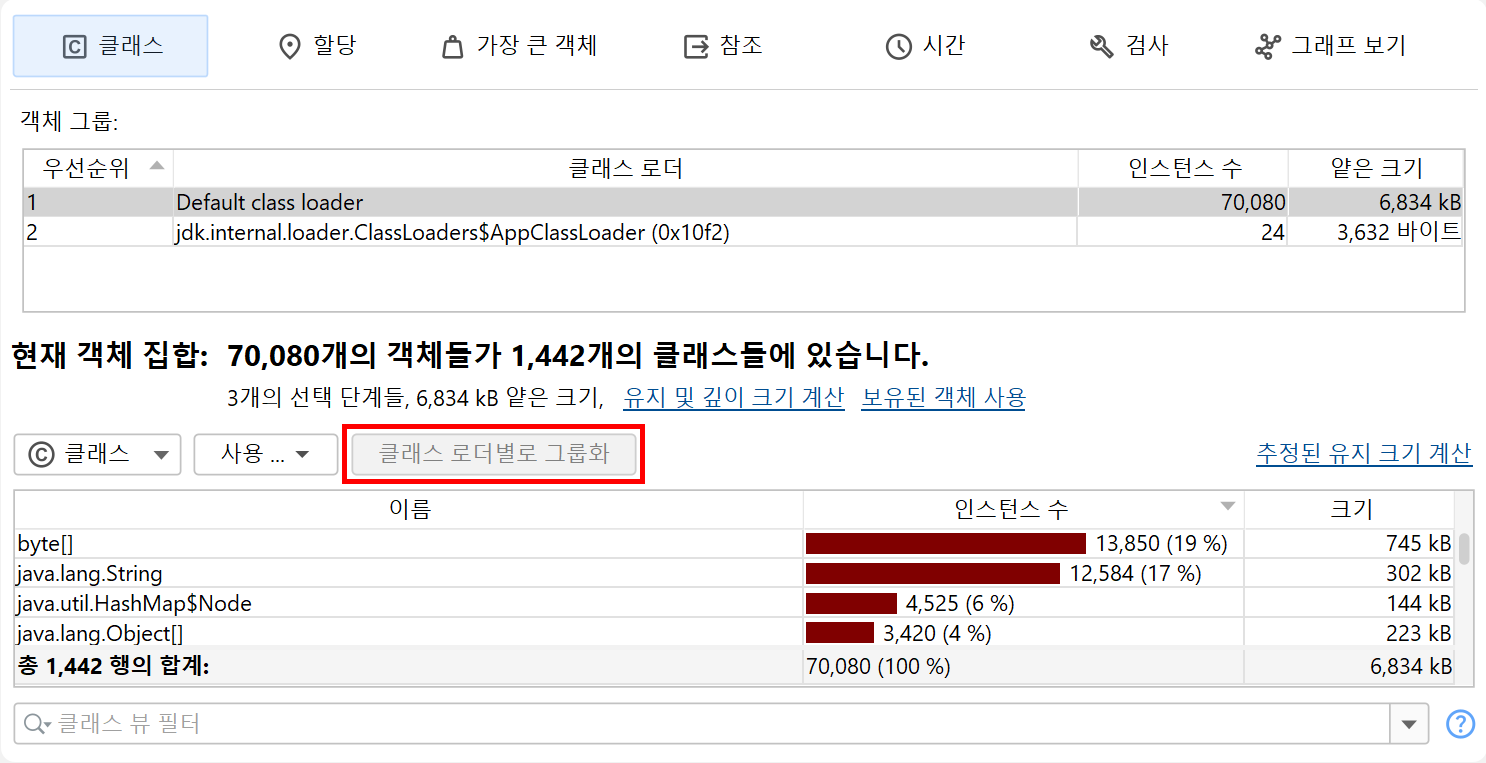
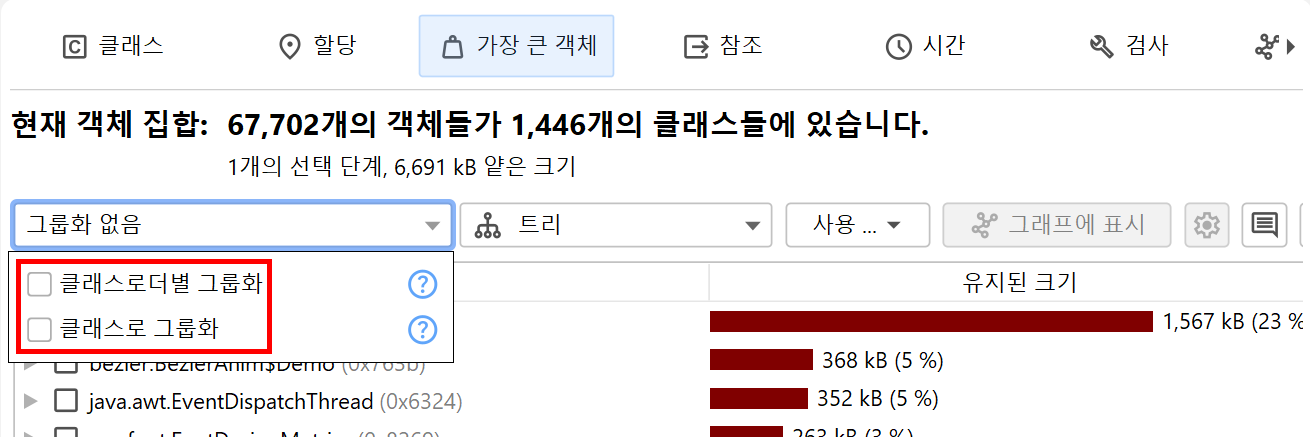
클래스 로더 관련 문제를 해결할 때는 인스턴스를 클래스 로더별로 그룹화해야 하는 경우가 많습니다. Inspections 탭에는 "클래스 로더별 그룹화" 인스펙션이 제공되며, 이는 해당 맥락에서 특히 중요하므로 클래스 뷰에서 사용할 수 있습니다. 해당 분석을 실행하면 상단의 그룹화 테이블에 모든 클래스 로더가 표시됩니다. 클래스 로더를 선택하면 아래 뷰의 데이터가 해당 로더에 맞게 필터링됩니다. 다른 뷰로 전환해도 그룹화 테이블은 유지되며, 새로운 선택 단계를 수행할 때까지 계속 표시됩니다. 이후에는 클래스 로더 선택이 해당 선택 단계의 일부가 됩니다.
할당 녹화 뷰
객체가 어디에서 할당되었는지에 대한 정보는 메모리 누수 의심 대상을 좁히거나 메모리 사용량을 줄이고자 할 때 중요할 수 있습니다. JProfiler 힙 스냅샷의 경우, "할당" 뷰는 할당 호출 트리와 할당 핫스팟을 보여줍니다(할당이 녹화된 객체에 한함). 다른 객체들은 할당 호출 트리의 "unrecorded objects" 노드에 그룹화됩니다. HPROF/PHD 스냅샷에서는 이 뷰를 사용할 수 없습니다.
클래스 뷰와 마찬가지로 여러 노드를 선택하고 상단의 Use Selected 버튼을 사용하여 새로운 선택 단계를 만들 수 있습니다. "할당 핫스팟" 뷰 모드에서는 백트레이스에서도 노드를 선택할 수 있습니다. 이 경우, 선택된 백트레이스로 끝나는 호출 스택에서 할당된 해당 핫스팟의 객체만 선택됩니다.
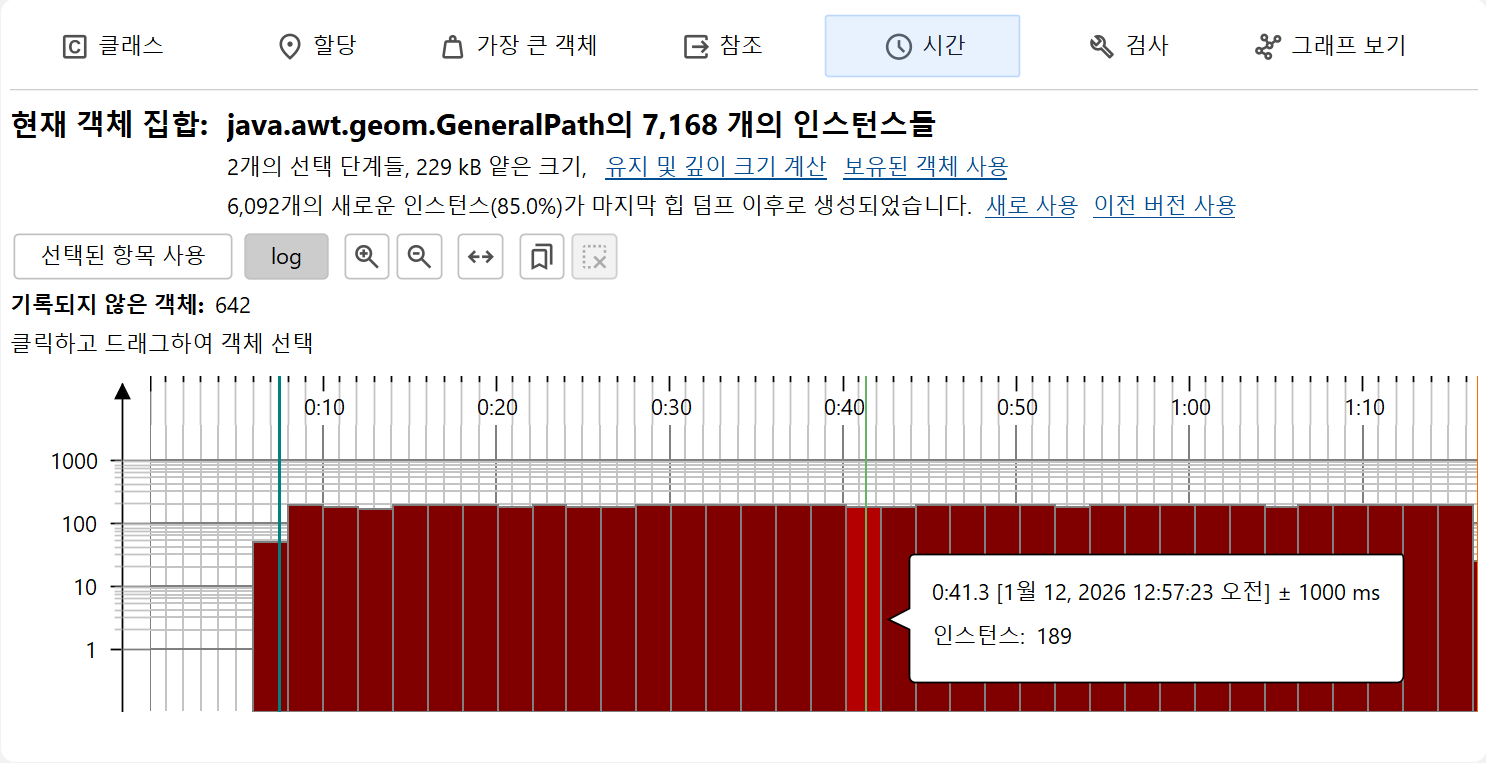
JProfiler가 할당을 녹화할 때 저장할 수 있는 또 다른 정보는 객체가 할당된 시점입니다. 힙 워커의 "시간" 뷰는 현재 객체 집합의 모든 녹화된 인스턴스에 대한 할당 시간 히스토그램을 보여줍니다. 클릭 및 드래그로 하나 이상의 구간을 선택한 후 Use Selected 버튼으로 새로운 객체 집합을 만들 수 있습니다.
시간 구간을 더 정밀하게 선택하려면 북마크 범위를 지정할 수 있습니다. 첫 번째와 마지막으로 선택된 북마크 사이의 모든 객체가 표시됩니다.
시간 뷰 외에도, 할당 시간은 참조 뷰의 별도 컬럼으로 표시됩니다. 단, 할당 시간 녹화는 기본적으로 활성화되어 있지 않습니다. 시간 뷰에서 바로 활성화하거나, 세션 설정 대화상자의 고급 설정 -> 메모리 프로파일링에서 설정을 변경할 수 있습니다.
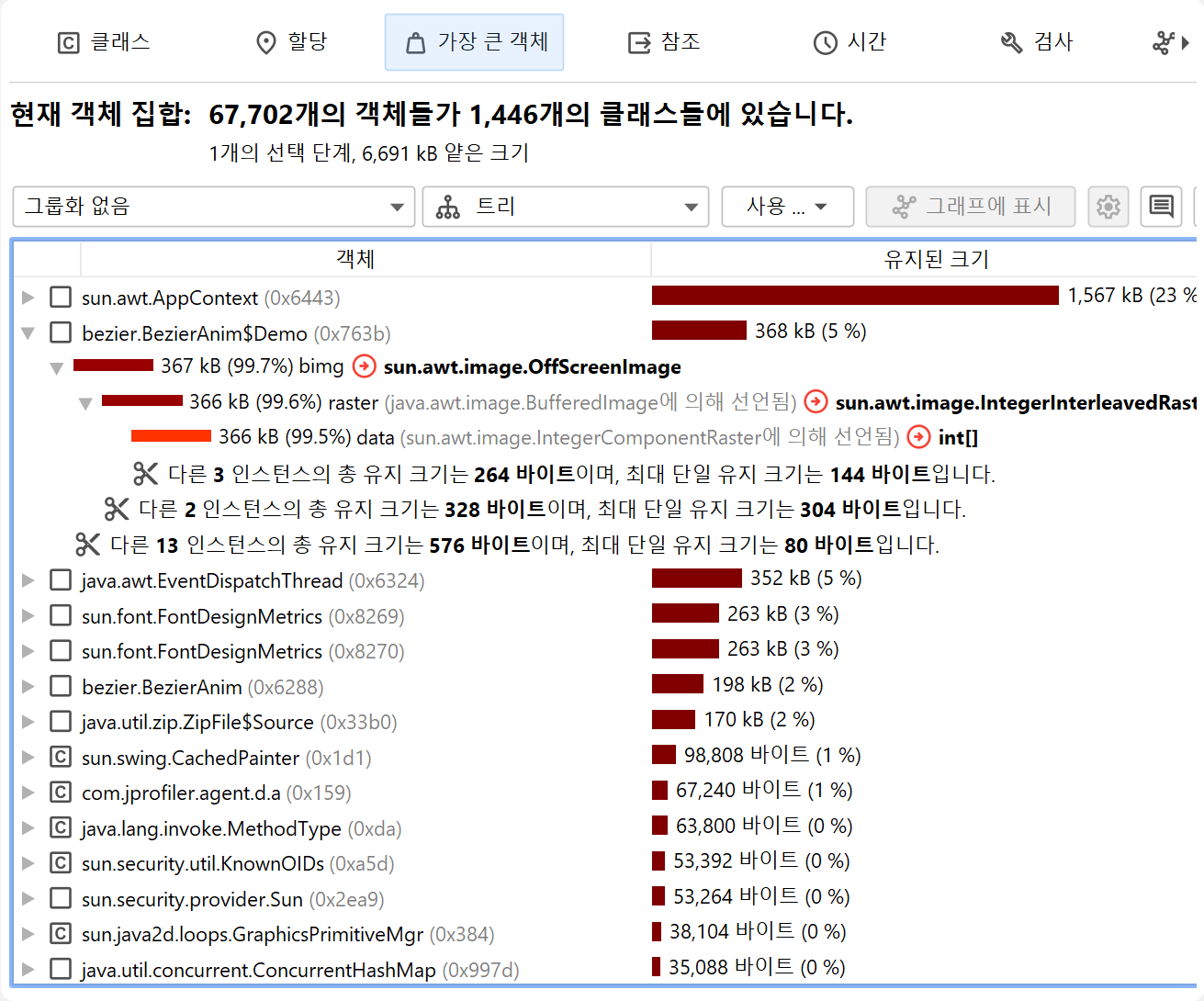
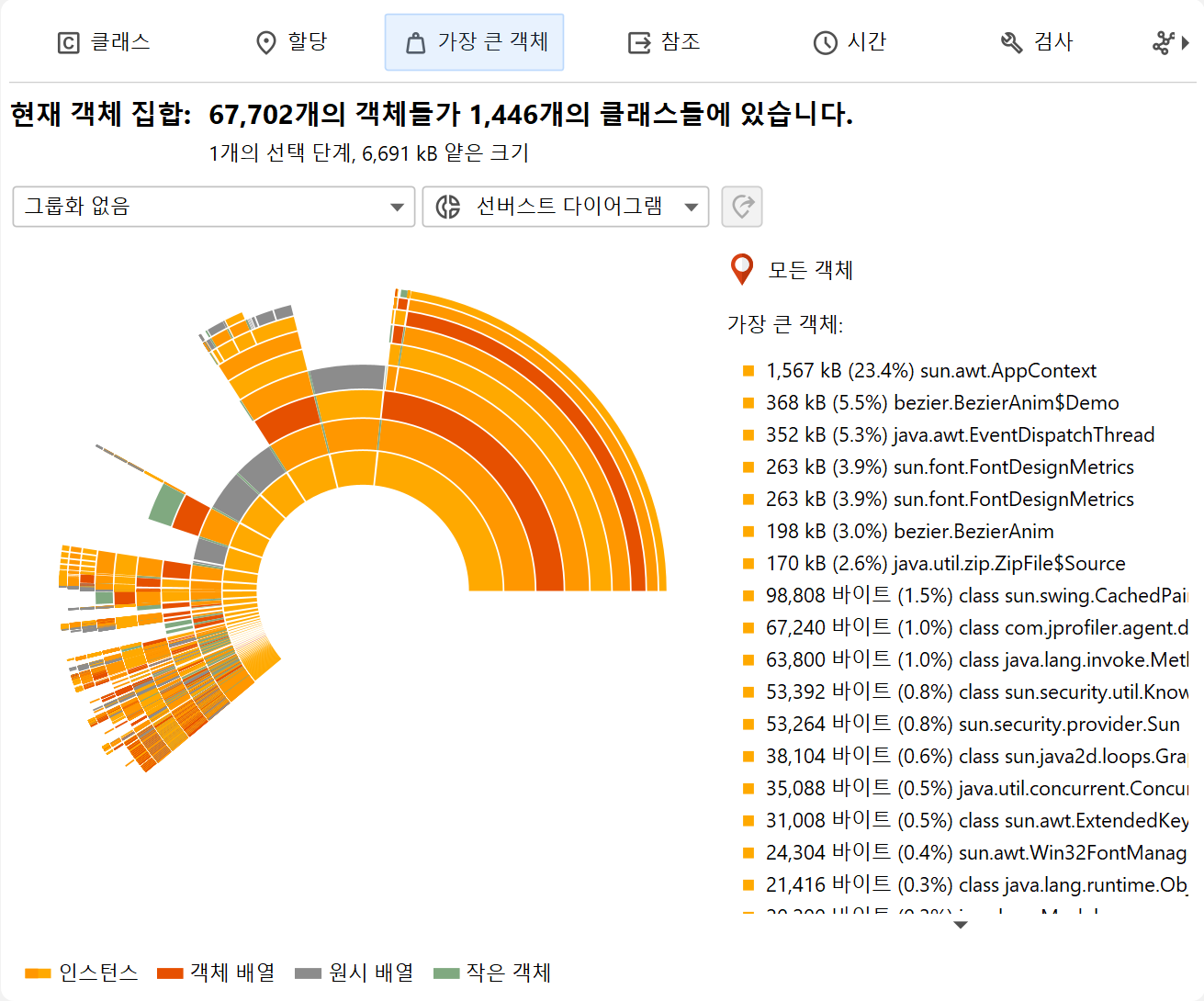
가장 큰 객체 뷰
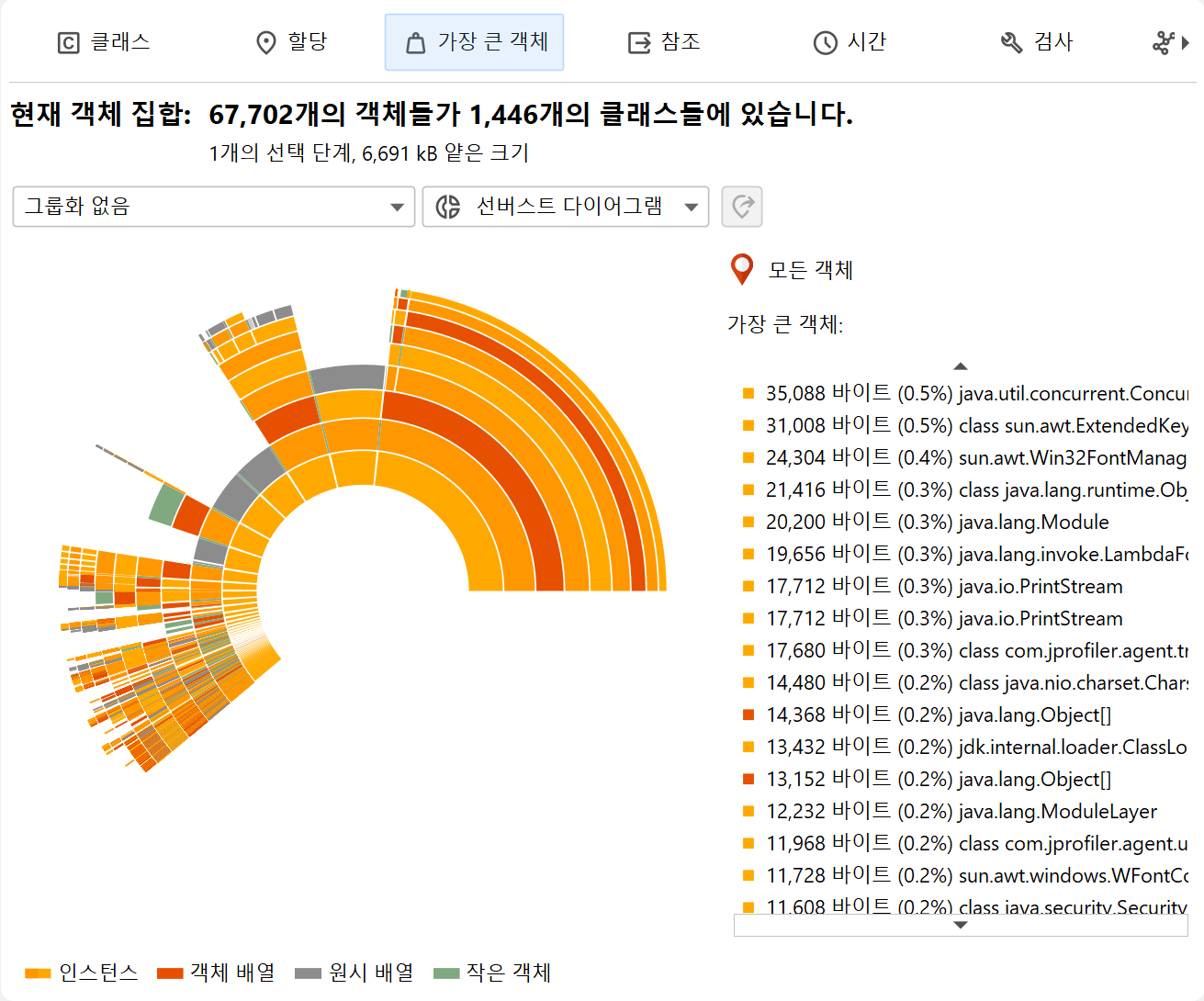
가장 큰 객체 뷰는 현재 객체 집합에서 가장 중요한 객체 목록을 보여줍니다. 여기서 "가장 큰"이란, 해당 객체를 힙에서 제거할 경우 가장 많은 메모리가 해제되는 객체를 의미합니다. 이 크기를 유지 사이즈라고 합니다. 반면, 딥 사이즈는 강한 참조를 통해 도달 가능한 모든 객체의 총 크기입니다.
각 객체는 이 객체에 의해 유지되는 다른 객체로의 아웃고잉 참조를 확장하여 볼 수 있습니다. 이 방식으로, 상위 객체가 제거될 경우 가비지 컬렉션될 유지 객체 트리를 재귀적으로 확장할 수 있습니다. 이러한 트리를 "도미네이터 트리"라고 부릅니다. 이 트리의 각 객체에 표시되는 정보는 아웃고잉 참조 뷰와 유사하지만, 도미네이팅 참조만 표시됩니다.
모든 도미네이트된 객체가 도미네이터에 의해 직접 참조되는 것은 아닙니다. 예를 들어, 아래 그림의 참조를 고려해보세요:
객체 A는 객체 B1, B2를 도미네이트하지만, 객체 C에 직접 참조를 가지고 있지 않습니다. B1과 B2 모두 C를 참조합니다. B1과 B2는 C를 도미네이트하지 않지만, A는 C를 도미네이트합니다. 이 경우, B1, B2, C는 도미네이터 트리에서 A의 직접 자식으로 나열되며, C는 B1과 B2의 자식으로는 표시되지 않습니다. B1과 B2의 경우, A에서 해당 객체를 보유하는 필드명이 표시됩니다. C의 경우, 참조 노드에 "[transitive reference]"가 표시됩니다.
도미네이터 트리의 각 참조 노드 왼쪽에는 상위 객체의 유지 사이즈 중 대상 객체가 여전히 유지하는 비율을 보여주는 사이즈 바가 있습니다. 트리에서 더 깊이 들어갈수록 이 수치는 감소합니다. 뷰 설정에서 퍼센트 기준을 전체 힙 사이즈로 변경할 수 있습니다.
도미네이터 트리에는 내장 컷오프가 있어, 부모 객체의 유지 사이즈의 0.5% 미만인 모든 객체를 제거합니다. 이는 중요하지 않은 작은 객체의 과도하게 긴 목록을 방지하기 위함입니다. 컷오프가 발생하면, 해당 레벨에서 표시되지 않은 객체 수, 총 유지 사이즈, 단일 객체의 최대 유지 사이즈를 알려주는 특별한 "cutoff" 자식 노드가 표시됩니다.
단일 객체 대신, 도미네이터 트리는 가장 큰 객체를 클래스별로 그룹화할 수도 있습니다. 뷰 상단의 그룹화 드롭다운에 이 표시 모드를 활성화하는 체크박스가 있습니다. 또한, 클래스 로더 그룹화를 최상위에 추가할 수 있습니다. 클래스 로더 그룹화는 가장 큰 객체가 계산된 후 적용되며, 해당 객체의 클래스를 누가 로드했는지 보여줍니다. 특정 클래스 로더의 가장 큰 객체만 분석하고 싶다면, 먼저 "클래스 로더별 그룹화" 인스펙션을 사용할 수 있습니다.
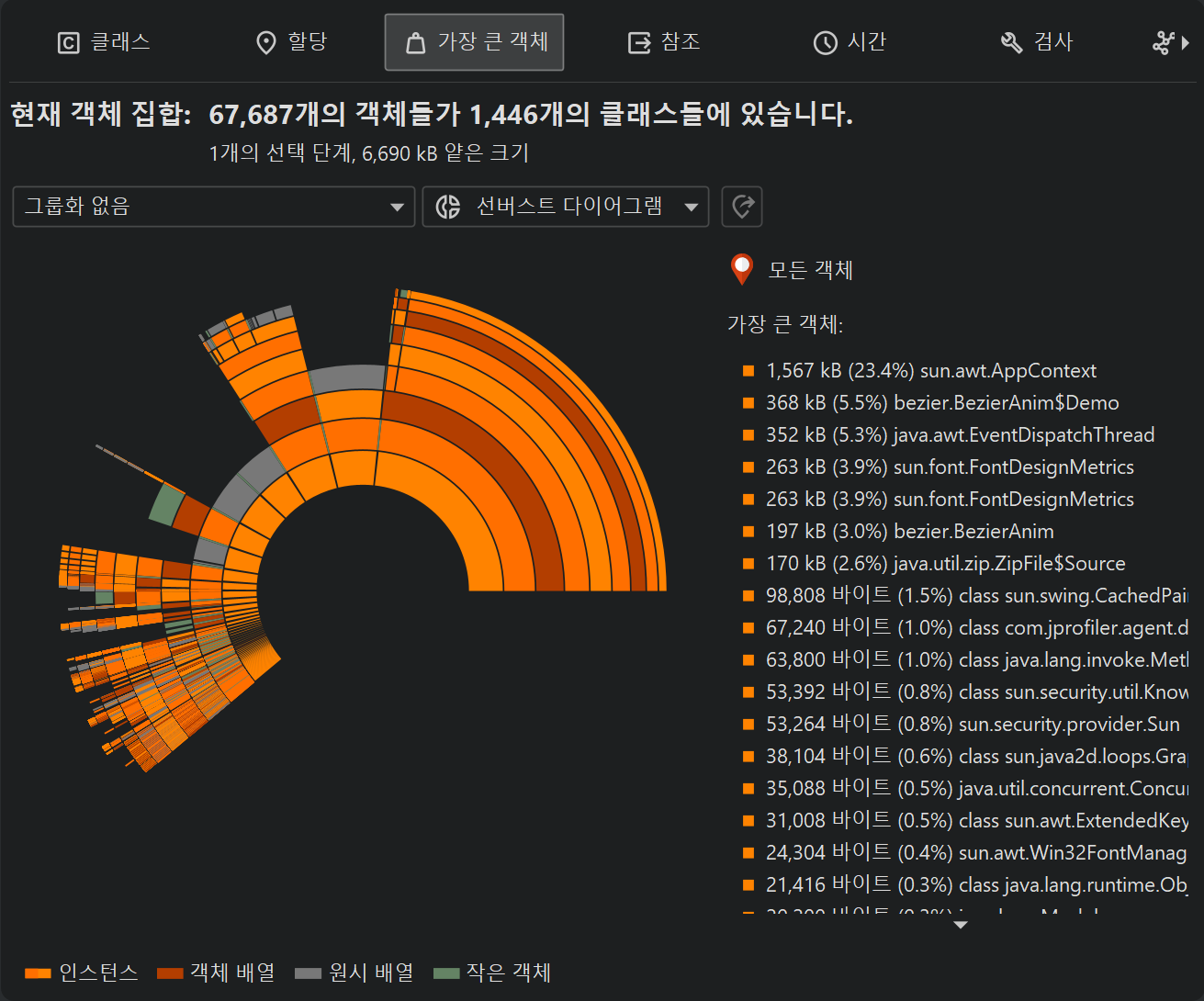
가장 큰 객체 뷰 상단의 뷰 모드 선택기를 통해 sunburst 다이어그램으로 전환할 수 있습니다. 이 다이어그램은 동심원의 분할된 링 시리즈로 구성되어 있으며, 도미네이터 트리의 전체 내용을 최대 깊이까지 한 이미지로 보여줍니다. 참조는 가장 안쪽 링에서 시작해 바깥 원둘레로 확장됩니다. 이 시각화는 높은 정보 밀도의 평면적 관점을 제공하여 참조 패턴을 발견하고, 특수 색상 코딩을 통해 대형 primitive 및 객체 배열을 한눈에 볼 수 있게 해줍니다.
현재 객체 집합이 전체 힙인 경우, 원의 전체 둘레는 사용된 힙 사이즈에 해당합니다. 가장 큰 객체 뷰는 전체 힙의 0.1% 이상을 유지하는 객체만 표시하므로, 상당한 섹터가 비어 있게 되며, 이는 가장 큰 객체에 의해 유지되지 않는 모든 객체에 해당합니다.
링 세그먼트를 클릭하면 원의 새로운 루트가 설정되어, 다이어그램에서 볼 수 있는 최대 깊이가 확장됩니다. 다이어그램의 중앙을 클릭하면 이전 루트로 복원됩니다. 새 루트가 설정된 경우, 원의 전체 둘레는 루트 객체의 유지 사이즈에 해당합니다. 빈 섹터는 루트 객체의 자체 크기와, 가장 큰 유지 객체 목록에 없는 추가 객체를 나타냅니다. 현재 객체 집합이 전체 힙이 아닌 경우, 원의 전체 둘레는 표시된 가장 큰 객체의 합계에 해당하며 빈 섹터는 표시되지 않습니다.
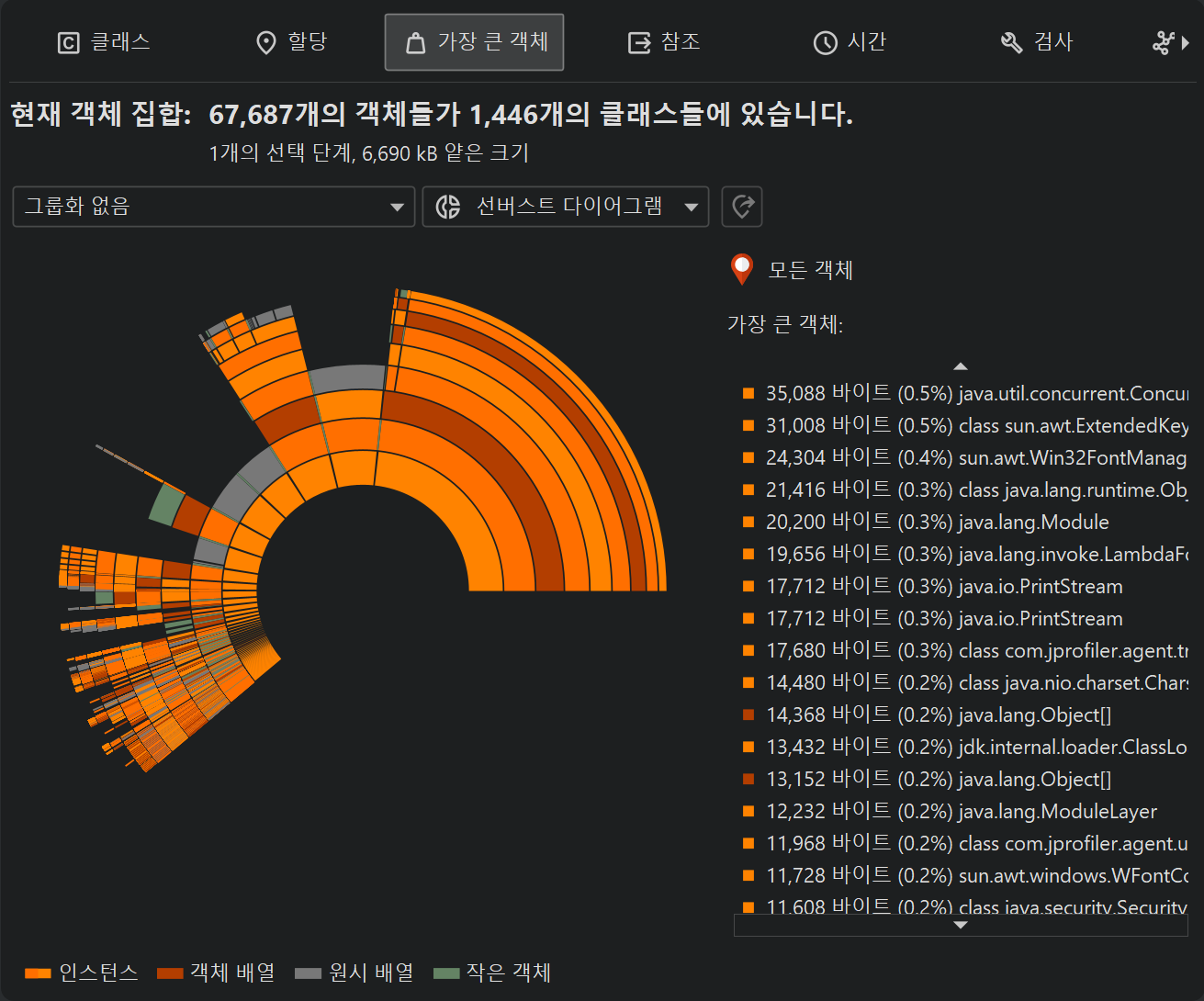
인스턴스 및 즉시 유지 객체에 대한 추가 정보는 마우스를 올리면 다이어그램 오른쪽에 표시됩니다. 마우스가 어떤 링 세그먼트에도 없을 때는 오른쪽 목록에 가장 안쪽 링의 가장 큰 객체가 표시됩니다. 해당 목록에 마우스를 올리면 해당 링 세그먼트가 하이라이트되고, 목록 항목을 클릭하면 다이어그램의 새 루트가 설정됩니다. 새로운 객체 집합을 만들려면, 링 세그먼트와 목록 항목 모두에서 컨텍스트 메뉴의 동작을 사용할 수 있습니다.
참조 뷰
이전 뷰와 달리, 참조 뷰는 적어도 하나의 선택 단계를 수행한 경우에만 사용할 수 있습니다. 초기 객체 집합에서는 이 뷰가 유용하지 않습니다. 인커밍 및 아웃고잉 참조 뷰는 모든 개별 객체를 보여주고, 병합 참조 뷰는 집중된 객체 집합에 대해서만 해석할 수 있기 때문입니다.
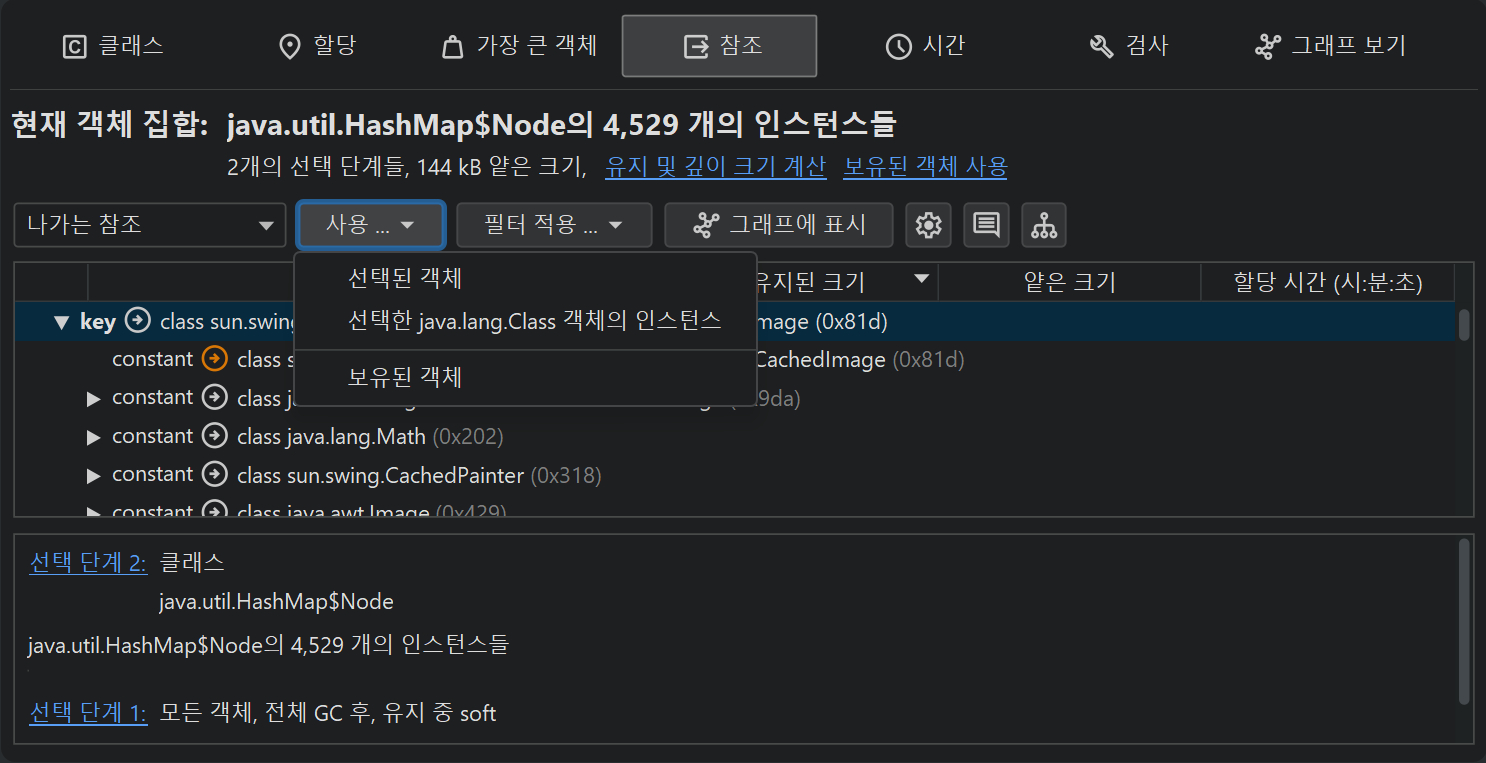
아웃고잉 참조 뷰는 IDE의 디버거가 보여주는 뷰와 유사합니다. 객체를 열면 primitive 데이터와 다른 객체에 대한 참조를 볼 수 있습니다.
모든 참조 타입은 새로운 객체 집합으로 선택할 수 있으며, 여러 객체를 한 번에 선택할 수도 있습니다.
클래스 뷰와 마찬가지로, 유지 객체나 연관된 java.lang.Class 객체를 선택할 수 있습니다.
선택된 객체가 표준 컬렉션인 경우, 한 번의 동작으로 모든 포함 요소를 선택할 수도 있습니다.
클래스 로더 객체의 경우, 로드된 모든 인스턴스를 선택하는 옵션이 있습니다.
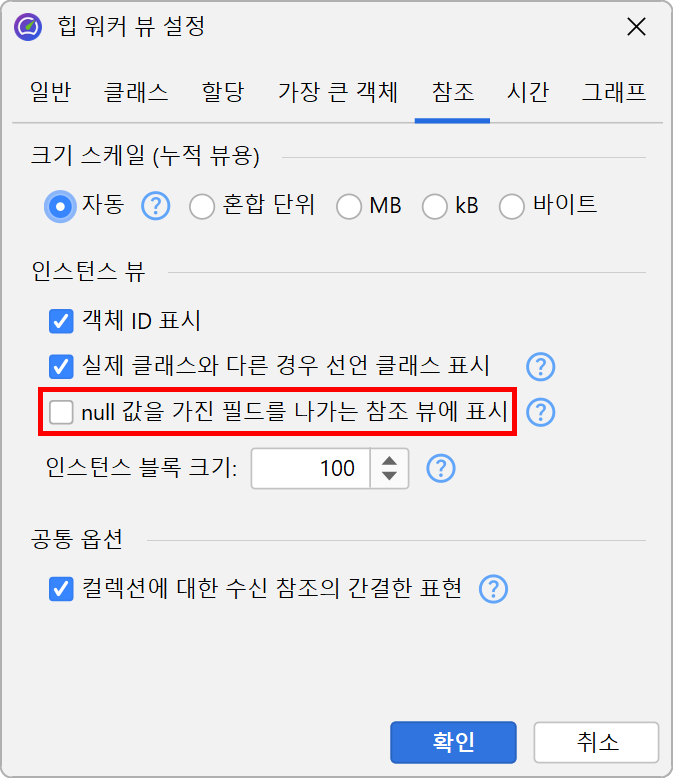
null 참조를 가진 필드는 기본적으로 표시되지 않습니다. 이는 메모리 분석 시 불필요한 정보를 줄이기 위함입니다. 디버깅 목적으로 모든 필드를 보고 싶다면, 뷰 설정에서 이 동작을 변경할 수 있습니다.
표시된 인스턴스를 단순히 선택하는 것 외에도, 아웃고잉 참조 뷰에는 강력한 필터링 기능이 있습니다. 라이브 세션에서는 아웃고잉 및 인커밍 참조 뷰 모두 고급 조작 및 표시 기능을 제공하며, 이는 동일한 챕터에서 다룹니다.
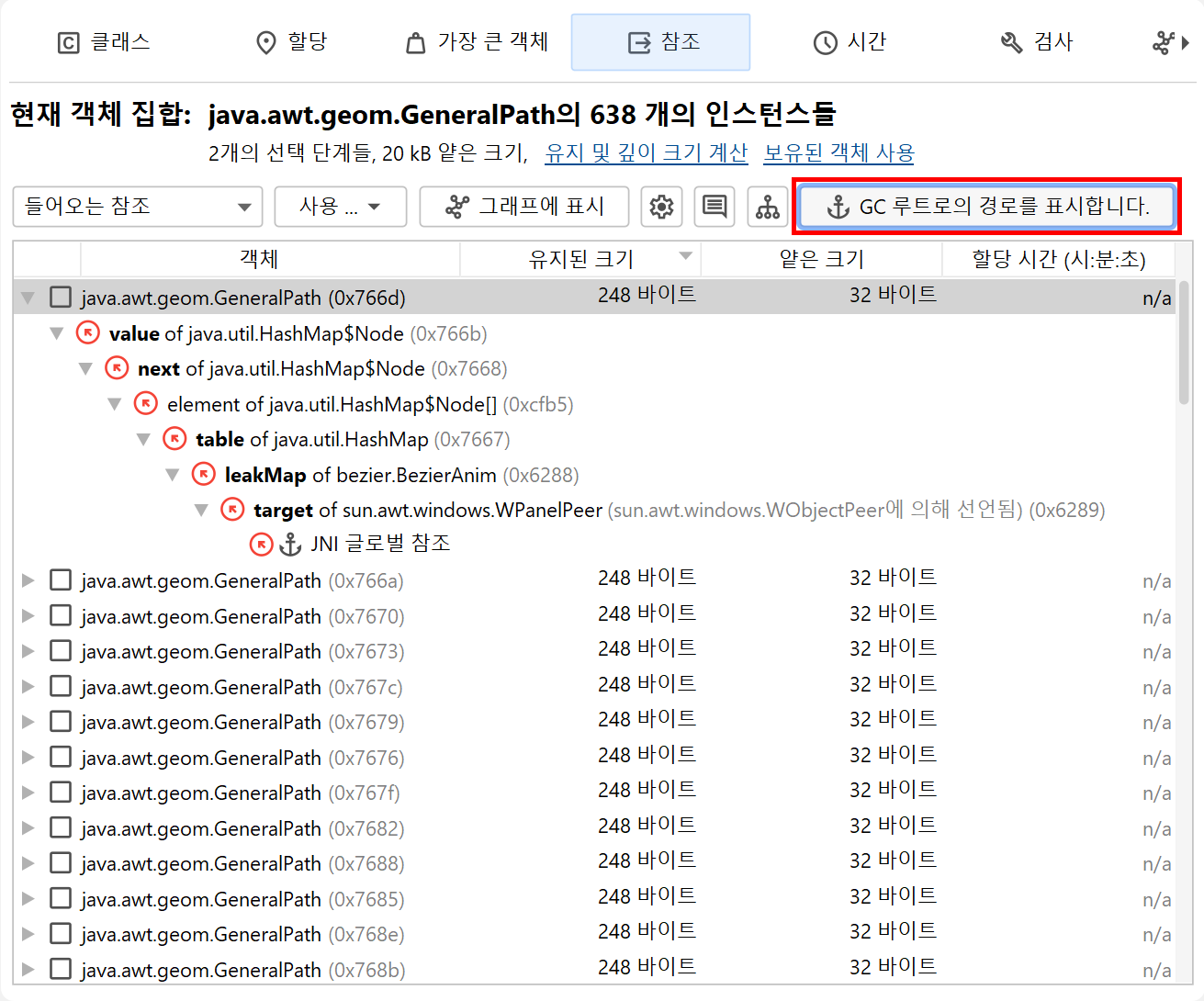
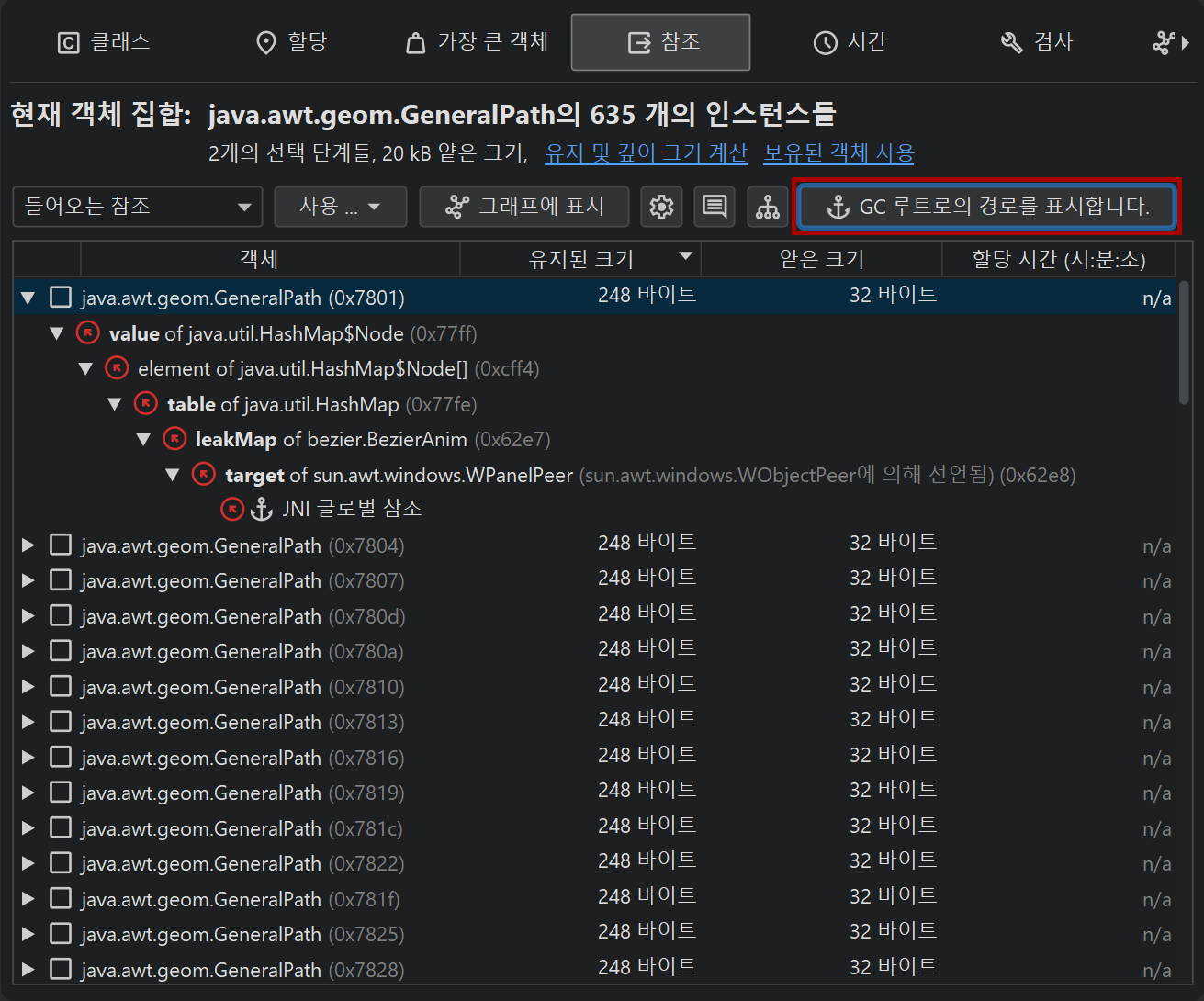
인커밍 참조 뷰는 메모리 누수 해결의 주요 도구입니다. 객체가 가비지 컬렉션되지 않는 이유를 찾으려면, Show Paths To GC Root 버튼을 사용하여 가비지 컬렉터 루트로의 참조 체인을 찾을 수 있습니다. 메모리 누수 챕터에서 이 중요한 주제에 대해 자세히 설명합니다.
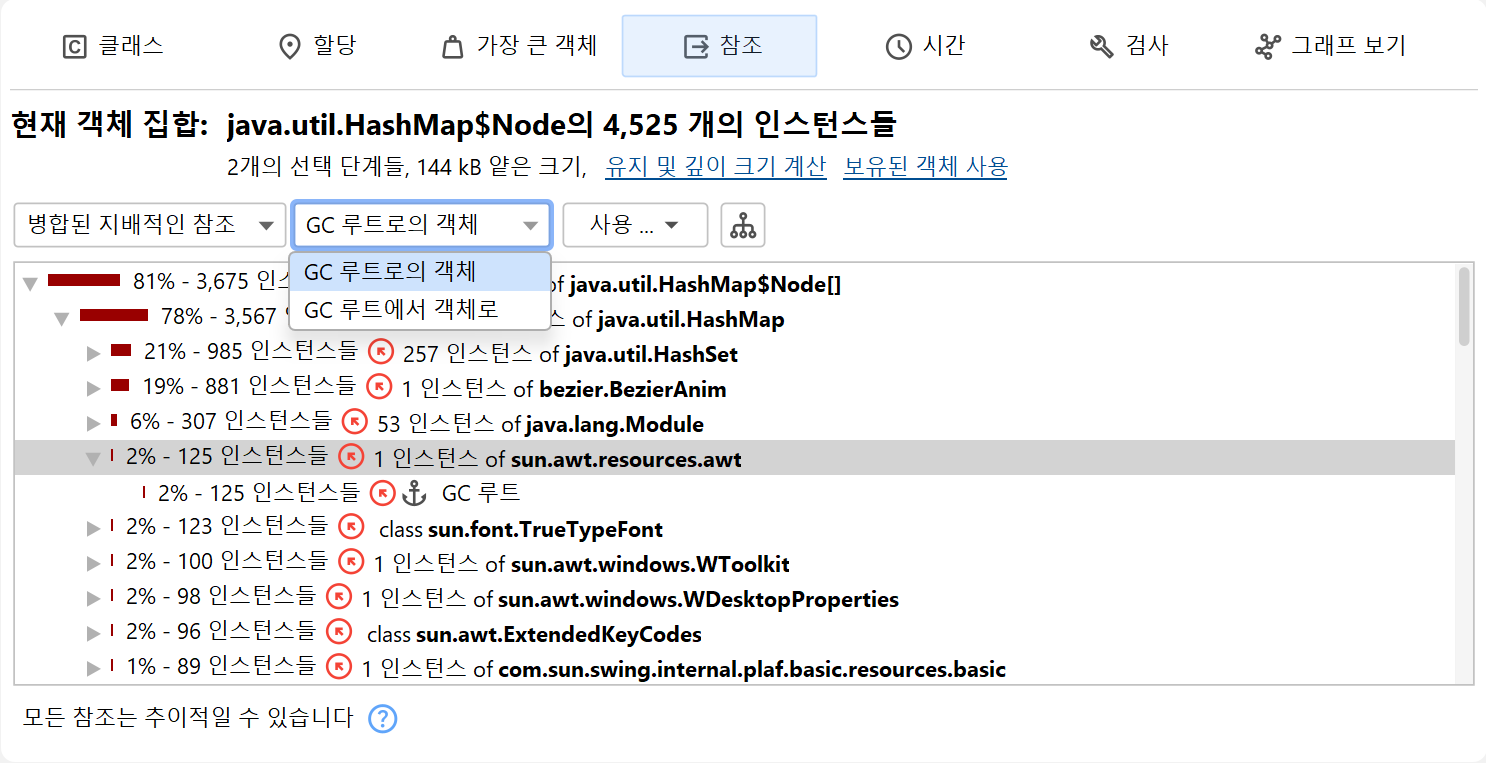
병합 참조
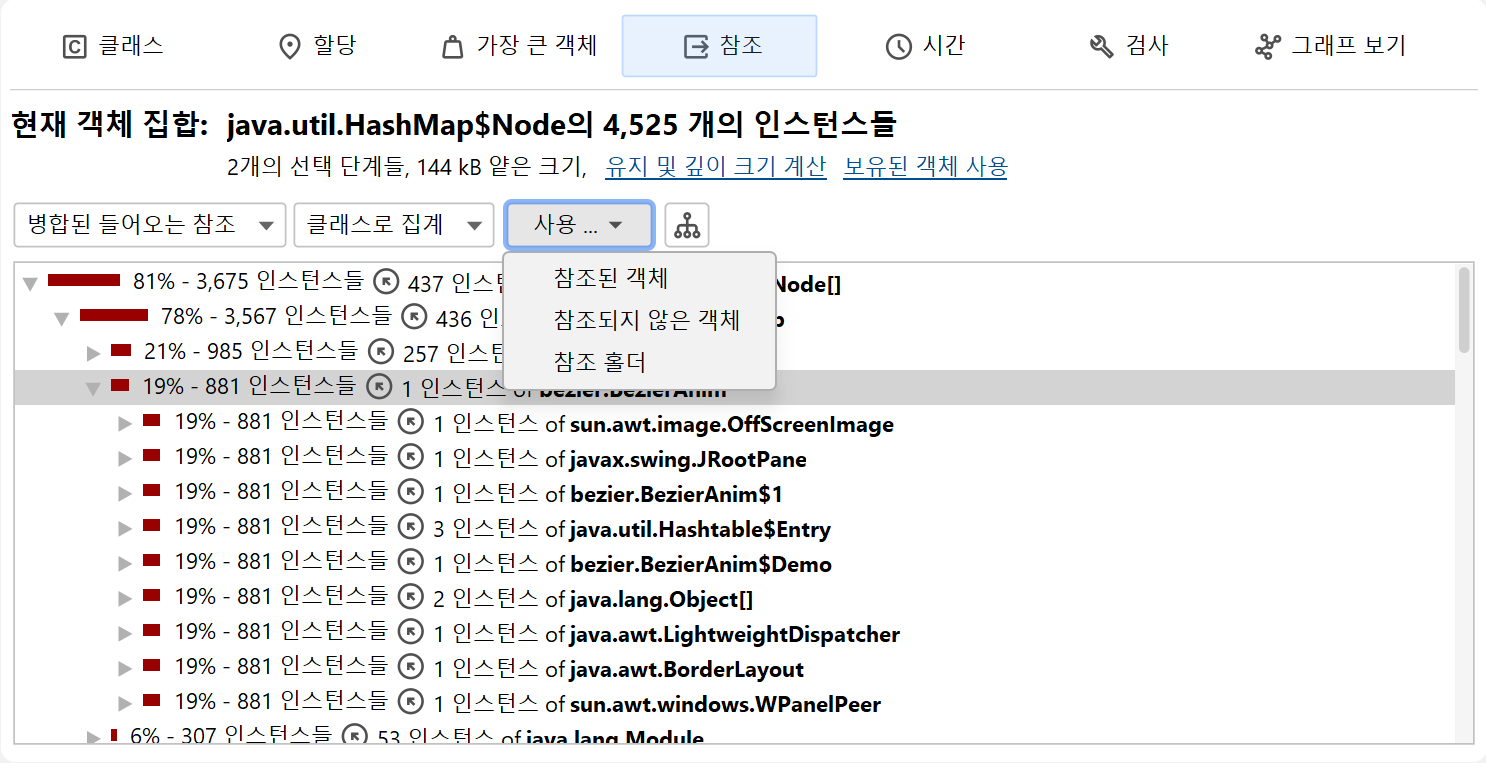
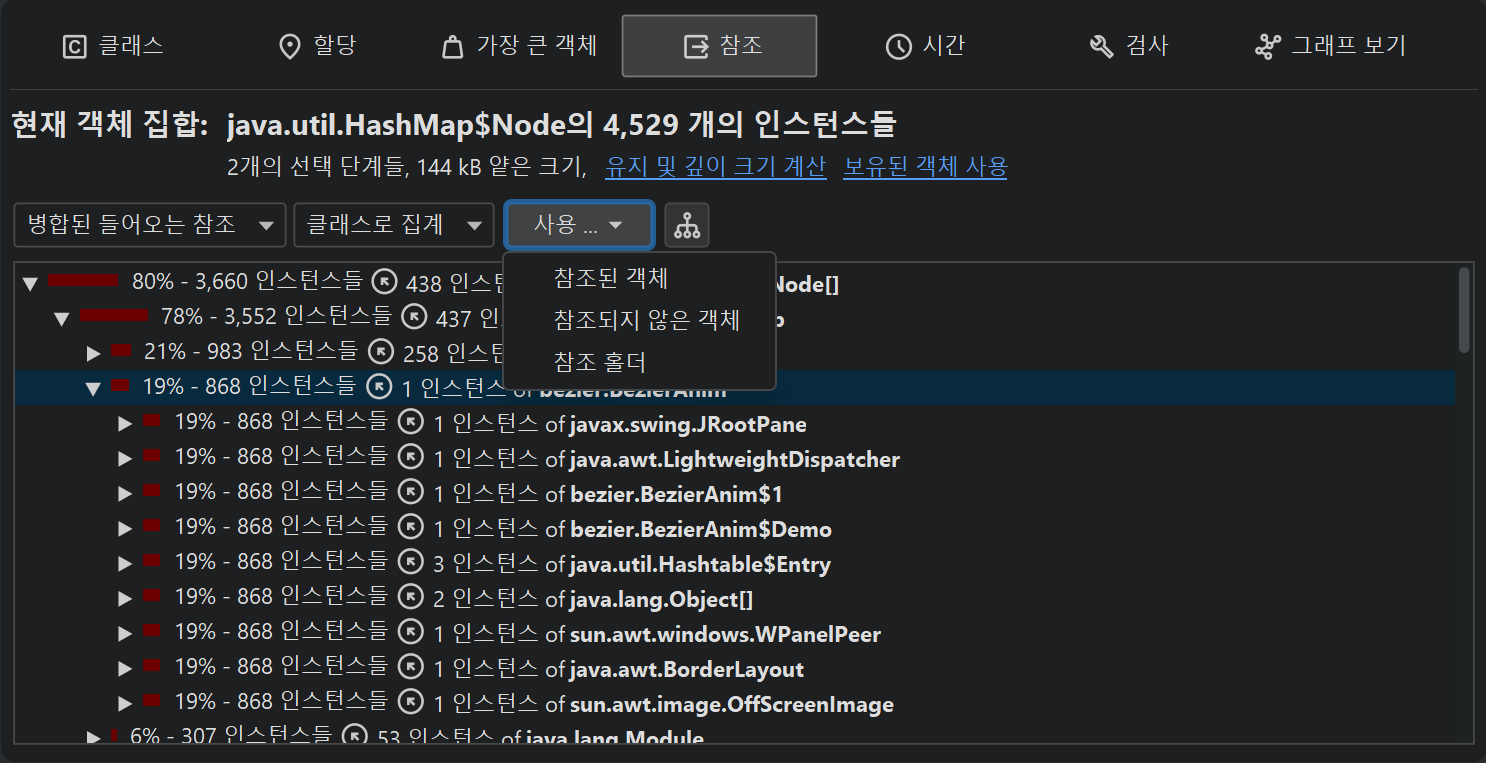
다양한 객체의 참조를 하나씩 확인하는 것은 번거로울 수 있으므로, JProfiler는 현재 객체 집합의 모든 객체에 대한 병합된 아웃고잉 및 인커밍 참조를 보여줄 수 있습니다. 기본적으로 참조는 클래스별로 집계됩니다. 클래스 인스턴스가 동일 클래스의 다른 인스턴스에 의해 참조되는 경우, 특별한 노드가 삽입되어 원래 인스턴스와 이러한 클래스-재귀 참조의 인스턴스를 함께 보여줍니다. 이 메커니즘은 링크드 리스트와 같은 일반적인 데이터 구조의 내부 참조 체인을 자동으로 축소합니다.
병합 참조를 필드별로 그룹화하여 표시할 수도 있습니다. 이 경우 각 노드는 특정 클래스의 필드나 배열의 내용과 같은 참조 타입이 됩니다. 표준 컬렉션의 경우, 누적을 방해하는 내부 참조 체인은 압축되어 "java.lang.HashMap의 map value"와 같은 참조 타입이 표시됩니다. 클래스 집계와 달리, 이 메커니즘은 JRE 표준 라이브러리에서 명시적으로 지원되는 컬렉션에만 적용됩니다.
"병합 아웃고잉 참조" 뷰에서는 인스턴스 수가 참조된 객체를 의미합니다. "병합 인커밍 참조" 뷰에서는 각 행에 두 개의 인스턴스 수가 표시됩니다. 첫 번째 인스턴스 수는 현재 객체 집합에서 해당 경로를 따라 참조되는 인스턴스 수를 나타냅니다. 노드 왼쪽의 바 아이콘은 이 비율을 시각화합니다. 화살표 아이콘 뒤의 두 번째 인스턴스 수는 상위 노드를 참조하는 객체 수를 의미합니다. 선택 단계를 수행할 때, 현재 객체 집합에서 선택된 방식으로 참조되는 객체를 선택할지, 선택된 참조(참조 보유자)에 관심이 있는지 선택할 수 있습니다.
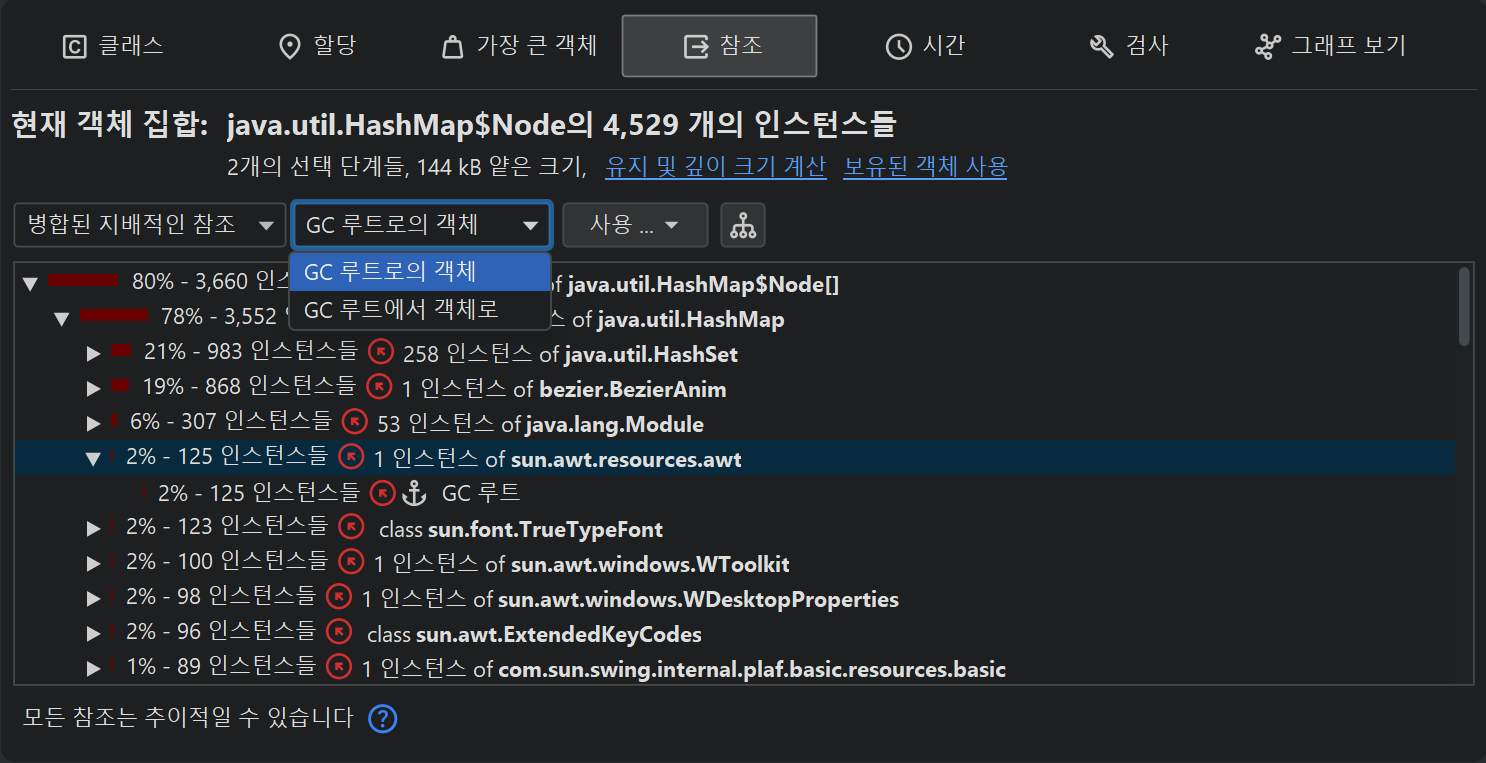
"병합 도미네이팅 참조" 뷰를 사용하면, 현재 객체 집합의 일부 또는 전체 객체가 가비지 컬렉션되기 위해 제거해야 하는 참조를 찾을 수 있습니다. 도미네이팅 참조 트리는 가장 큰 객체 뷰의 도미네이터 트리의 병합된 역방향(클래스별 집계)으로 해석할 수 있습니다. 참조 화살표는 두 클래스 간의 직접 참조를 나타내지 않을 수 있으며, 그 사이에 비도미네이팅 참조를 가진 다른 클래스가 있을 수 있습니다. 여러 가비지 컬렉터 루트가 있는 경우, 현재 객체 집합의 일부 또는 전체 객체에 대해 도미네이팅 참조가 존재하지 않을 수 있습니다.
기본적으로 "병합 도미네이팅 참조" 뷰는 인커밍 도미네이팅 참조를 보여주며, 트리를 확장하면 GC 루트가 보유한 객체에 도달할 수 있습니다. 때로는 참조 트리가 여러 경로를 따라 동일한 루트 객체로 이어질 수 있습니다. 뷰 상단의 드롭다운에서 "GC roots to objects" 뷰 모드를 선택하면, 루트가 최상위에 있고 현재 객체 집합의 객체가 리프 노드에 있는 역방향 관점을 볼 수 있습니다. 이 경우 참조는 최상위에서 리프 노드로 향합니다. 어떤 관점이 더 나은지는 제거하려는 참조가 현재 객체 집합에 가까운지, GC 루트에 가까운지에 따라 다릅니다.
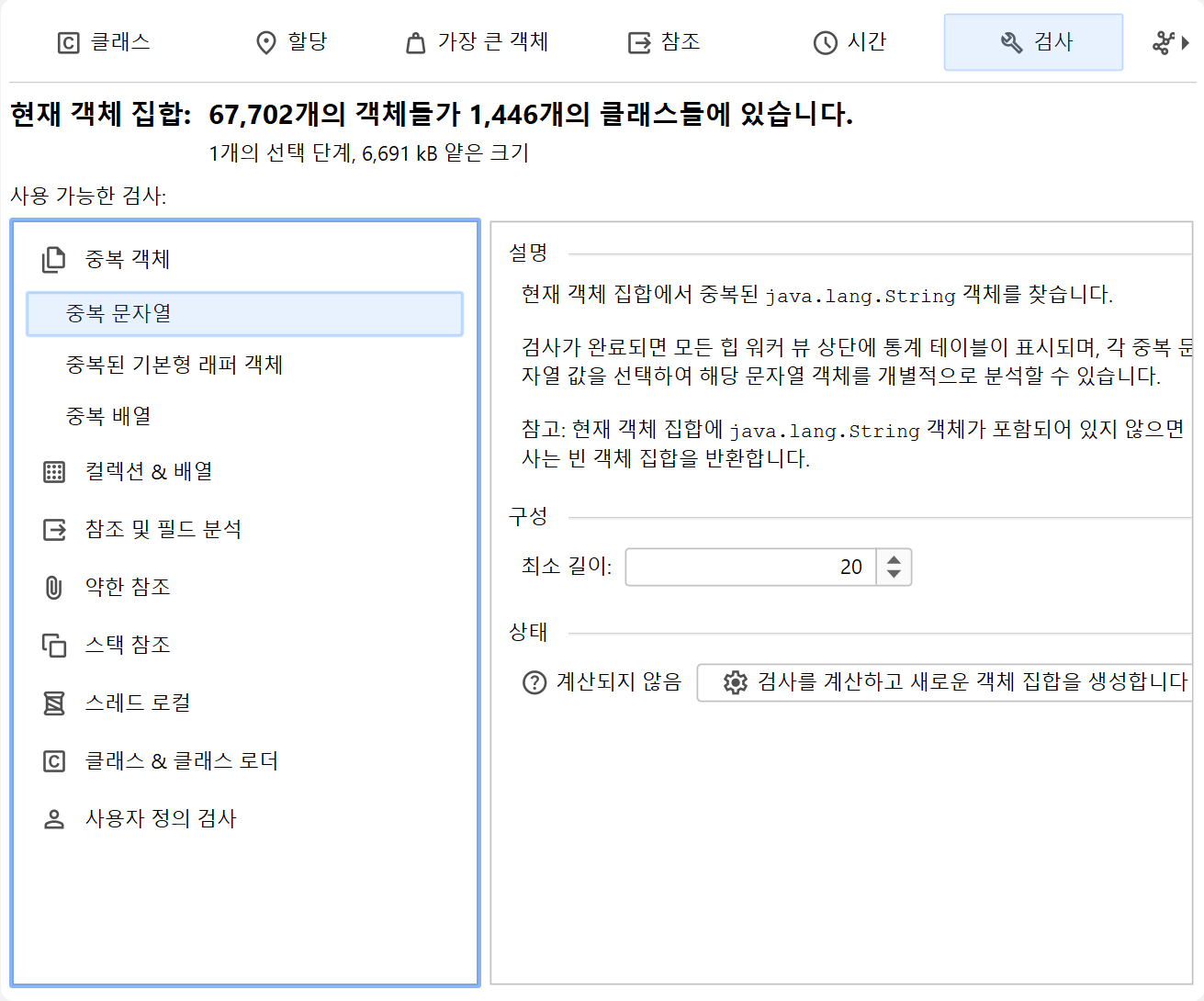
인스펙션
"Inspections" 뷰는 자체적으로 데이터를 표시하지 않습니다. 다른 뷰에서 사용할 수 없는 규칙에 따라 새로운 객체 집합을 생성하는 여러 힙 분석을 제공합니다. 예를 들어, thread local에 의해 유지되는 모든 객체를 보고 싶을 수 있습니다. 이는 참조 뷰에서는 불가능합니다. 인스펙션은 여러 카테고리로 그룹화되어 있으며, 설명에서 자세히 안내됩니다.
인스펙션은 계산된 객체 집합을 그룹으로 분할할 수 있습니다. 그룹은 힙 워커 상단의 테이블에 표시됩니다.
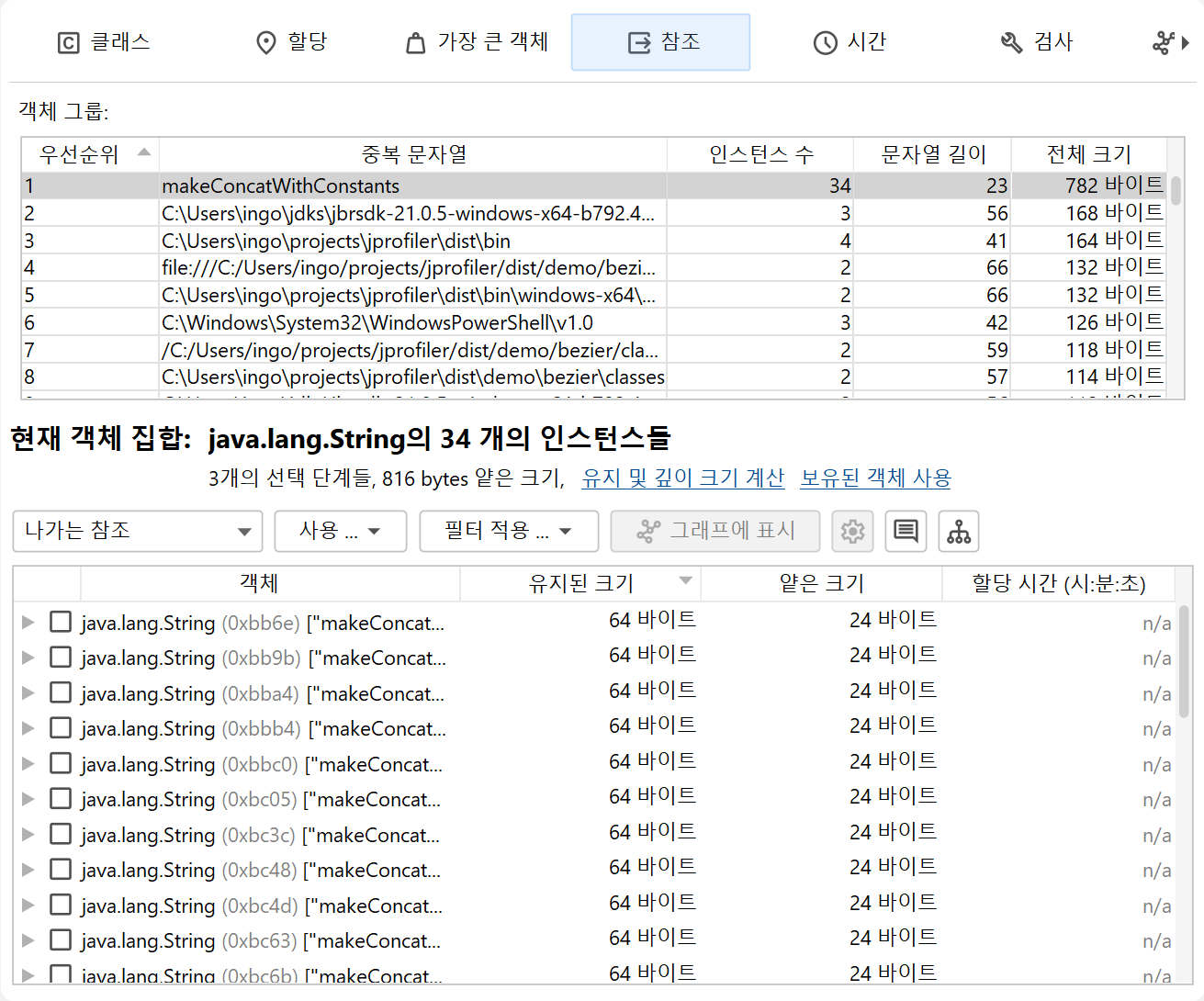
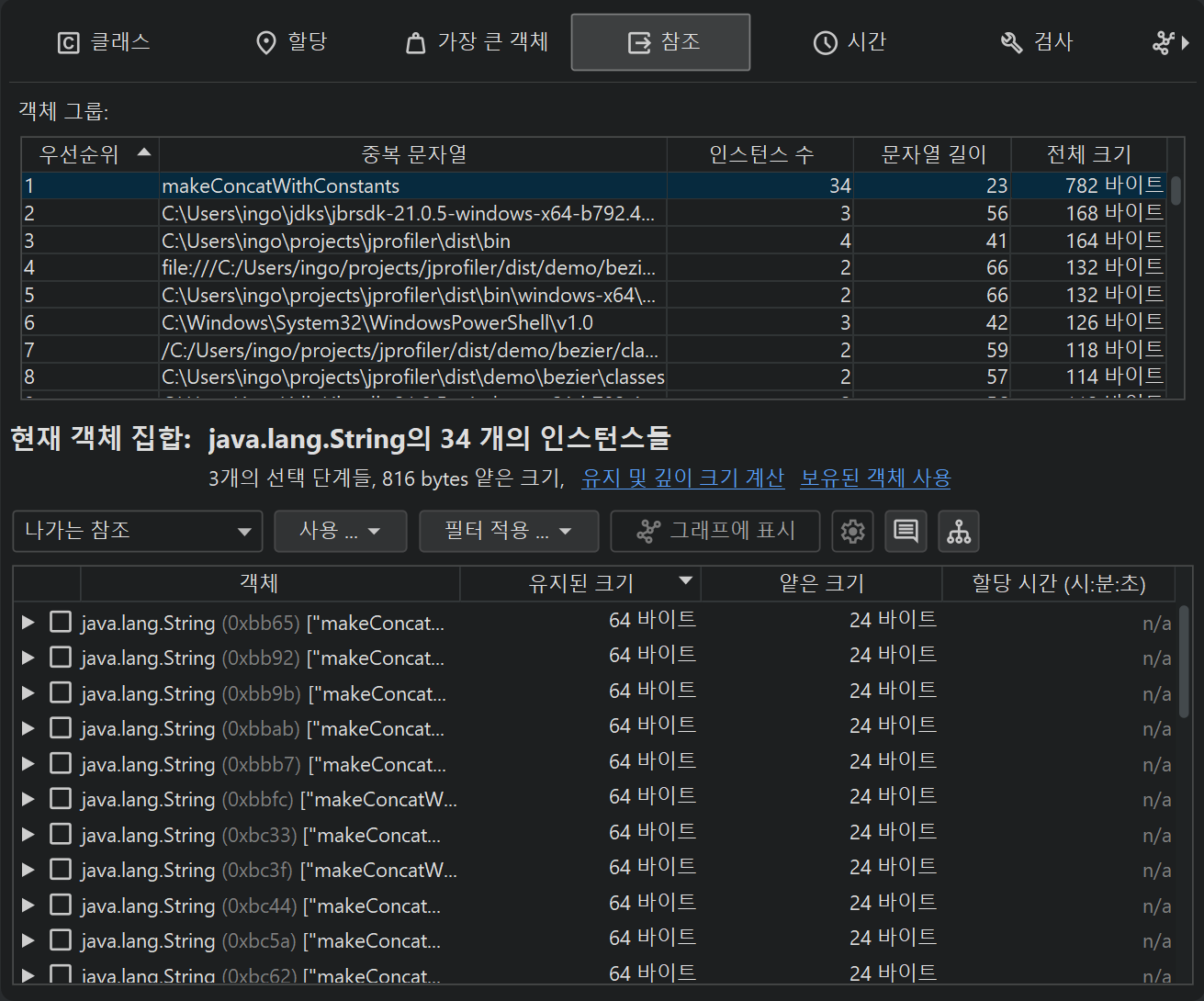
예를 들어, "중복 문자열" 인스펙션은 중복된 문자열 값을 그룹으로 보여줍니다.
참조 뷰에 있는 경우, 선택된 문자열 값의 java.lang.String 인스턴스를 아래에서 볼 수 있습니다.
처음에는 그룹 테이블의 첫 번째 행이 선택됩니다. 선택을 변경하면 현재 객체 집합이 바뀝니다.
그룹 테이블의 Instance Count 및 Size 컬럼은 행을 선택할 때 현재 객체 집합의 크기를 알려줍니다.
그룹 선택은 힙 워커의 별도 선택 단계가 아니며, 인스펙션에서 수행된 선택 단계의 일부가 됩니다. 그룹 선택은 하단의 선택 단계 패널에서 확인할 수 있습니다. 그룹 선택을 변경하면 선택 단계 패널이 즉시 업데이트됩니다.
그룹을 생성하는 각 인스펙션은 해당 인스펙션 맥락에서 가장 중요한 그룹을 결정합니다. 이는 항상 다른 컬럼의 자연스러운 정렬 순서와 일치하지 않을 수 있으므로, 그룹 테이블의 Priority 컬럼에는 인스펙션을 위한 정렬 순서를 강제하는 숫자 값이 포함됩니다.
인스펙션은 대형 힙의 경우 계산 비용이 많이 들 수 있으므로, 결과가 캐시됩니다. 이를 통해 이전에 계산된 인스펙션 결과를 기다림 없이 히스토리에서 다시 볼 수 있습니다.
힙 워커 그래프
인스턴스와 그 참조를 함께 가장 현실적으로 표현하는 방식은 그래프입니다. 그래프는 시각적 밀도가 낮고 일부 분석 유형에는 비실용적일 수 있지만, 객체 간의 관계를 시각화하는 데는 최적입니다. 예를 들어, 순환 참조는 트리에서는 해석하기 어렵지만, 그래프에서는 즉시 파악할 수 있습니다. 또한, 트리 구조에서는 인커밍 또는 아웃고잉 참조 중 하나만 볼 수 있지만, 그래프에서는 둘 다 함께 볼 수 있습니다.
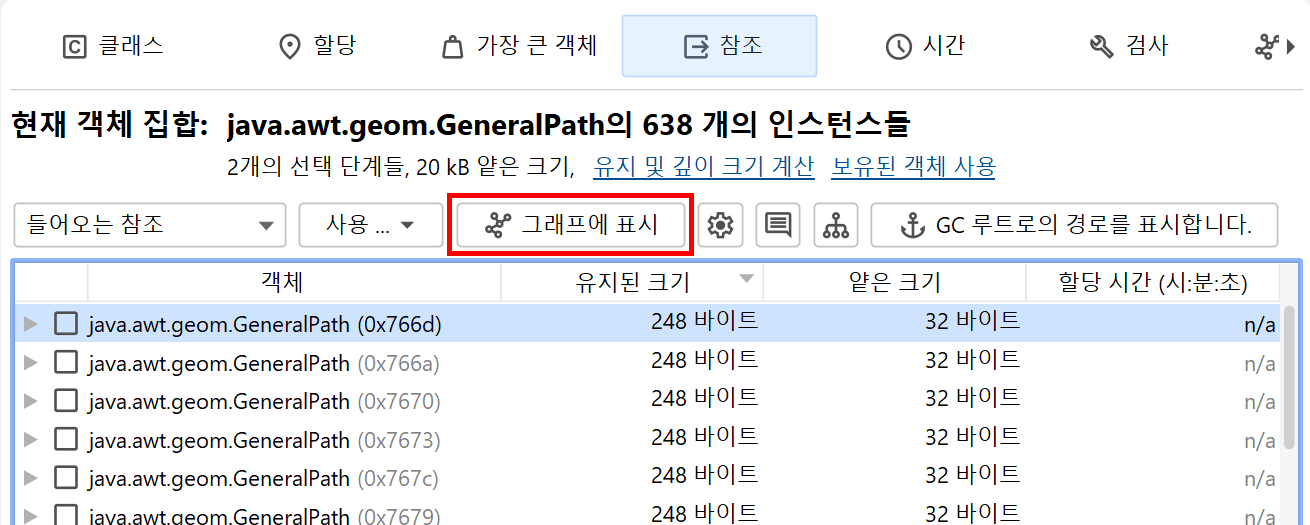
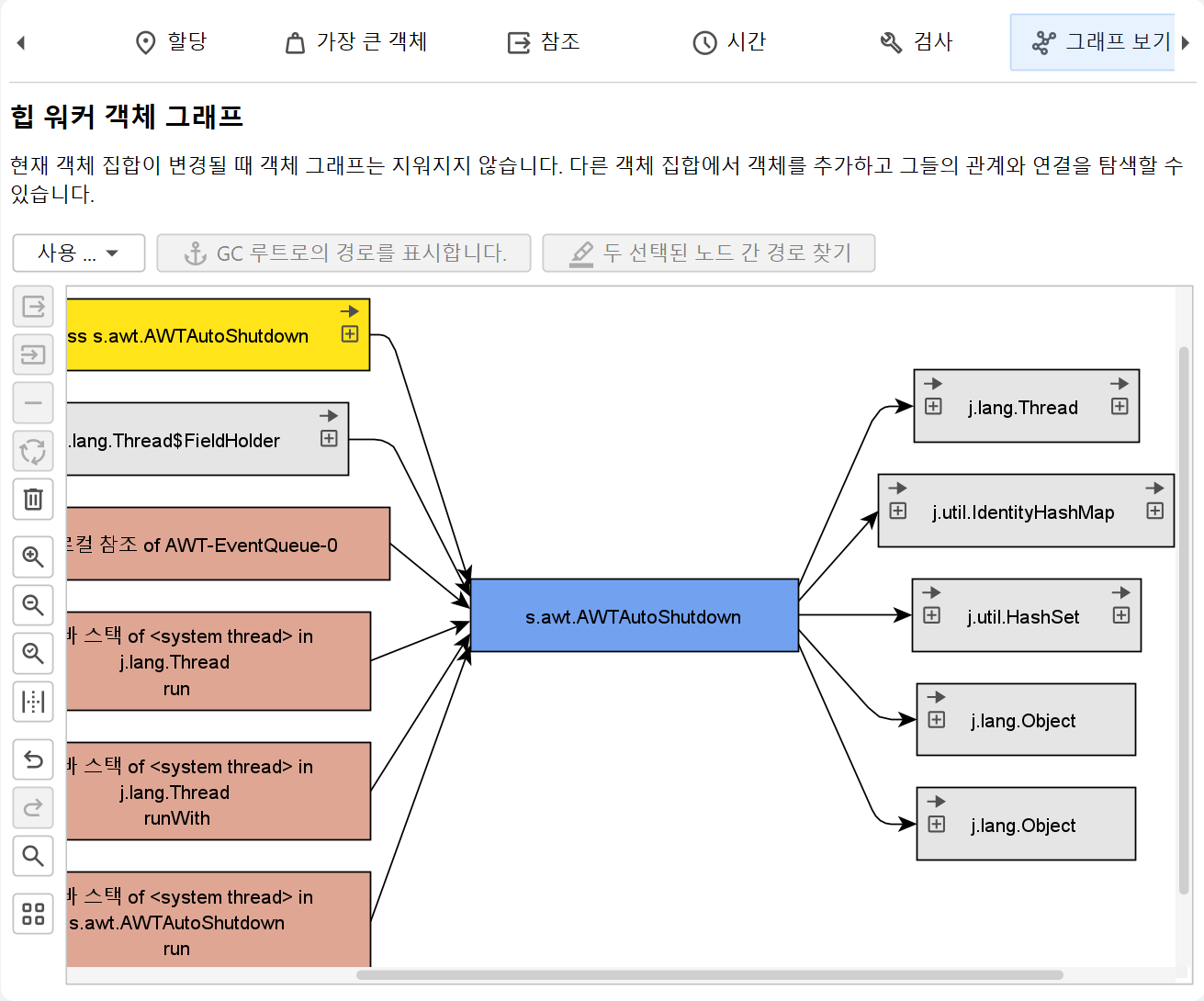
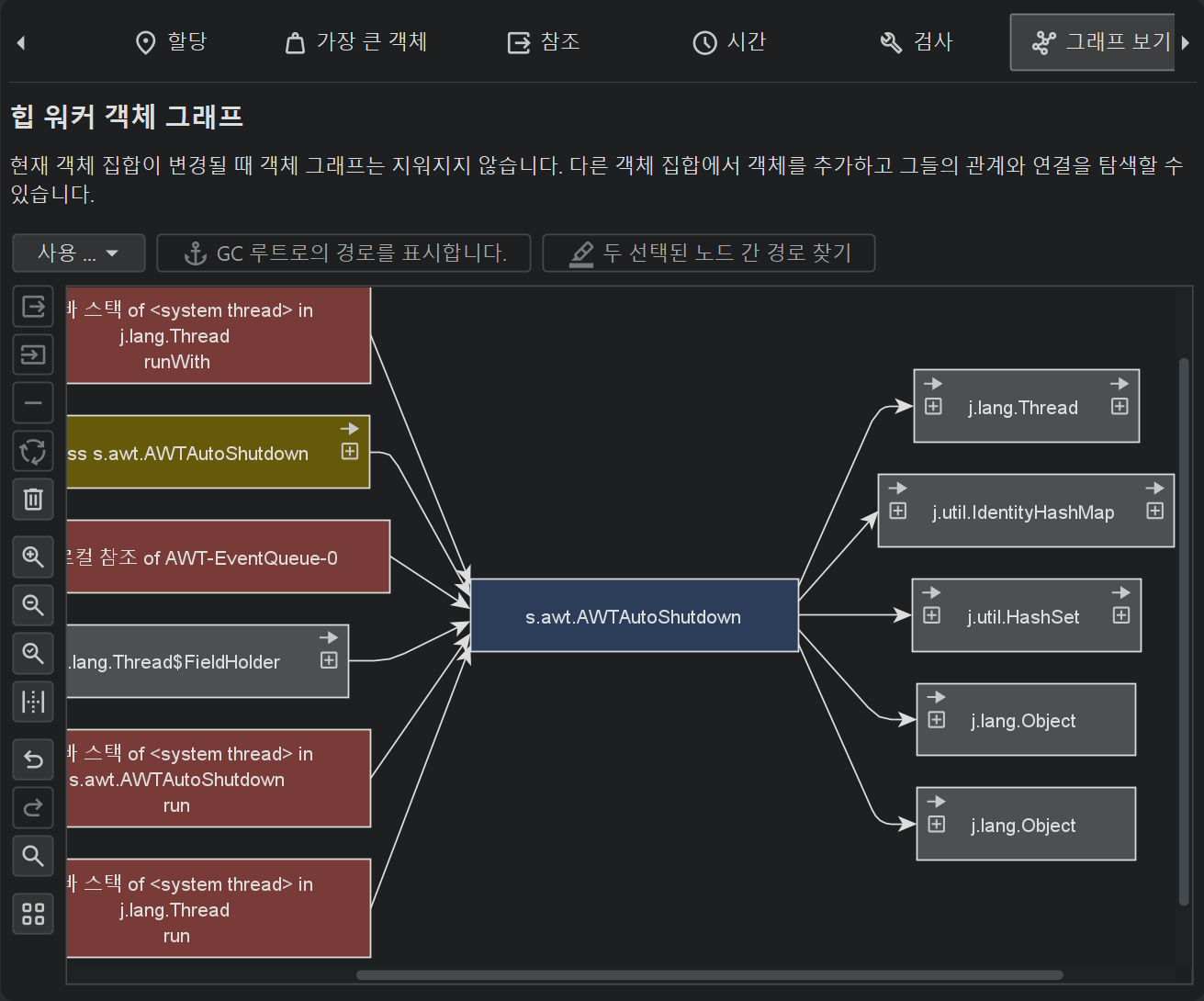
힙 워커 그래프는 현재 객체 집합의 객체를 자동으로 표시하지 않으며, 객체 집합이 변경되어도 그래프가 지워지지 않습니다. 아웃고잉 참조 뷰, 인커밍 참조 뷰, 가장 큰 객체 뷰에서 하나 이상의 인스턴스를 선택하고 Show In Graph 동작을 사용하여 그래프에 수동으로 추가해야 합니다.
그래프의 패키지명은 기본적으로 축약되어 표시됩니다. CPU 호출 그래프와 마찬가지로, 뷰 설정에서 전체 표시를 활성화할 수 있습니다. 참조는 화살표로 그려집니다. 참조 위에 마우스를 올리면 해당 참조에 대한 세부 정보를 보여주는 툴팁 창이 표시됩니다. 참조 뷰에서 수동으로 추가된 인스턴스는 파란색 배경을 가지며, 최근에 추가된 인스턴스일수록 배경색이 더 진해집니다. 가비지 컬렉터 루트는 빨간색 배경, 클래스는 노란색 배경을 가집니다.
기본적으로 참조 그래프는 현재 인스턴스의 직접 인커밍 및 아웃고잉 참조만 표시합니다. 객체를 더블 클릭하면 그래프가 확장됩니다. 이때 이동 방향에 따라 해당 객체의 직접 인커밍 또는 직접 아웃고잉 참조가 확장됩니다. 인스턴스의 좌우 확장 컨트롤을 사용하면 인커밍 및 아웃고잉 참조를 선택적으로 열 수 있습니다. 되돌아가야 할 경우, undo 기능을 사용하여 그래프의 이전 상태를 복원할 수 있으므로, 너무 많은 노드로 인해 혼란스러워지지 않습니다. 그래프를 다듬기 위해 연결되지 않은 모든 노드 또는 모든 객체를 제거하는 동작도 있습니다.
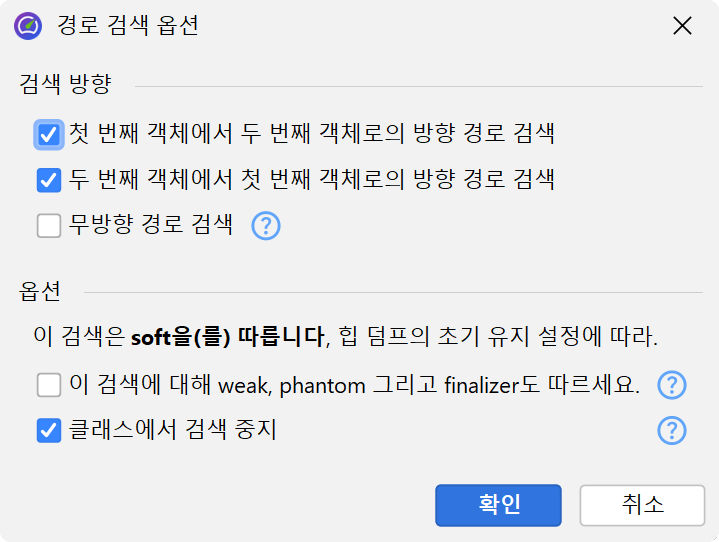
인커밍 참조 뷰와 마찬가지로, 그래프에는 Show Path To GC Root 버튼이 있어 가비지 컬렉터 루트로의 참조 체인을 하나 이상 확장할 수 있습니다(가능한 경우). 또한, 두 인스턴스가 선택된 경우 활성화되는 Find Path Between Two Selected Nodes 동작이 있습니다. 이는 방향성 및 비방향성 경로, 그리고 약한 참조를 따라 경로를 검색할 수 있습니다. 적합한 경로가 발견되면 빨간색으로 표시됩니다.
초기 객체 집합
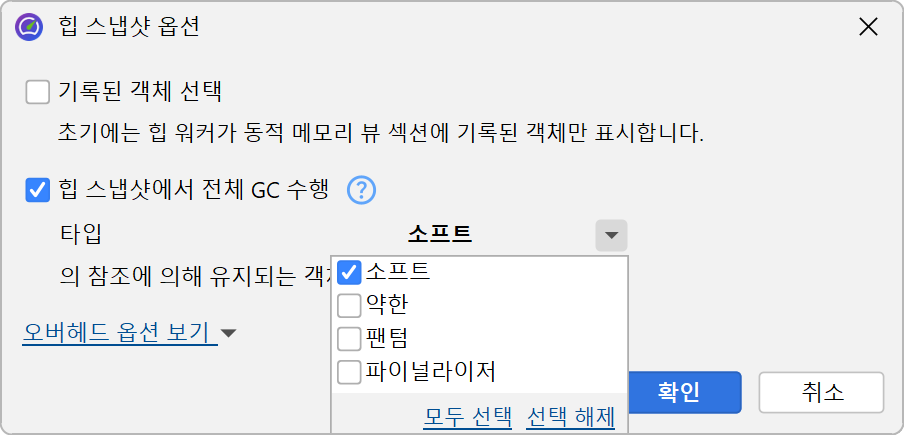
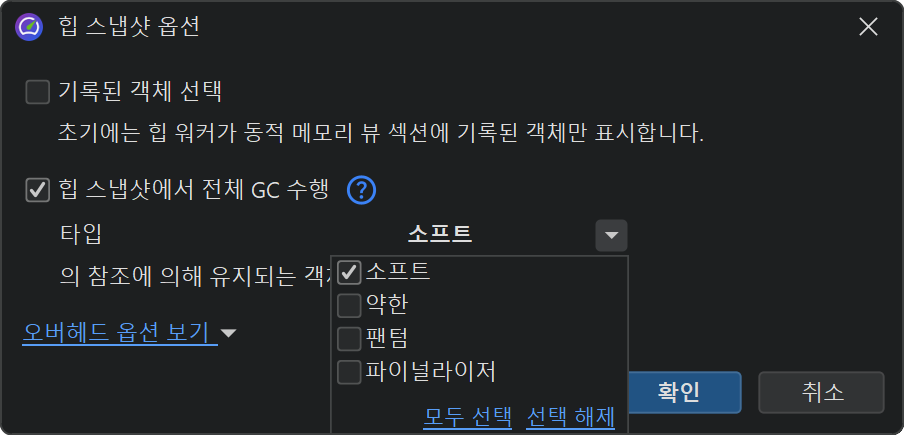
힙 스냅샷을 찍을 때, 초기 객체 집합을 제어하는 옵션을 지정할 수 있습니다. 할당이 녹화된 경우, 녹화된 객체 선택 체크박스는 처음 표시되는 객체를 녹화된 객체로 제한합니다. 숫자는 일반적으로 라이브 메모리 뷰와 다르며, 힙 워커가 참조되지 않은 객체를 제거하기 때문입니다. 녹화되지 않은 객체도 힙 스냅샷에는 존재하지만, 초기 객체 집합에는 표시되지 않습니다. 추가 선택 단계를 통해 녹화되지 않은 객체에도 접근할 수 있습니다.
또한, 힙 워커는 가비지 컬렉션을 수행하고, 소프트 참조를 제외한 약한 참조 객체를 제거합니다. 이는 약한 참조 객체가 메모리 누수 분석에서 주로 강한 참조 객체만이 관련되므로, 산만함을 줄이기 위해 일반적으로 바람직합니다. 그러나 약한 참조 객체에 관심이 있는 경우, 힙 워커에 해당 객체를 유지하도록 지정할 수 있습니다. JVM의 네 가지 약한 참조 타입은 "soft", "weak", "phantom", "finalizer"이며, 이 중 어떤 타입이 객체를 힙 스냅샷에 유지하는 데 충분한지 선택할 수 있습니다.
약한 참조 객체가 존재하는 경우, 힙 워커의 "약한 참조" 인스펙션을 사용하여 현재 객체 집합에서 선택하거나 제거할 수 있습니다.
힙 마킹
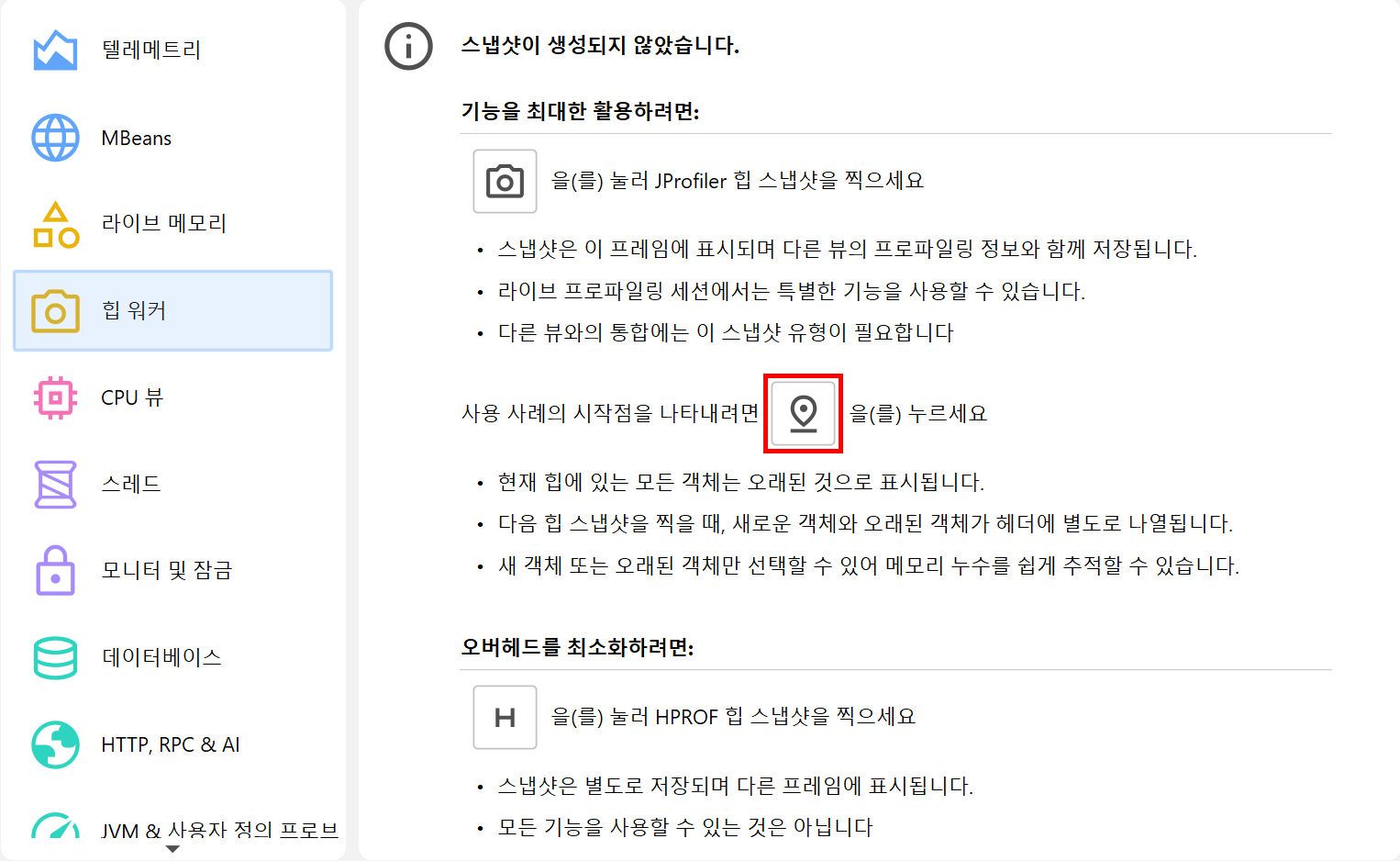
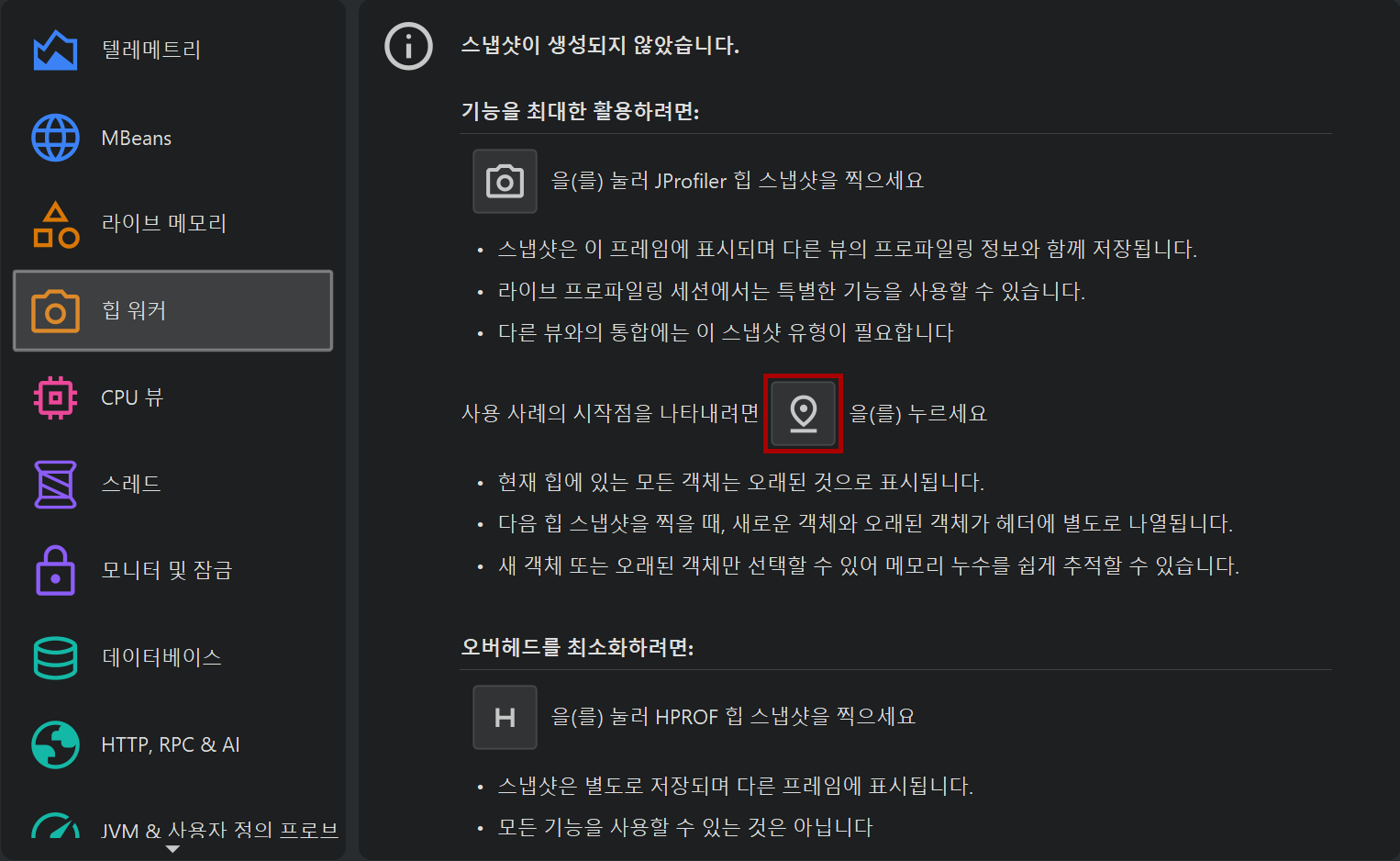
특정 사용 사례를 위해 할당된 객체를 보고 싶은 경우가 많습니다. 할당 녹화를 해당 사용 사례 전후로 시작/중지하는 방법도 있지만, 오버헤드가 훨씬 적고, 할당 녹화 기능을 다른 용도로도 보존할 수 있는 훨씬 더 좋은 방법이 있습니다. 바로 힙 워커 개요에서 안내되고, Profiling 메뉴 또는 트리거 동작으로도 사용할 수 있는 Mark Heap 동작입니다. 이 동작은 힙의 모든 객체를 "old"로 마킹합니다. 이후 힙 스냅샷을 찍으면 "new" 객체가 무엇인지 명확해집니다.
이전 힙 스냅샷이나 마크 힙 호출이 있었다면, 힙 워커의 타이틀 영역에 새로운 인스턴스 수와 Use new, Use old라는 두 개의 링크가 표시되어, 해당 시점 이후에 할당된 인스턴스 또는 그 전에 할당되어 살아남은 인스턴스를 선택할 수 있습니다. 이 정보는 각 객체 집합에 대해 제공되므로, 먼저 드릴다운한 후 나중에 new 또는 old 인스턴스를 선택할 수 있습니다.